

Fire-PDFのPodcast
下記のPodcastは、Geminiで作成しました。
はじめに
現代のデジタル情報社会において、PDF(Portable Document Format)は、OSやデバイスを問わず文書のレイアウトを維持できる標準的なフォーマットとして確固たる地位を築いています。しかし、その利便性の裏で、情報の抽出や再利用、あるいは大量の文書管理という面では、多くのユーザーやエンジニアが課題に直面してきました。こうした背景の中で、今まさに注目を集めているのが「Fire-PDF」というキーワードです。
「Fire-PDF」という名称は、文脈によっていくつかの異なる、しかし非常に強力なツールを指しています。一つは、Webスクレイピングの分野で革命を起こしているFirecrawl社の超高速Rust製解析エンジンであり、もう一つは、スマートフォンで直感的に文書を管理できるモバイルアプリケーションです。さらに、開発者向けにはPDFの内部構造に直接介入できる高度なライブラリも存在します。本レポートでは、これらの「Fire-PDF」に関連する多様な側面を網羅し、初心者がその利便性を享受するためのガイドから、専門家が技術的な優位性を理解するための詳細な分析までを、余すところなく解説します。
Fire-PDFがもたらすWebデータ抽出の革命:Firecrawlの視点
Web上に存在する膨大なPDFから情報を抽出することは、長らくデータサイエンスやWeb開発における「難所」とされてきました。従来のツールでは、テキストベースのPDFとスキャンされた画像ベースのPDFが混在する場合、一律に重い処理を課すか、あるいは精度を犠牲にするかの選択を迫られていたからです。Firecrawlが導入した新しいPDF解析エンジン「Fire-PDF」は、このトレードオフを根本から覆しました 。
高速化の核心:Rust言語とアーキテクチャの刷新
Fire-PDFの最大の特徴は、その圧倒的な処理速度にあります。以前のエンジンと比較して、解析スピードは3.5倍から最大5.7倍へと飛躍的に向上しました 。この驚異的なパフォーマンスを支えているのが、システムプログラミング言語「Rust」による再実装です。Rustはメモリ安全性と並行処理に優れており、大量のドキュメントを同時に、かつ極めて低いレイテンシで処理することを可能にします。平均的な処理時間は1ページあたり400ミリ秒未満という、従来の常識を覆す数値を叩き出しています 。
この高速化は、単にプログラムの実行速度が上がっただけではなく、インテリジェントな処理フローの構築によって実現されています。Fire-PDFは、ドキュメントの各ページを解析する際、まずそれがテキストベースなのか、それともOCR(光学文字認識)が必要なスキャン画像なのかを瞬時に判別します。
| 処理ステップ | 使用技術・ライブラリ | 目的と効果 |
| 分類(Classification) | pdf-inspector (Rust) | 数ミリ秒でテキスト/スキャンを判別し、GPU使用を最適化する |
| レンダリング(Rendering) | 高解像度レンダラー | OCRが必要なページのみを200 DPIで画像化する |
| レイアウト検出 | ニューラルレイアウトモデル | 表、数式、カラム構造を検出し、読解順序を予測する |
| 抽出(Extraction) | GLM-OCR / ネイティブ抽出 | テキストページは即座に、スキャンページはAIモデルで高精度に抽出する |
| 組み立て(Assembly) | Markdownジェネレーター | 構造化されたMarkdown形式に変換し、AIが利用しやすい形で出力する |
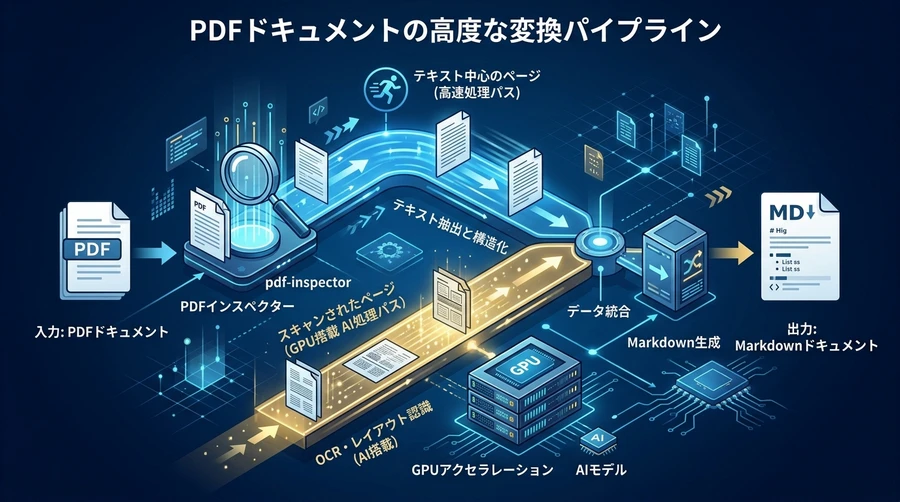
pdf-inspector:不要なコストを削減する知能
Fire-PDFの心臓部の一つである「pdf-inspector」は、オープンソースとして公開されているRustライブラリです 。このライブラリは、PDFのレンダリング(描画処理)を行う前に、内部のフォントエンコーディングやテキストオペレーター、画像カバレッジをスキャンします 。
これにより、全体の約54%を占めると言われる「OCRを必要としないテキストベースのページ」に対して、高価で時間のかかるGPUリソースの割り当てを回避できます 。例えば、210ページに及ぶ財務報告書のうち、150ページがテキスト、60ページがスキャンされた証憑である場合、Fire-PDFはテキストページをネイティブ抽出で瞬時に処理し、残りの60ページのみをAIモデルに送ります。この「スマートルーティング」こそが、コスト削減と速度向上の鍵となっています 。
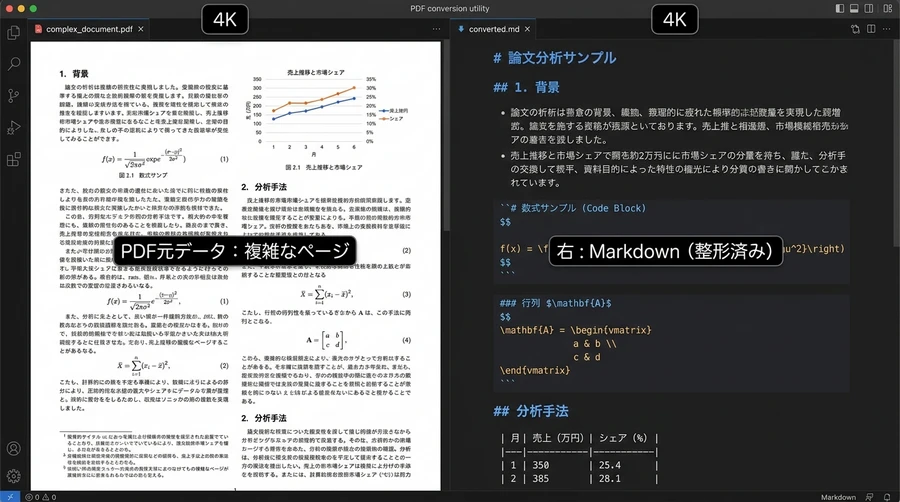
構造化データの頂点:MarkdownとLaTeXへの変換精度
