

- Corpus2SkillのPodcast
- はじめに
- 1. なぜ今のAIは「迷子」になってしまうのか:RAGの限界
- 2. Corpus2Skillとは何か:知識を「技能」に変える魔法
- 3. Corpus2Skillの仕組み:地図を作る「コンパイル」と歩く「サーブ」
- 4. 魔法のファイル:SKILL.md と INDEX.md の中身
- 5. 驚きの性能:なぜ Corpus2Skill は「賢い」のか
- 6. お財布にも優しい:Prompt Cachingによるコスト削減
- 7. 実践:Corpus2Skillを動かしてみよう!
- 8. 他の技術との比較:何が一番違うのか?
- 9. 未来の展望:自律的なAI専門家への道
- 結論:Corpus2Skillが切り拓く新しいAIのカタチ
- 参考資料
Corpus2SkillのPodcast
下記のPodcastは、Geminiで作成しました。
はじめに
現代のビジネスや日常生活において、大規模言語モデル(LLM)は欠かせない存在となりました。しかし、AIに特定の専門知識や社内文書を教え込み、正確に答えさせるための代表的な技術である「RAG(検索拡張生成)」には、実は大きな落とし穴があることをご存知でしょうか。せっかく用意したマニュアルやドキュメントが、AIの中で「バラバラのパズル」のように扱われ、文脈を無視した誤った回答を生み出してしまう——そんな課題を解決するために登場したのが「Corpus2Skill(コーパス・トゥ・スキル)」という全く新しいアプローチです。
本レポートでは、従来の検索技術の限界を突破し、AIエージェントに「知識の地図」を授けるこの画期的な手法について、初心者の方にも分かりやすく、かつ専門的な知見を交えて徹底的に解説します。情報の「検索」から「ナビゲーション(探索)」へと進化する、AI活用の未来を一緒に見ていきましょう。
1. なぜ今のAIは「迷子」になってしまうのか:RAGの限界
AIが最新のニュースや個人のドキュメントを読み取って回答する「RAG」という仕組みは、非常に便利なものです。しかし、この仕組みには「断片化の壁」という大きな弱点があります。
断片化された情報のジレンマ
従来のRAGでは、膨大な文書を機械的に数百文字程度の「チャンク(断片)」に細切れにします。そして、ユーザーの質問に関連しそうな断片を「検索」してAIに渡します。ここで問題となるのは、AIが「文書全体の構造」を見失ってしまうことです 。
例えば、ある家電製品の「設定方法」について聞いているのに、検索エンジンが「解約方法」のページから似たような単語を拾ってきてしまったらどうなるでしょうか。AIは渡された断片だけを見て、「設定するにはまず解約してください」といった、文脈を無視した恐ろしい回答を生成してしまう可能性があります 。これは、AIが情報の全体像を把握せず、単にキーワードの近さだけで情報を拾い上げているために起こる現象です。
検索という「運任せ」のプロセス
また、従来のベクトル検索は、情報の関連性を「数値」で判断しますが、なぜその情報が選ばれたのかという論理的な理由はブラックボックスになりがちです。AIは検索エンジンから与えられた断片を盲目的に信じるしかなく、もし検索結果が不十分であっても、「もっと別の場所を探そう」と自分で判断することができません 。

2. Corpus2Skillとは何か:知識を「技能」に変える魔法
