

はじめに
AIを活用して研究や情報収集の効率を飛躍的に高める可能性を秘めたオープンソースフレームワーク「DeerFlow」。本マニュアルでは、Windows 11環境でDeerFlowをセットアップし、特にWebユーザーインターフェース(Web UI)を中心に、GoogleのGemini APIを利用する方法の設定までをステップ・バイ・ステップで詳しく解説します。
プログラミングや環境構築に少し慣れているWindows 11ユーザーの方を対象に、具体的なコマンドプロンプト/PowerShellでの操作や設定ファイルのポイントを丁寧に説明していきます。
DeerFlowのより全体的な概要や主要機能について知りたい方は、別途公開されている「【無料】リサーチ自動化の決定版?「DeerFlow」完全ガイド:情報収集からレポート・ポッドキャスト生成まで」の記事も合わせてご覧ください。
さあ、あなたのWindows 11マシンにDeerFlowを導入し、AI研究環境を構築しましょう!
1. 導入前の最終チェックリスト:Windows 11環境の準備
DeerFlowをスムーズに導入するために、まずは以下の技術要件と推奨ツールがあなたのWindows 11環境に整っているかを確認しましょう。
-
Python:
-
バージョン3.12以上が必須です。コマンドプロンプトまたはPowerShellで
python --versionと入力して確認してください。 - インストールされていない、またはバージョンが古い場合は、Python公式サイトからWindowsインストーラーをダウンロードしてインストールしてください。インストール時には「Add Python to PATH」にチェックを入れることを推奨します。
-
バージョン3.12以上が必須です。コマンドプロンプトまたはPowerShellで
- Visual Studio Build Tools
- C++拡張を含むパッケージ(curl_cffi)のビルドに必要
- Visual Studio Build Toolsからダウンロード
- インストール時に「C++によるデスクトップ開発」ワークロードを選択
-
Node.js (Web UIを利用する場合):
-
DeerFlowのグラフィカルなWeb UIを利用するためには、Node.js バージョン22以上が必須です。コマンドプロンプトまたはPowerShellで
node --versionと入力して確認します。 - インストールされていない場合は、Node.js公式サイトからWindowsインストーラー(LTS版または最新版)をダウンロードしてインストールしてください。
-
Node.jsのバージョン管理には
nvm-windowsの利用も便利です。
-
DeerFlowのグラフィカルなWeb UIを利用するためには、Node.js バージョン22以上が必須です。コマンドプロンプトまたはPowerShellで
-
Git:
-
DeerFlowのソースコードをGitHubからダウンロードするために必要です。コマンドプロンプトまたはPowerShellで
git --versionと入力して確認してください。 - 未インストールの場合は、Git for Windows公式サイトからダウンロードしてインストールしてください。
-
DeerFlowのソースコードをGitHubからダウンロードするために必要です。コマンドプロンプトまたはPowerShellで
-
推奨されるパッケージ管理ツール:
-
Python用:
uv(pipとvenvの代替となる高速なパッケージインストーラー)。必須ではありませんが、DeerFlowのドキュメントで推奨されており、本ガイドでもuvを使用します。コマンドプロンプトまたはPowerShellでpip install uvまたはpython -m pip install uvでインストールできます。 -
Node.js用 (Web UI利用時):
pnpm(performant npm)。こちらも必須ではありませんが、高速で効率的なパッケージ管理が可能です。Node.jsインストール後、コマンドプロンプトまたはPowerShellでnpm install -g pnpmでインストールできます。
-
Python用:
-
APIキー (必要な場合):
-
DeerFlowが連携する外部サービスを利用する場合、それぞれのAPIキーが必要になります。事前に取得しておきましょう。