PDFから単に文字を取り出すだけでなく、その「構造」を維持することは、現代のAI(大規模言語モデル)活用において極めて重要です。Fire-PDFは、抽出したデータをAIが最も理解しやすい「Markdown形式」で出力することに特化しています 。
複雑なレイアウトの再現
多くのPDF解析ツールが苦手とするのが、複数カラム(段組み)の文書や、ヘッダー・フッターが混在する複雑なページ構成です。Fire-PDFは、ニューラルネットワークを用いたレイアウトモデルにより、テキストブロック、テーブル、数式、画像を個別に認識します 。
- 読解順序の予測: 複数カラムのレイアウトであっても、人間が読む順番通りにテキストを並べ替えます。補助的に「XY-cut投影法」というアルゴリズムをフォールバックとして備えており、極めて高い精度を維持します 。
- テーブル(表)の完全抽出: 表形式のデータに対しては、最大25秒という長い生成時間を割り当て、セルの結合や複雑な構造を正確にMarkdownテーブルへと再現します 。
- 数式のLaTeX保持: 科学論文や技術文書に含まれる数式は、画像として処理するのではなく、LaTeX形式として抽出されます。これにより、後続のAI処理において数式の内容を論理的に解析することが可能になります 。
ユーザーが選択できる3つの解析モード
Fire-PDFを利用する際、開発者はニーズに応じて解析の戦略を選択できます。これはAPIのmodeパラメータを通じて制御されます 。
| モード名 | 説明 | 推奨されるユースケース |
| auto (デフォルト) | 高速抽出を試み、不十分な場合にのみOCRを実行する | 一般的なビジネス文書、混合ドキュメント |
| fast | テキストベースの抽出のみを行い、画像ページは無視する | スピード重視、デジタル生成されたPDFのみ |
| ocr | 全ページに対して強制的にOCRを実行する | 古いスキャン文書、文字化けしやすい特殊フォント |
一般ユーザー向け「Fire PDF」:モバイルアプリの利便性
技術的な解析エンジンとしてのFire-PDFとは別に、個人のユーザーが日常的に利用できる「Fire PDF - Read PDF」というアプリがAndroid向けに提供されています 。このアプリは、初心者でも迷わずにPDFを扱える「オールインワン・ソリューション」を目指して設計されています。
直感的なインターフェースと基本機能
多くのPDFリーダーが機能の多さゆえに操作が複雑になりがちですが、Fire PDFアプリは「シンプルでストレスのないファイルアクセス」を最優先にしています 。
- マルチフォーマット対応: PDFだけでなく、Word(DOC)、PowerPoint(PPT)、Excelなど、ビジネスで多用されるオフィス文書の閲覧が可能です 。
- スムーズな閲覧体験: ページの切り替えが非常に滑らかで、スクロールや拡大・縮小も直感的に行えます。フルスクリーンモードにより、小さな画面でも読書に集中できる環境を提供します 。
- 強力な整理機能: デバイス内のドキュメントを自動的にスキャンしてリスト化し、削除や共有、フォルダ管理を簡単に行えるようにします 。
セキュリティとプライバシーへの配慮
モバイルアプリを利用する際、データの安全性を気にするユーザーは多いでしょう。Fire PDFは、送信中のデータを暗号化することでセキュリティを確保しています 。ただし、アプリの機能維持のために個人情報やアプリのアクティビティが一部収集される場合があるため、利用開始時に表示されるプライバシーポリシーを確認することが推奨されます 。また、ファイル管理権限(文書の表示・共有・整理に必要)を許可することで、アプリの全機能が解放されます 。
Amazon FireタブレットでのPDF活用ガイド
「Fire」という名前はAmazonのタブレットシリーズ「Fire HD」にも冠されています。これらのデバイスは、優れたコストパフォーマンスを誇る電子書籍リーダー・文書閲覧端末として広く普及しています 。
標準機能によるPDF閲覧
Fireタブレットには、Adobe PDFリーダーなどの基本的な閲覧機能がプリインストールされています 。
- メール添付ファイルの取得: 自分のメールアドレスにPDFを送り、Fireタブレットのメールアプリからダウンロードすると、自動的に「Docs(ドキュメント)」ライブラリに保存されます 。
- ドキュメントライブラリ: ダウンロードしたファイルは「Docs」からいつでも開くことができ、ピンチ操作でのズームや、ランドスケープ(横向き)モードでの閲覧にも対応しています 。
「自炊」書籍の最適化とサードパーティアプリ
紙の書籍をスキャンしてPDF化する、いわゆる「自炊」を楽しむユーザーにとって、Fireタブレットは理想的な端末です 。