Corpus2Skillは、2026年に発表された「Don't Retrieve, Navigate(検索するな、探索せよ)」という論文に基づいた新しい技術です 。この手法の最大の特徴は、膨大なドキュメント(コーパス)を、AIエージェントが自由に使いこなせる「スキル(技能)」として再構築する点にあります 。
検索ではなく「探索」へ
Corpus2Skillは、ドキュメントを細切れにするのではなく、事前にその全体像を整理し、AIが辿ることができる「知識のスキルツリー」を作成します。これを、人間がフォルダ分けされたファイルシステムや、本の目次を使って目的の情報に辿り着くプロセスになぞらえて「ナビゲーション(探索)」と呼びます 。
AIに「意思」を持たせる
この仕組みにより、AIエージェントは単なる情報の受け取り手から、能動的な「探索者」へと進化します。エージェントは自ら地図(スキルツリー)を開き、「この質問の答えは、おそらくこのカテゴリの、この文書にあるはずだ」と論理的に判断しながら、深い階層へと潜っていきます。もし選んだ道が間違いだと気づけば、元の階層に戻って別の道を試す(バックトラッキング)ことさえ可能です 。
3. Corpus2Skillの仕組み:地図を作る「コンパイル」と歩く「サーブ」
Corpus2Skillは、大きく分けて2つのフェーズで動いています。一つは事前に地図を準備する「コンパイルフェーズ」、もう一つは実際に質問に答える「サーブフェーズ」です 。
地図を作る:コンパイルフェーズ(構築時)
ここでは、バラバラの文書をAIが理解しやすい「スキル階層」へと変換します 。
- 文書のベクトル化(Embedding):まず、高性能なAIモデル(例:Qwen3-Embeddingなど)を使って、文書の内容を数値化し、意味の近さを計算します 。
- 階層的クラスタリング(Clustering):似た内容の文書同士をグループ化し、それをさらに大きなグループにまとめる、という作業を繰り返して「木構造(ツリー)」を作ります。
- 要約とラベル付け(Summarize & Label):各グループに対して、LLM(Claude 3.5 Sonnetなど)が「ここには何が書いてあるか」という要約と、短いラベル(見出し)を付けます 。
- スキルファイルの書き出し:最後に、これらをMarkdown形式のファイル(
SKILL.mdやINDEX.md)として保存します。これがAIにとっての「地図」になります 。
| 設定項目(フラグ) | 標準的な値 | 役割・意味 |
--p | 10 | 1つのフォルダ(階層)にいくつの選択肢を置くか |
--max-top | 8 | 最初の入り口(最上位スキル)をいくつにするか |
--model | claude-3-5-sonnet | 要約やラベルを作るために使うAIのモデル |
--embed-model | Qwen3-Embedding | 文書の意味の近さを測るために使うモデル |
--compact | False | 階層をあえて浅くして、移動の手間を減らすかどうか |
地図を歩く:サーブフェーズ(実行時)
実際にユーザーから質問が来ると、AIエージェントはこの地図を使って答えを探します 。
- ステップ1:入り口を選ぶ:エージェントはまず、用意された「スキル」のリストを見て、質問に最も関係がありそうなものを選びます 。
- ステップ2:階層を下る(ドリルダウン):選んだスキルの詳細(SKILL.md)を読み、さらに具体的なサブカテゴリへと進みます。これを何度か繰り返し、最終的な文書のリスト(INDEX.md)に到達します 。
- ステップ3:文書を読んで回答する:目的の文書を特定したら、その全文を読み込み、根拠に基づいた正確な回答を作成します 。