-
LLM:
- Gemini APIキー: Google AI Studioで取得できます。
- OpenAI APIキー (GPTシリーズを利用する場合)
-
検索エンジン:
- Tavily Search APIキー(おすすめ)
- Brave Search APIキー
- (DuckDuckGo、ArxivはAPIキーなしで利用可能)
-
TTS (テキスト読み上げ):
- VolcEngine TTS APIキー: VolcEngineのコンソールから取得(通常、Access Key ID, Secret Access Key, App IDなど)。
-
LLM:
-
DeerFlowが連携する外部サービスを利用する場合、それぞれのAPIキーが必要になります。事前に取得しておきましょう。
-
基本的なコマンドライン操作の知識:
-
コマンドプロンプトまたはPowerShellでのディレクトリ移動 (
cd)、コマンド実行などの基本的な操作に慣れていることが望ましいです。
-
コマンドプロンプトまたはPowerShellでのディレクトリ移動 (
- (推奨) Windows Terminal: 複数のシェル(コマンドプロンプト, PowerShell, Git Bashなど)をタブで管理できるため便利です。Microsoft Storeからインストールできます。
すべての準備が整ったら、いよいよインストール作業に進みましょう。
2. DeerFlowインストール:Windows 11ステップガイド
ここでは、DeerFlowの本体とWeb UIをWindows 11にインストールする手順を解説します。
ステップ1: DeerFlowのソースコードをダウンロード
まず、DeerFlowの公式GitHubリポジトリからソースコード一式をローカル環境にクローンします。 コマンドプロンプトまたはPowerShellを開き、作業したいディレクトリ(例: C:\Users\YourUser\Projects)に移動してから以下のコマンドを実行してください。
git clone https://github.com/bytedance/deer-flow.git
cd deer-flow
これで、カレントディレクトリに deer-flow というフォルダが作成され、その中に移動した状態になります。以降の作業は、基本的にこの deer-flow フォルダ内で行います。
ステップ2 : Python環境のセットアップと依存関係のインストール
DeerFlowではuvというパッケージマネージャーを使用することが推奨されています。まずuvをインストールします:
pip install uv次に、DeerFlowの依存関係をインストールします:
uv sync このコマンドはpyproject.tomlファイルに記載されている依存関係を自動的にインストールします。
ステップ3: 環境変数ファイル (.env) の設定
DeerFlowが外部のAPIサービスを利用するためには、APIキーなどの認証情報を設定する必要があります。これらの情報は、.env というファイルに記述します。
まず、テンプレートファイル .env.example をコピーして .env ファイルを作成します。 deer-flow フォルダのルートで以下のコマンドを実行してください。
copy .env.example .env
次に、作成された .env ファイルをお好みのテキストエディタ(VS Code、メモ帳など)で開きます。以下のような内容に編集します。
# 検索APIの設定
SEARCH_API=tavily
TAVILY_API_KEY=tvly-xxx # 実際のTavily APIキーに置き換え
-
各検索エンジンの特徴と使い分け:
-
Tavily (
tavily): おすすめ- 特徴: AIエージェント向けに最適化された検索APIです。単なるリンクのリストではなく、検索クエリに対して要約された情報や関連性の高い情報を直接返すことを得意とします。研究目的での情報収集や、特定の質問に対する回答を得たい場合に強力です。
- APIキー: 必要です。
-
利用シーン:
- 特定のトピックに関する深い情報を効率的に収集したい場合。
- 質問応答型のタスクで、LLMに与えるコンテキスト情報を充実させたい場合。
- 最新情報や網羅的な調査を行いたい場合。
-
Brave Search (
