

「Open-Sora」のPodcast
下記のPodcastは、Geminiで作成しました。
はじめに
近年、人工知能技術の劇的な進化に伴い、入力されたテキスト(プロンプト)から極めて高品質でリアルな動画を生成する技術が大きな注目を集めています。アメリカのOpenAI社が発表した動画生成AI「Sora」はその驚異的な表現力で世界に大きな衝撃を与えましたが、同モデルは非公開のクローズドなサービスであり、一般の開発者がその内部構造を検証したり、独自のデータを用いてカスタマイズしたりすることは困難でした。こうした課題に対し、誰もが自由に最先端の動画生成技術にアクセスし、検証・応用できる環境を提供する目的で立ち上げられたプロジェクトが、完全オープンソースの動画生成AI「Open-Sora」です 。
本レポートでは、動画生成AIの仕組みや導入方法に関心を持つ初心者に向けて、Open-Soraの概要、歴史、内部で機能する最新のアーキテクチャ、具体的なインストール手順、およびローカル環境やクラウド環境での実行方法について、専門的な知見に基づき分かりやすく解説します。
第1章:動画生成AIの民主化を掲げる「Open-Sora」の基礎知識
Open-Soraは、大規模モデルの分散並列処理システム「Colossal-AI」の開発で知られるHPC-AI Technology(HPC-AI Tech)によって主導されているオープンソースプロジェクトです 。このプロジェクトの最大のミッションは、高度な動画生成技術を一部の巨大テック企業の手から解放し、すべての人々が効率的かつ低コストで高品質なビデオ制作を行える「技術の民主化」を実現することにあります 。
一般に、商用レベルの高品質な動画生成モデルを構築・訓練するには、数百万ドル(数億円規模)にのぼる膨大な計算資源とトレーニング費用が必要とされてきました 。しかし、Open-Soraプロジェクトはオープンソースコミュニティの力を結集し、最先端のモデルアーキテクチャと分散学習最適化技術(ColossalAIなど)を融合させることで、トレーニングコストを従来の数分の一以下に削減することに成功しました 。
開発チームがプログラムのソースコード、モデルの重み(ウェイト)、データ前処理ツール、そして詳細な設計資料にいたるまで、すべてのリソースをオープンライセンスである「Apache 2.0」に基づいて無償公開しているため、世界中の研究者やクリエイターがこの技術をベースに新たなイノベーションを創出しています 。また、プロジェクトの公式デモンストレーションリポジトリを通じて、実際の動作サンプルや技術レポートが継続的に共有されており、誰でもその進捗をリアルタイムに確認できます 。
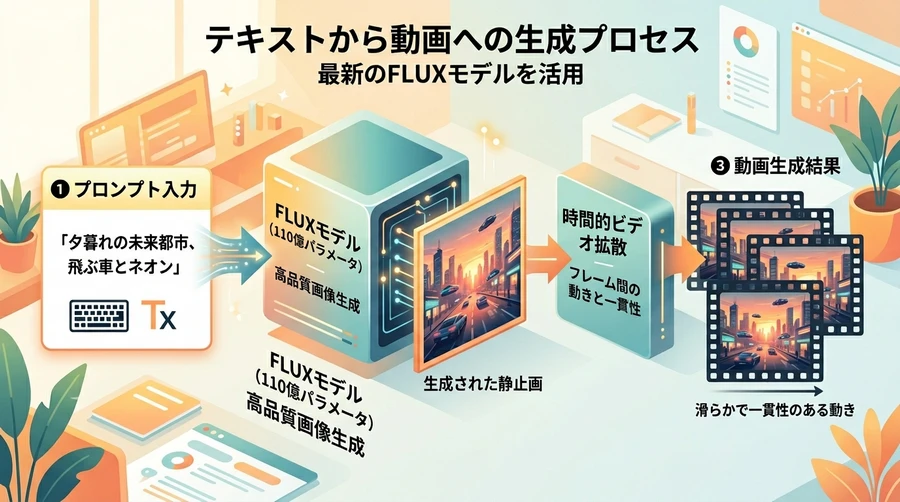
【Open-Sora 2.0におけるFLUX基礎モデルと2段階生成パイプラインの概要】
第2章:誕生から最新版「2.0」にいたる進化のロードマップ
Open-Soraは2024年3月の最初のリリース以降、驚異的なスピードでアップデートを重ねてきました 。各バージョンにおける技術的な到達点と仕様の変遷を以下の表にまとめます。
表1:Open-Soraの各バージョンにおける技術仕様と比較
| バージョン | リリース時期 | 主な解像度 | 最大生成時間 | 導入された主要な技術・機能 |
| Open-Sora 1.0 | 2024年3月 | 512×512px | 2秒 | 初代モデル。データ前処理ラインの構築、3日間の学習での高速生成 。 |
| Open-Sora 1.1 | 2024年4月 | 144p 〜 720p | 2秒 〜 15s | 任意のアスペクト比・解像度に対応。Image-to-Video、無限時間生成 。 |