- Perfect Viewerなどの活用: 標準機能でも閲覧は可能ですが、より高度な設定(見開き表示の自動化、右開き・左開きの設定、余白の自動カットなど)を求める場合は、サードパーティのアプリを導入することで、「キラーアプリ」と呼べるほどの快適な読書環境が手に入ります 。
- Send to Kindle機能: PCから「Send to Kindle」サービスを利用することで、Wi-Fi経由で簡単にPDFをタブレットに転送できます。ケーブルを繋ぐ手間が省けるため、大量の文書を管理する際に非常に便利です 。
開発者向けディープダイブ:C#ライブラリ「FirePDF」
プログラミングを通じてPDFを操作したい開発者にとって、「FirePDF」はさらに別の意味を持ちます。marktanner1331氏が公開しているC#用オープンソースライブラリは、PDFの低レベルな内部データにアクセスするためのユニークな手段を提供します 。
低レベルアクセスとストリーム編集
一般的なPDFライブラリが「テキストの抽出」や「ページの結合」といった高レベルな機能に限定されているのに対し、このFirePDFライブラリは、PDFの内部にある「オペレーションストリーム」を直接読み書きすることを可能にします 。
- グラフィカルデバッガー: 描画命令(ストリーム)のどの部分がページ上のどの要素に対応しているかを、個別の命令単位で確認できるデバッグツールが含まれています 。
- 構造の透明性: ページリソース内のソフトマスク(Soft Mask)や外部グラフィックス状態(ExtGState)など、PDFの仕様に深く関わる要素をプログラムから検索し、変更することができます 。
- フラット化(Flattening): 複数の画像を一つの画像に結合してPDFに再注入する機能など、最適化のための高度な機能も備えています 。
実際のコード例:ページの分割
FirePDFを使用すると、非常に直感的なコードでPDFの操作が可能です。以下は、複数ページのPDFを1ページずつの独立したファイルに分割する処理のイメージです。
C#
using (Pdf pdf = new Pdf(inputFile)) {
int i = 1;
foreach (Page page in pdf) {
using (Pdf newPdf = new Pdf()) {
newPdf.AddPage(page);
newPdf.Save(outputFolder + i + ".Pdf");
}
i++;
}
}
このように、usingステートメントによる適切なリソース管理を行いながら、オブジェクト指向的にPDFを扱える点が開発者にとっての魅力です 。

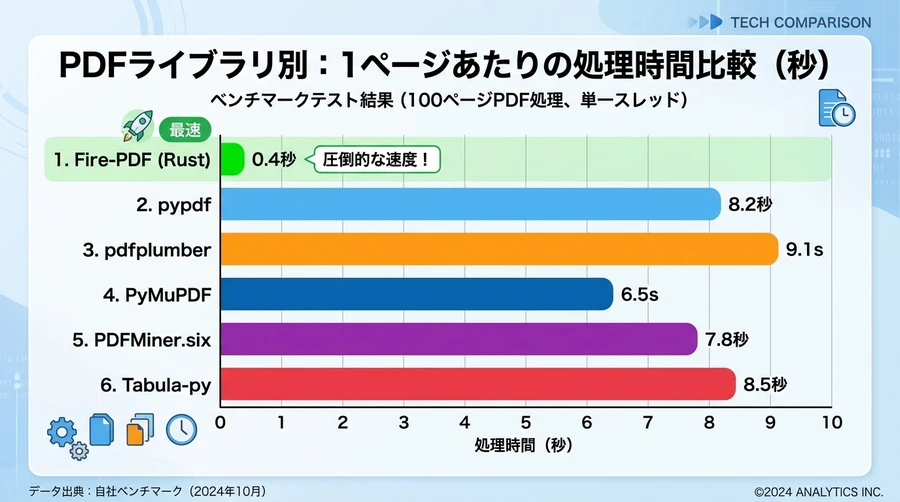
パフォーマンス比較:Fire-PDF vs 既存のPythonエコシステム
PDF処理において、ツール選択の基準となるのは「速度」「精度」「機能性」のバランスです。FirecrawlのFire-PDF(Rustエンジン)と、Pythonで広く普及しているライブラリを比較することで、その立ち位置を明確にします。
各種ライブラリの特性
| ライブラリ名 | 言語 / コア | 主な強み | 弱点・課題 |
| Fire-PDF (Firecrawl) | Rust / AI連携 | 3.5〜5.7倍の高速化、AI用Markdown出力、自動OCR切替 | API経由の利用が主(クレジット消費) |
| PyMuPDF (fitz) | C (MuPDF) | 非常に高速、レンダリング精度が高い | ライセンスがAGPL-3.0(商用利用に注意が必要) |
| PyPDF (v3) | Python (Pure) | 依存関係がなく、導入が極めて容易。結合・分割に強い | 処理速度が比較的遅く、複雑なレイアウトに弱い |
| pdfplumber | Python (pdfminer) | 表の抽出や座標指定に非常に強い | 大量の文書処理には向かないほど低速 |
| pypdfium2 | C++ (PDFium) | 純粋なテキスト抽出において最速クラス | 書式維持やMarkdown変換機能はない |
速度ベンチマークの洞察
PyMuPDFが長らく「最速」の座を維持してきましたが、FirecrawlのFire-PDFは「AI向けの構造化」という付加価値を加えつつ、1ページあたり平均400ms未満という驚異的な速度を達成しています 。特に、OCRが必要なページとそうでないページを自動で選別する機能により、実務上の「待ち時間」と「計算リソース」を最適化できる点は、既存のライブラリにはない革新的なメリットです 。
経済的合理性:Firecrawlの料金体系とクレジットの最適化
Fire-PDFエンジンのパワーをビジネスで活用する場合、コスト計算は避けて通れません。Firecrawlは、従量課金に近い「クレジット制」を採用しています 。
クレジット消費の計算式