brave_search):- 特徴: プライバシー保護を重視した検索エンジンで、独自の検索インデックスを持っています。GoogleやBingといった大手とは異なる検索結果を提供する可能性があります。ユーザーの追跡を行わないことをポリシーとしています。
- APIキー: 必要です。
-
利用シーン:
- プライバシーを重視したい場合。
- 大手検索エンジンとは異なる視点の情報を得たい場合。
- 一般的なウェブ検索を行いたいが、追跡を避けたい場合。
-
DuckDuckGo (
duckduckgo):- 特徴: こちらもプライバシー保護を重視した検索エンジンです。検索結果は、Bingなどの他の検索エンジンや独自のクローラーからの情報を集約して提供されます。ユーザーの検索履歴を保存せず、追跡も行いません。
- APIキー: 通常不要で手軽に利用できます(API経由での利用制限に注意)。
-
利用シーン:
- 手軽にプライバシーを保護しながら一般的なウェブ検索を行いたい場合。
- APIキーの設定なしですぐに検索機能を利用開始したい場合。
-
Arxiv (
arxiv):- 特徴: 物理学、数学、コンピュータサイエンス、経済学などの分野における学術論文のサーバーです。最新の研究動向を追うのに非常に重要です。
- APIキー: 通常不要ですが、大量のリクエストを行う場合はAPIの利用規約を確認してください。
-
利用シーン:
- 特定の学術分野における最新の研究論文を探したい場合。
- 研究テーマに関連する先行研究を調査したい場合。
- 論文の著者名、タイトル、キーワードなどで検索したい場合。
-
DeerFlowで
max_resultsのようなパラメータが利用可能であれば、一度に取得する論文数を調整できます(DeerFlowのArxivツール実装によります)。
-
Tavily (
使い分けのヒント:
- 一般的な情報収集でプライバシーを重視するなら: DuckDuckGo または Brave Search。
- AIによるリサーチや深い情報分析を求めるなら: Tavily。
- 学術的な研究や最新論文を探すなら: Arxiv。
設定が完了したら、conf.yaml ファイルをUTF-8エンコーディングで保存します。
ステップ4 : conf.yaml ファイルの設定
次に、DeerFlow自体の動作、使用するLLMモデルなどを定義するメインの設定ファイル 「conf.yaml」を準備します。 テンプレートファイル 「conf.yaml.example」 をコピーして 「conf.yaml」 を作成します。 「deer-flow」 フォルダのルートで以下のコマンドを実行してください。
copy conf.yaml.example conf.yaml
作成された 「conf.yaml 」ファイルをテキストエディタで開き、以下のように編集します:
# 基本モデル設定(Geminiの例)
BASIC_MODEL:
base_url: "https://generativelanguage.googleapis.com/v1beta/openai/"
model: "gemini-2.0-flash"
api_key: "YOUR_GEMINI_API_KEY" # 実際のGemini APIキーに置き換え テップ5: Web UIの依存関係インストール
グラフィカルなインターフェースでDeerFlowを操作するためのWeb UIをセットアップします。 まず、Web UIのソースコードが格納されている `web` ディレクトリに移動します。
cd web
次に、推奨されている pnpm を使って、Node.jsの依存関係をインストールします。
pnpm install
インストールが完了したら、一つ上の階層(deer-flow フォルダのルート)に戻っておきましょう。
cd ..3. DeerFlowの起動と初期動作確認 (Web UI中心)
インストールと設定が完了したら、いよいよDeerFlowを起動してみましょう。本マニュアルではWeb UIを中心にご紹介します。
3.1. Web UI (GUI) での起動と利用
Web UIを利用すると、ブラウザ上でグラフィカルにDeerFlowを操作できます。研究計画の確認・修正や、生成されたレポートの事後編集、TTSによる音声出力の指示などが直感的に行えます。