| Open-Sora 1.2 | 2024年6月 | 144p 〜 720p | 最大16秒 | 3D-VAE、Rectified Flow(整流フロー)、スコア条件付けを導入 。 |
| Open-Sora 1.3 | 2025年2月 | 144p 〜 720p | 最大16秒 | 1Bモデル。Shift-Window Attention、統合時空間VAEを導入 。 |
| Open-Sora 2.0 | 2025年3月 | 256p 〜 768p | 16秒以上 | 11Bモデル。FLUXベースの2段階パイプライン、Video DC-AEの採用 。 |
特に2025年3月にリリースされた「Open-Sora 2.0」は、パラメータ数が110億(11B)に達する極めて野心的な大型モデルです 。これにより、先行する大手テック企業の商用動画生成モデル(HunyuanVideo 11BやStep-Video 30Bなど)と肩を並べる、極めて滑らかで美しい映像出力が可能となりました 。
第3章:Open-Sora 2.0の画期的な映像表現を支える3つのコア技術
最新のOpen-Sora 2.0がこれほど高精度な映像生成を低コストで実現できた背景には、開発チームによる3つの画期的な技術的ブレイクスルーがあります 。
① 既存の高性能画像モデル「FLUX」の賢い活用
動画生成モデルをゼロからトレーニングする場合、AIに「美しい静止画を描く能力」と「それを時間軸に沿って滑らかに動かす能力」の双方を同時に教え込む必要があり、膨大な計算コストが発生します 。 Open-Sora 2.0では、世界的に高い評価を得ている110億パラメータのオープンソース画像生成モデル「FLUX」を基礎(ファンデーションモデル)として採用する手法を採りました 。FLUXがあらかじめ備えている高度な視覚理解能力と描写力をベースにし、そこに「動き」を制御する時間軸の学習のみを追加(ファインチューニング)することで、学習効率を飛躍的に高めています 。
② MM-DiT(Multimodal Diffusion Transformer)
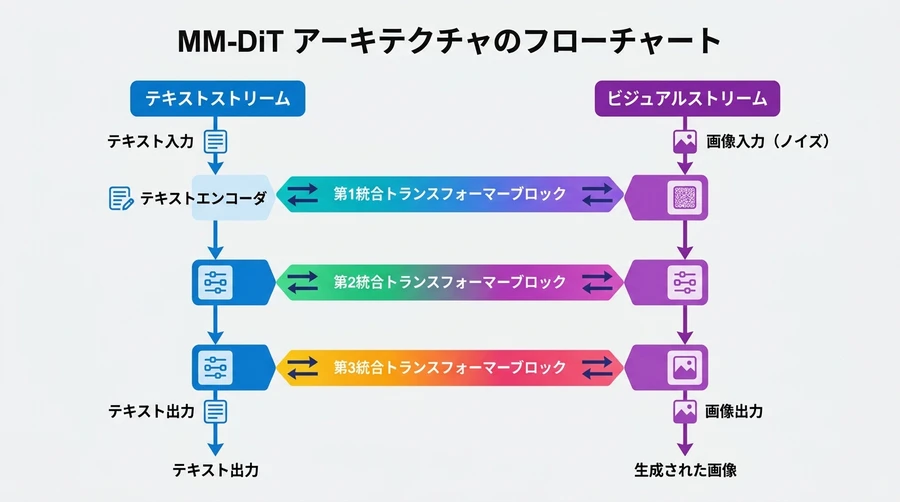
動画生成における最大の難関は、時間が経過してもキャラクターの顔や背景のディテールが崩れない「時間的一貫性(Temporal Consistency)」を維持することです 。 Open-Sora 2.0では、テキストデータと映像データを個別のレーンで処理しつつ、相互の情報を双方向にやり取りさせる「MM-DiT」アーキテクチャを採用しています。 具体的には、まずテキストと言葉のセマンティクス(意味合い)を捉えるレーンと、映像フレームのノイズを低減(デノイズ)するビジュアルレーンを独立して走らせます 。そして、その中間に設置された統合トランスフォーマーブロックが架け橋となり、テキストの指示が映像に、そして映像の特徴がテキストの理解にシームレスに影響を及ぼし合う構造を確立しました 。これにより、複雑なプロンプトの指示に対しても、描写が崩れることなく、破綻のない滑らかな動きを持った映像が生成されます 。
③ データを極限まで軽量化する「Video DC-AE」
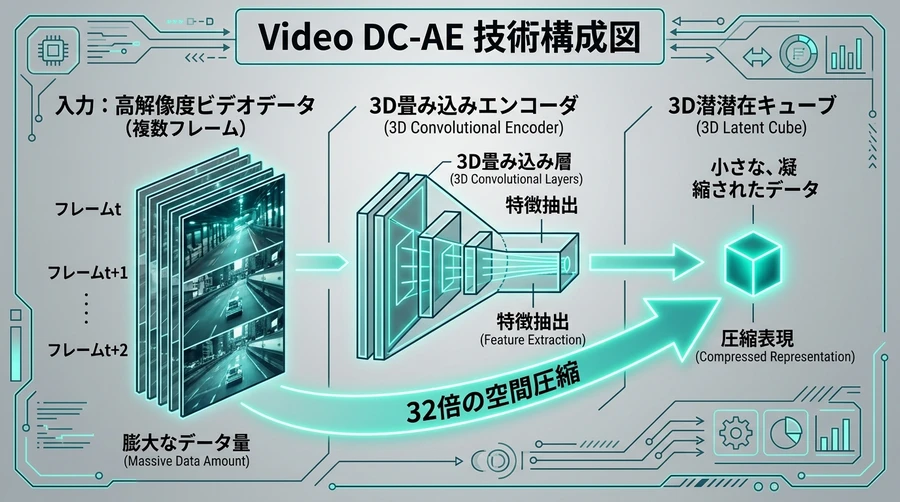