FirecrawlにおけるPDF処理のコストは、以下のように積み上げ方式で計算されます 。
- 基本スクレイピング費用: 1ページあたり 1クレジット
- PDF解析加算: 1ページあたり +1クレジット
- (オプション)LLMによるJSON抽出: 1ページあたり +4クレジット
例えば、10ページのPDFドキュメントをMarkdownとして抽出する場合、合計で 1 (基本) + 10 (PDF解析) = 11クレジット が消費されます 。これは、単純なHTMLのWebページを取得するよりもコストがかかりますが、OCR処理や構造化の精度を考えれば、極めて高い投資対効果(ROI)を提供します。
プラン選択の指針
利用頻度に応じて、以下のプランから選択することが一般的です 。
- Freeプラン: 500クレジット(初回のみ)。小規模なテストや、Fire-PDFの精度を確認するための初心者に最適です 。
- Hobbyプラン ($16/月): 月間3,000クレジット。個人のブログ運営や、特定のニッチなデータ収集に適しています 。
- Standardプラン ($83/月): 月間100,000クレジット。最も人気のあるプランで、月間数千件のドキュメントを処理するビジネス用途に対応します 。
- Growthプラン ($333/月): 月間500,000クレジット。大規模なデータ収集や、リアルタイムの文書解析パイプラインを運用する企業向けです 。
結論と将来展望
「Fire-PDF」は、初心者にとっては「スマホやタブレットでPDFを快適に読むための入り口」であり、プロの開発者にとっては「AI時代のデータ抽出を加速させる強力な武器」です。
モバイルアプリとしてのFire PDFは、そのシンプルさと直感的な操作性により、文書管理のストレスを劇的に軽減します。一方、FirecrawlのFire-PDFエンジンは、Rustという強力な言語の力を借りて、これまで不可能だった「速度」と「構造化の精度」の両立を成し遂げました。特に、Markdown形式での出力は、今後さらに拡大するであろうAIによる文書要約やRAG(検索拡張生成)システムにおいて、標準的なプロトコルとしての地位を確立していくでしょう。
PDFという、一見すると「枯れた技術」に見えるフォーマットは、Fire-PDFのような先進的なツールの登場によって、再びエキサイティングなイノベーションの舞台へと進化しました。本レポートを通じて、それぞれの読者が自分に最適な「Fire-PDF」を見つけ、その恩恵を最大限に享受できることを願っています。
参考資料(文中番号に対応)
- Fire PDF-Read PDF - Google Play のアプリ, https://play.google.com/store/apps/details?id=fire.readpdf.com&hl=ja#:~:text=Fire%20PDF%E3%81%AF%E3%80%81%E3%81%84%E3%81%A4%E3%81%A7%E3%82%82%E3%81%A9%E3%81%93%E3%81%A7%E3%82%82,%E5%85%B1%E6%9C%89%E3%81%A7%E3%81%8D%E3%82%8B%E3%82%AA%E3%83%BC%E3%83%AB%E3%82%A4%E3%83%B3%E3%83%AF%E3%83%B3%E3%82%BD%E3%83%AA%E3%83%A5%E3%83%BC%E3%82%B7%E3%83%A7%E3%83%B3%E3%81%A7%E3%81%99%EF%BC%81&text=%E3%82%B7%E3%83%B3%E3%83%97%E3%83%AB%E3%81%A7%E7%9B%B4%E6%84%9F%E7%9A%84%E3%81%AA,%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB%E3%81%AB%E3%82%A2%E3%82%AF%E3%82%BB%E3%82%B9%E3%81%A7%E3%81%8D%E3%81%BE%E3%81%99%E3%80%82&text=%E4%BB%8A%E3%81%99%E3%81%90%E3%83%80%E3%82%A6%E3%83%B3%E3%83%AD%E3%83%BC%E3%83%89%E3%81%97%E3%81%A6,%E6%96%87%E6%9B%B8%E5%87%A6%E7%90%86%E3%82%92%E7%B0%A1%E5%8D%98%E3%81%AB%EF%BC%81
- Fire PDF - ファイル閲覧アプリ - Google Play, https://play.google.com/store/apps/details?id=fire.readpdf.com&hl=ja