Web UIを起動するには、まずステップ3でWeb UIの依存関係がインストールされていることを確認してください。 次に、deer-flow フォルダのルート(例: C:\Users\YourUser\Projects\deer-flow)で、Windows用の起動スクリプトを実行します。PowerShellを使用している場合は、以下のように実行してください。
./bootstrap.bat -d
このスクリプトは、DeerFlowのバックエンドサーバー(Python/FastAPI)とフロントエンドサーバー(Node.js/Next.js)を同時に起動します。
お使いのウェブブラウザ(Chrome, Edge, Firefoxなど)を開き、アドレスバーに http://localhost:3000 と入力してアクセスしてください。
DeerFlowのWeb UIが表示されれば成功です!画面の指示に従って、新しいリサーチタスクを開始できます。
下図は、Web版DeerFlowを起動して、「最新のAIニュースを調べて」と頼んで、得られた最終画面までを3つのスクリーンショットで示したものです。
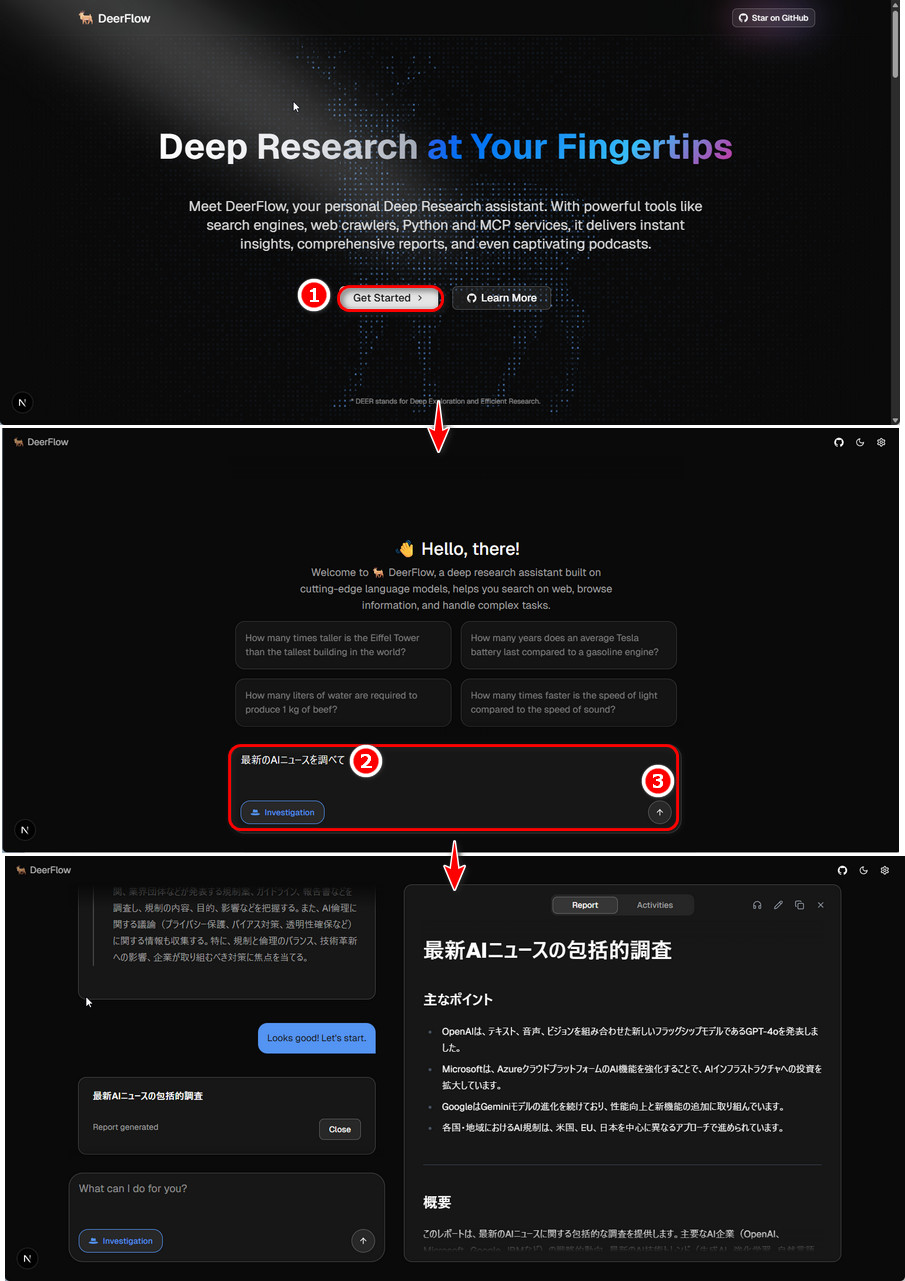
3.2. コンソールUI (CUI) での起動と利用 (参考)
CUIは、コマンドプロンプトまたはPowerShellから直接コマンドを入力してDeerFlowを操作する方法です。 deer-flow フォルダのルートで、以下のコマンドを実行します。
基本的な実行方法:
uv run main.py "あなたの研究テーマや質問をここに記述"
例: uv run main.py "Gemini 1.5 Proの最新情報について"
対話モードでの実行: ただし、この対話モードは、英語と中国語しか対応されていない。
uv run main.py --interactive4. 導入後のネクストステップと困ったときは(トラブルシューティング)
ここでは、私が遭遇した問題とその解決策を以下にまとめます。
4.1 依存関係の問題
問題: 必要なパッケージがインストールされていない
解決策: 以下のコマンドで個別にインストール
pip install fastapi jinja2 markdownify4.2 curl_cffiのビルドエラー
問題: Visual C++ビルドツールがないためにエラーが発生
解決策: Visual Studio Build Toolsをインストールするか、以下のコマンドでスキップ
pip install -e . --config-settings="--skip-build-dependencies=curl_cffi"4.3 tool_call_chunks属性エラー
問題: LangChainのAPIの変更による互換性の問題
解決策: src/server/app.pyファイルを修正
# 修正例
if hasattr(message_chunk, 'tool_call_chunks') and message_chunk.tool_call_chunks:
# AIMessage - Tool Call Chunks
event_stream_message["tool_call_chunks"] = message_chunk.tool_call_chunks
yield _make_event("tool_call_chunks", event_stream_message)4.4 ハイドレーションミスマッチエラー
問題: Next.jsのサーバーサイドレンダリングとクライアントサイドレンダリングの不一致
解決策: このエラーは無視しても機能に影響しないため、無視して問題ありません
おわりに
DeerFlowのWindows 11へのインストールは、適切な依存関係と設定ファイルを用意することで実現できます。
特に重要なのは:
- 必要なパッケージがすべてインストールされていること
- .envとconf.yamlの両方が正しく設定されていること
- Visual Studio Build Toolsがインストールされていること(またはcurl_cffiをスキップ)
- Tavilyを使用する場合は、有効なAPIキーを取得して設定すること
これらの手順に従い、.\bootstrap.bat -dコマンドで起動することで、DeerFlowを問題なく動作させることができるはずです。
DeerFlowは進化を続けるフレームワークです。ぜひ積極的に活用し、その可能性を探求してみてください。


コメント