高解像度の動画データはそのまま処理するとメモリ消費量が極限に達し、市販のグラフィックボードでは動作不全を起こします 。 Open-Sora 2.0では、新開発の動画用超圧縮技術「Video DC-AE(Video Deep Compression Autoencoder)」を搭載しました 。これは従来の静止画用圧縮技術を3次元の動画用に拡張したものであり、時間的な滑らかさを維持したまま、データの空間サイズを32倍にまで強力に圧縮します 。 従来の圧縮方式(HunyuanVideoのVAEなど)では1本の動画につき約115,000個ものデータトークンを処理する必要がありましたが、Video DC-AEの導入によってこのトークン数が大幅に削減され、GPUに対する負荷と必要なメモリ容量を大幅に低減することに成功しました 。
【MM-DiT(マルチモーダル・ディフューザー・トランスフォーマー)の双方向連携メカニズム】
第4章:動作に必要なハードウェアスペックと各モデルの違い
Open-Soraはユーザーの保有するシステム環境に合わせて柔軟にモデルサイズを選択できます 。ローカル環境で動作を検証する場合に必要な最小、推奨、および最適なGPUスペックを以下の表にまとめました。
表2:モデルバージョンごとのハードウェア要件一覧
| モデルバージョン | 最小必要なビデオメモリ(VRAM) | 推奨されるGPUスペック | 最適な動作環境 |
| Open-Sora 1.0 | 8GB | RTX 3070 8GB | RTX 3090 / 4090 |
| Open-Sora 1.1 | 16GB | RTX 3090 16GB / 24GB | A100 40GB |
| Open-Sora 1.2 | 24GB | RTX 4090 24GB | A100 80GB |
| Open-Sora 2.0 | 24GB(一部制限あり) | A100 40GB | A100 80GB / H100 |
ローカル環境で24GB未満のGPU(例えばRTX 3070や3080など)を使用する場合、最新の2.0モデルのような超巨大なモデルを直接実行することは困難ですが、バージョン1.0や1.3といった軽量モデルを活用することで、低解像度での動作検証や概念実証(PoC)を十分に行うことができます 。
一方、オープンソースの類似動画生成AI「Latte」などは最低動作環境としてA100(80GB VRAM)を要求するため、それらと比較してOpen-Soraは格段に低いスペックから利用を開始できる点が際立っています 。
【Video DC-AEによる動画データの超圧縮プロセス】
第5章:初心者でもできる!インストールと動画生成の完全ガイド
ここでは、自身のローカルPC(GPU搭載のLinuxまたはWindows WSL2環境を想定)にOpen-Soraをインストールし、テキストから動画を生成するまでの手順を分かりやすく解説します。
① 仮想環境の構築とインストール
まず、Pythonライブラリの依存関係が他のプロジェクトと干渉するのを防ぐため、Condaを用いてクリーンな専用仮想環境を作成します 。
Bash
# Python 3.10をベースにした「opensora」という名前の環境を作成します
conda create -n opensora python=3.10 -y
# 作成した環境を有効化(アクティベート)します
conda activate opensora
次に、公式リポジトリからソースコードをクローン(ダウンロード)し、本体および依存パッケージをインストールします 。
Bash
# 公式リポジトリからダウンロード
git clone https://github.com/hpcaitech/Open-Sora
cd Open-Sora
# 必要なパッケージ群をまとめてインストールします
pip install -v.
② 学習済みモデルデータのダウンロード
動画の生成に必要な重みデータを、Hugging Faceの公式リポジトリからダウンロードします 。