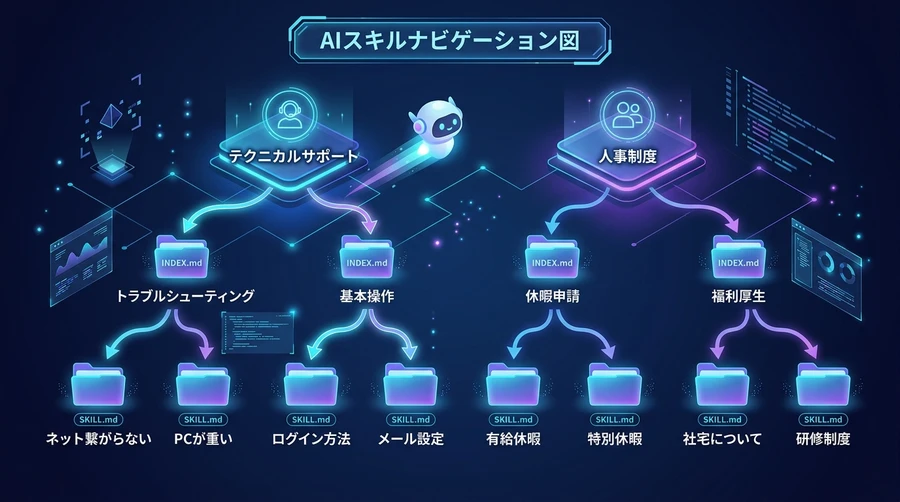
4. 魔法のファイル:SKILL.md と INDEX.md の中身
Corpus2Skillを支えるのは、実は私たち人間にも読める「Markdown」という形式のファイルです。これらはAnthropic(アンスロピック)社が提唱する「エージェント・スキル」という標準的な規格に準拠しています 。
SKILL.md:情報の道しるべ
SKILL.mdは、特定の階層の「説明書」です。
- 名前と説明: このスキルが何を解決するためのものか(例:返品手続きについて)。
- トリガーフレーズ: どんなキーワードが出たときにこのスキルを使うべきか 。
- サブグループの案内: 下の階層にはどんなトピックがあるかの目次。
INDEX.md:情報の終着点
INDEX.mdは、ツリーの末端(リーフ)にあり、具体的なドキュメントへのリンク集になっています 。
- ドキュメントID: 文書を一意に識別する番号。
- タイトルと要約: その文書に何が書いてあるかの短い紹介文。
エージェントはこのインデックスを見て、「この文書ID:123こそが、探していた答えだ!」と確信を持って文書を取得できるのです 。
5. 驚きの性能:なぜ Corpus2Skill は「賢い」のか
Corpus2Skillの効果は、研究データでもはっきりと証明されています。特に「WixQA」という、企業向けカスタマーサポートの知識ベースを用いたテストでは、従来のRAGを大きく引き離す成績を収めました 。
ベンチマークが示す実力
複雑なトラブルシューティングが必要な場面において、Corpus2Skillは情報の正確性(Factuality)と、必要な情報を漏らさず拾う能力(Context Recall)の両方で、既存の高度なAIシステム(RAPTORやAgentic RAGなど)を上回りました 。
| 評価指標 | 意味 | Corpus2Skillの結果 |
| Factuality | 回答内容が事実に基づいているか | 非常に高い。誤認が少ない |
| Context Recall | 必要な文書に正しく到達できたか | 他の手法を圧倒。迷子が少ない |
| Token F1 | 正解の文章との単語レベルの一致度 | 従来の検索手法より大幅に改善 |
| Cost (USD) | 1つの回答にかかる料金 | Prompt Caching活用で割安に |
構造化がもたらす「推論の透明性」
従来のRAGでは、「なぜAIがその回答をしたのか」を追跡するのが困難でした。しかしCorpus2Skillなら、AIがどのスキルを選び、どの階層を通って、どの文書に辿り着いたかという「足跡(ログ)」が明確に残ります。これは、間違いが許されないビジネスの現場において、非常に大きな信頼に繋がります 。
6. お財布にも優しい:Prompt Cachingによるコスト削減
AIを運用する上で避けて通れないのが「API料金」の問題です。Corpus2Skillは、Anthropic社の「Prompt Caching(プロンプト・キャッシュ)」という機能を最大限に活かす設計になっています 。
繰り返しの読み込みをゼロにする
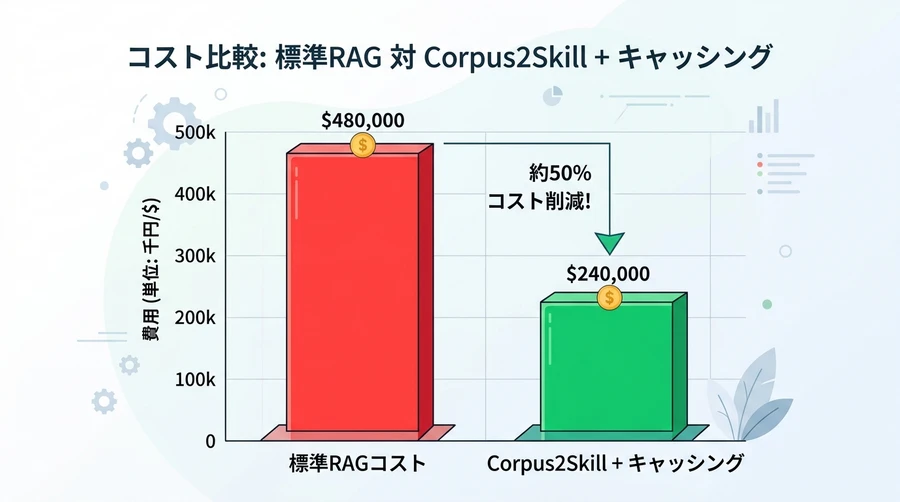