- Introducing Fire-PDF: Firecrawl's New PDF Parsing Engine, https://www.firecrawl.dev/blog/fire-pdf-launch
- Fire-PDF 使い方 - ドキュメント作成と保存, https://mapillaries.com/fire-document-create/
- Best way to read PDFs on Kindle Fire HD - Reddit, https://www.reddit.com/r/kindlefire/comments/12fnd4/best_way_to_read_pdfs_on_kindle_fire_hd/?tl=ja
- Fire HD 8 PDFの開き方について - Amazon デバイスフォーラム, https://jp.amazonforum.com/s/question/0D56Q0000CE14J8SQJ/fire-hd-8-pdf%E3%81%AE%E9%96%8B%E3%81%8D%E6%96%B9%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6
- Kindle Fireで自炊した本を読みたいユーザーのためのガイド, https://ushigyu.net/jisui-books-fire-hd/
- GitHub - chinapandaman/PyPDFForm: The Python library for PDF forms, https://github.com/chinapandaman/PyPDFForm
- pyO3F—A Python Framework for Wildfire-Related Optimization, https://www.researchgate.net/publication/399379677_pyO3F-A_Python_Framework_for_Wildfire-Related_Optimization_Part_II_Usage
- Fire Detection System in Python | PDF, https://www.scribd.com/document/641648480/FIRE-DETECTION-SYSTEM-IN-PYTHON
- Python Fire Guide - Turning Python components into CLIs, https://google.github.io/python-fire/guide/
- FireWxPy: A Python Package For Fire Weather Analysis, https://www.unidata.ucar.edu/blogs/news/entry/firewxpy-a-python-package-for
- How to generate PDF files in the browser using JavaScript, https://www.freecodecamp.org/news/how-to-generate-pdf-files-in-the-browser-using-javascript/
- Print PDF directly from JavaScript - Stack Overflow, https://stackoverflow.com/questions/16239513/print-pdf-directly-from-javascript
- Generate PDFs from JavaScript - Nutrient Blog, https://www.nutrient.io/blog/generate-pdfs-from-javascript/
- How to generate PDFs in the browser with JavaScript, https://joyfill.io/blog/how-to-generate-pdfs-in-the-browser-with-javascript-no-server-needed
- pdf-lib documentation - Create and modify PDFs in JavaScript, https://pdf-lib.js.org/
- Introducing Fire-PDF: Firecrawl's New Rust-based PDF Parsing Engine, https://www.firecrawl.dev/blog/fire-pdf-launch
- Fire PDF - Apps on Google Play, https://play.google.com/store/apps/details?id=fire.readpdf.com