Bash
# ダウンロード用のヘルパーツールをインストール
pip install "huggingface_hub[cli]"
# 最新のOpen-Sora 2.0(11B)のモデルデータをローカルフォルダ(ckpts)にダウンロード
huggingface-cli download hpcai-tech/Open-Sora-v2 --local-dir./ckpts
③ 動画の生成(推論の実行)
準備が整ったら、テストコマンドを実行して動画を生成してみましょう 。ここでは「穏やかに波打つ海と降り注ぐ雨」というプロンプトを指定します 。
Bash
python scripts/inference.py \
--prompt "raining, sea" \
--num-frames 51 \
--resolution 256p \
--save-dir./outputs
実行後、指定した解像度(256p)の動画ファイルが outputs フォルダ内に保存されます。アスペクト比を変更したい場合は --aspect_ratio 16:9、動画の長さを長くしたい場合は --num-frames 102 などのオプションを指定することでカスタマイズが可能です 。
第6章:カスタムデータセットを用いた追加学習(ファインチューニング)
Open-Soraの真骨頂は、ユーザーが保有する独自の動画素材やアセットを読み込ませて、特定の画風やキャラクターに特化した「追加学習(ファインチューニング)」を行える点にあります 。
① データセットの準備
追加学習を行うためには、動画ファイル群と、それぞれの動画内容を説明したテキスト(キャプション)を対応させる必要があります 。 データセットの情報は、CSV形式またはParquet(パーケ)形式で管理します 。CSVファイルには、最低限以下の列(カラム)を含める必要があります 。
- path: ローカル環境に保存された動画ファイルへのパス
- text: 動画の内容を説明するテキスト(例:"A golden retriever playing with a red ball in the park")
- num_frames: 動画の総フレーム数
- height / width: 動画の高さおよび幅(ピクセル単位)
- aspect_ratio / resolution: アスペクト比および解像度の数値
- fps: 動画のフレームレート(例:24 または 30)
② ファインチューニングコマンドの実行
準備したデータセット(例:pexels_45k_necessary.csv)を使用し、複数のGPUを用いて効率的に学習を実行するコマンドの例は以下の通りです 。
Bash
torchrun --nproc_per_node 8 scripts/diffusion/train.py \
configs/diffusion/train/stage1.py \
--dataset.data-path datasets/pexels_45k_necessary.csv \
--model.from_pretrained ckpts/Open_Sora_v2.safetensors
③ メモリ削減のための最適化設定
トレーニング時のGPUメモリ不足を避けるため、Open-Soraは「選択的グラジエント・チェックポインティング(Selective Gradient Checkpointing)」をサポートしています 。設定ファイル(Config)内で grad_ckpt_setting = (100, 100) のようにタプル形式で適用するレイヤー数を指定することで、計算速度を大幅に犠牲にすることなく、VRAMの使用量を劇的に削減できます 。
第7章:クラウドGPU環境(RunPod / Clore.ai)での効率的な実行方法
「手元のパソコンに高性能なグラフィックボードが搭載されていない」という場合でも、クラウド上のGPUを時間単位でレンタルする「クラウドGPUサービス」を活用すれば、極めて安価に最新のOpen-Sora 2.0を実行できます 。
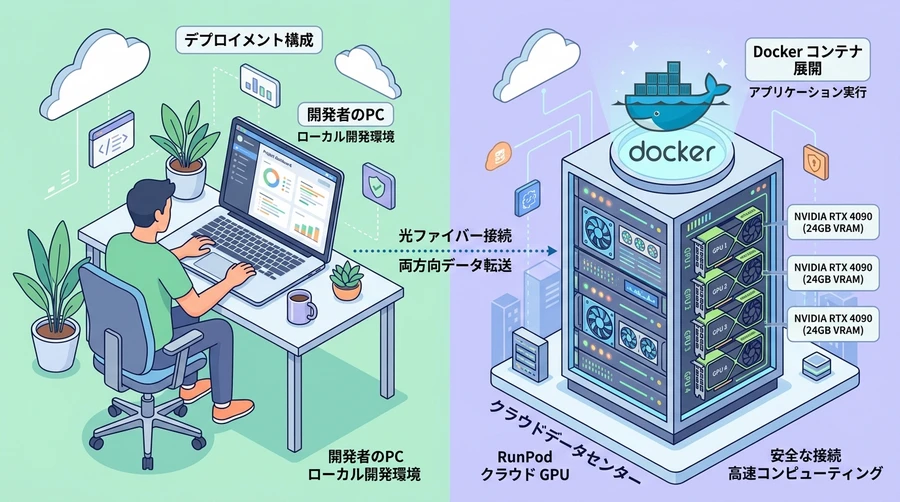
① RunPodでのDockerを用いたデプロイ
RunPodなどのサービスでは、あらかじめ必要な環境(CUDA、PyTorchなど)がインストールされたコンテナを利用することで、セットアップ作業を一瞬で完了できます 。
- GPUの選択: RunPodのコントロールパネルから、24GB以上のVRAMを持つ「RTX 4090」や、より高速な「L40S」を搭載したポッド(仮想マシン)を選択して起動します 。
- ベースイメージの指定: コンテナのベースイメージとして
runpod/base:0.6.2-cuda12.2.0などを指定します 。 - Dockerファイルのビルド例: 以下の設定を含むDocker環境を構築することで、Open-Soraの準備が整います 。
Dockerfile
FROM runpod/base:0.6.2-cuda12.2.0
RUN apt-get update && apt-get install -y git ffmpeg
RUN pip install torch==2.1.0 torchvision==0.16.0 --index-url https://download.pytorch.org/whl/cu122
RUN pip install open-sora diffusers accelerate
RUN git clone https://github.com/hpcaitech/Open-Sora /workspace/open-sora
WORKDIR /workspace/open-sora
RUN pip install -r requirements.txt
コンテナの起動後、Webブラウザ上の端末(Jupyter NotebookやSSH)からアクセスし、第5章で紹介した推論用スクリプトを実行するだけで、およそ数分で動画の生成が完了します 。
【RunPodおよびClore.aiにおけるDockerコンテナを用いたクラウドGPUデプロイ】
第8章:商用モデル(Azure OpenAI Sora)との比較と将来展望
Open-Soraを語る上で避けて通れないのが、OpenAI社が開発する本家「Sora」や、そのMicrosoftによる商用サービス「Azure OpenAI Sora(Sora 2)」との比較です 。
Microsoft Azure上で提供されている商用Soraは、完全に管理されたクラウド上の「プレイグラウンド」を提供し、コーディングを一切必要としないノーコードのアプローチで直感的に動画を生成できます 。コンテンツフィルタリングなどの強固なセキュリティ制御が組み込まれており、企業ユーザーが安全に利用できる点が強みです 。
しかし、商用サービスはAPIの利用料金が高額になりがちであるほか、中身の技術が「ブラックボックス」であるため、学術研究やディープなカスタマイズを行うことはできません 。
一方、Open-Sora 2.0は完全にオープンソースであり、ライセンスも商用利用可能な「Apache 2.0」を採用しているため、自社のプライベートサーバーに構築して独自のデータのみで追加学習させることが容易です 。さらに、H200 GPUをレンタルして合計4,160時間という限られたリソースを使用することで、わずか20万ドル(約2000万円)という非常にコントロールされた予算範囲内で、トップクラスの商用モデルと同等のモデルを学習できることを証明しました 。この「優れたコストパフォーマンス」と「圧倒的な自由度」こそが、Open-Soraが選ばれる最大の理由です 。