- GitHub - marktanner1331/FirePDF: Opensource library for editing PDFs in C#, https://github.com/marktanner1331/FirePDF
- Firecrawl Document Parsing - Mode options, https://docs.firecrawl.dev/features/document-parsing
- How can you access PDF and spreadsheet files on Fire HD 8 - Amazon Forum, https://www.amazonforum.com/s/question/0D54P000080ACUASA4/how-can-you-access-pdf-and-spreadsheet-files-on-fire-hd-8
- Firecrawl 利用方法とAPIキーの取得 - note, https://note.com/asap/n/nc5f247ef454e
- Firecrawl PDF解析のスクレイピングガイド, https://docs.firecrawl.dev/ja/advanced-scraping-guide
- Brand style guide generator cookbook - Firecrawl Docs, https://docs.firecrawl.dev/ja/developer-guides/cookbooks/brand-style-guide-generator-cookbook
- Firecrawl クロール機能の基本的な使い方, https://docs.firecrawl.dev/ja/features/crawl
- Firecrawl Blog - Fire-PDF launch announcement, https://www.firecrawl.dev/blog/fire-pdf-launch
- How do you scrape PDFs from a website? | Firecrawl Glossary, https://www.firecrawl.dev/glossary/web-scraping-apis/scrape-pdf-from-website
- Introducing PDF Parser v2: Faster Extraction with Auto Mode, https://www.firecrawl.dev/blog/pdf-parser-v2
- Introducing Firecrawl Skill and CLI, https://www.firecrawl.dev/blog/introducing-firecrawl-skill-and-cli
- Firecrawl Document Parsing features, https://docs.firecrawl.dev/features/document-parsing
- Fire-PDF: Rust製の高速PDF解析エンジン - note, https://note.com/toshia_fuji/n/n6101a8d46b49
- Firecrawl rewrites PDF parser in Rust - speed boost up to 5.7x, https://www.kucoin.com/ja/news/flash/firecrawl-rewrites-pdf-parser-in-rust-speed-boosts-up-to-5-7x
- DirectScan and FIRE PDF platform - PDF Solutions, https://www.pdf.com/ja/directscan-redefining-e-beam-inspection-for-next-generation-semiconductors/
- Best Python PDF Libraries - Nutrient Blog, https://www.nutrient.io/blog/best-python-pdf-libraries/
- PyMuPDF Performance and License - official documentation, https://pymupdf.readthedocs.io/en/latest/about.html
- Evaluation of rule-based tools for text extraction from PDFs - Arxiv, https://arxiv.org/html/2410.09871v1
- I tested 7 Python PDF extractors so you don't have to - Medium, https://onlyoneaman.medium.com/i-tested-7-python-pdf-extractors-so-you-dont-have-to-2025-edition-c88013922257