参考資料
- Open-Sora-Demo GitHub Repository、https://github.com/hpcaitech/Open-Sora-Demo
- Releases · hpcaitech/Open-Sora-Demo、https://github.com/hpcaitech/Open-Sora-Demo/releases
- Technical Report of Open-Sora 2.0、https://github.com/hpcaitech/Open-Sora-Demo/blob/main/paper/Open_Sora_2_tech_report.pdf
- Hugging Face Model Repository: hpcai-tech/Open-Sora-v2、https://huggingface.co/hpcai-tech/Open-Sora-v2
- Open-Sora Training and Finetuning Documentation、https://github.com/hpcaitech/Open-Sora/blob/main/docs/train.md
- Hugging Face Readme Commit History for Open-Sora-v2、https://huggingface.co/hpcai-tech/Open-Sora-v2/blame/44527d84044152ae014ff5e01668cf7f5fff64c3/README.md
- ArXiv: Open-Sora 2.0: Commercial-Level Video Generation、https://arxiv.org/html/2503.09642v1
- GitHub Repository: hpcaitech/Open-Sora、https://github.com/hpcaitech/Open-Sora
- Louis Bouchard: Technical Breakdown of Open-Sora 2.0、https://www.louisbouchard.ai/open-sora-2/
- Microsoft Learn: Video Generation with Azure OpenAI Service、https://learn.microsoft.com/en-us/azure/foundry/openai/concepts/video-generation
- Clore.ai: OpenSora Deployment and Inference Guide、https://docs.clore.ai/guides/video-generation/opensora
- Latte: Is an Open-Sora Actually Feasible?、https://blog.stackademic.com/is-an-open-sora-actually-feasible-8673235598d6
- RunPod: Deploying Open-Sora with Docker、https://www.runpod.io/articles/guides/deploying-open-sora-for-ai-video-generation-using-docker-containers


コメント