- Best Python library for extracting text from PDFs - Reddit, https://www.reddit.com/r/LangChain/comments/1e7cntq/whats_the_best_python_library_for_extracting_text/
- Firecrawl Pricing and Sales Forge directory, https://www.salesforge.ai/directory/sales-tools/firecrawl
- Firecrawl Official Pricing, https://www.firecrawl.dev/pricing
- Firecrawl Pricing Plans in 2026 - ScrapeGraphAI blog, https://scrapegraphai.com/blog/firecrawl-pricing
- How Firecrawl billing and credits work, https://docs.firecrawl.dev/billing
- Firecrawl Document Parsing Credit Cost, https://docs.firecrawl.dev/features/document-parsing
- How to get API Key from Firecrawl - dev.to, https://dev.to/abdibrokhim/how-to-get-api-key-from-firecrawl-4d5g
- Firecrawl Introduction - Get started and API key, https://docs.firecrawl.dev/introduction
- Firecrawl v0 Introduction - API Key and usage, https://docs.firecrawl.dev/v0/introduction
- Web scraping intro for beginners - Firecrawl Blog, https://www.firecrawl.dev/blog/web-scraping-intro-for-beginners
- Firecrawl GitHub Repository - Quick start and Scrape, https://github.com/firecrawl/firecrawl
- pdf-inspector: Fast Rust library for PDF classification, https://github.com/firecrawl/pdf-inspector#:~:text=Fast%20Rust%20library%20for%20PDF%20classification%20and%20text%20extraction.,bindings%20for%20Python%20and%20Node.
- GitHub - firecrawl/pdf-inspector features and scan strategies, https://github.com/firecrawl/pdf-inspector
- Firecrawl Blog - What is Fire-PDF and how it works, https://www.firecrawl.dev/blog/fire-pdf-launch
- Firecrawl GitHub Organization - Core Ecosystem, https://github.com/firecrawl
- GitHub Topic: Text Extraction - high performance libraries, https://github.com/topics/text-extraction
- pdf-inspector repository - Rust build artifacts and test files, https://github.com/firecrawl/pdf-inspector/blob/main/.gitignore
- Adobe Firefly credit system explained, https://www.adcal-inc.com/column/adobe-firefly-cost/
- Adobe Firefly free plan and credit usage, https://www.sungrove.co.jp/adobe-firefly/

コメント