Corpus2Skillでは、AIが何度も同じ「地図(スキル階層)」を参照します。通常ならその都度料金が発生しますが、Prompt Cachingを使えば、一度読み込んだ地図の内容をAIが記憶(キャッシュ)しておけます。2回目以降の読み込み料金は大幅に割引(最大90%オフ)されるため、全体的なコストを約48%〜70%も削減できるのです 。
高速なレスポンス
キャッシュされた情報は、AIがゼロから読み直すよりも圧倒的に速く処理されます。これにより、ユーザーは待たされることなく、サクサクと回答を受け取ることができます 。
7. 実践:Corpus2Skillを動かしてみよう!
それでは、初心者の方でも自分のパソコンでCorpus2Skillを試すための具体的な手順を解説します。基本的には、公式のGitHubからプログラムをダウンロードして実行するだけです 。
準備するもの
- Python (3.10以上): プログラムを動かすための基礎となるソフトウェア。
- Anthropic APIキー: ClaudeというAIを使うための鍵。
- 文書データ: AIに教えたいテキストファイル(.txtや.md)を1つのフォルダにまとめておきます。
手順1:インストール
ターミナル(黒い画面)で以下のコマンドを入力します。
Bash
git clone https://github.com/dukesun99/Corpus2Skill.git
cd Corpus2Skill
pip install -e.
pip install anthropic sentence-transformers scikit-learn
手順2:地図(スキルツリー)のビルド
以下のコマンドで、あなたの文書をAI用の地図に変換します。
Bash
python -m corpus2skill \
--input./あなたの文書フォルダ \
--output./完成した地図の保存先 \
--p 10
これだけで、./完成した地図の保存先/.claude/skills/の中に、AIが歩くための道筋が自動生成されます 。
手順3:質問してみる
Pythonのプログラムから、AIに質問を投げます。
Python
from corpus2skill.serve import answer_query
from pathlib import Path
# 地図がある場所を指定
skills_dir = Path("./完成した地図の保存先/.claude/skills")
# 質問を実行!
result = answer_query(
"製品の保証期間について教えてください",
skills_dir=skills_dir,
use_prompt_caching=True # お得なキャッシュ機能をON
)
print(result["answer"])
8. 他の技術との比較:何が一番違うのか?
AIに知識を教える手法はCorpus2Skill以外にもいくつかあります。それぞれの特徴を整理してみましょう。
- 単純なRAG (Dense Retrieval):文書を細切れにして検索する。簡単だが、AIが迷子になりやすく、複雑な質問に弱い 。
- RAPTOR (要約型RAG):文書を階層的に要約するが、最終的には「検索」に頼る。Corpus2Skillよりも構造が隠れがち 。
- GraphRAG:文書間の関係を網の目(グラフ)のように整理する。非常に高度だが、構築に膨大なコストと時間がかかる 。
- Corpus2Skill:エージェントが自ら歩ける「地図」を作る。コストと精度のバランスが非常に良く、特に「AIエージェント」との相性が抜群 。

9. 未来の展望:自律的なAI専門家への道
Corpus2Skillは、単なる検索エンジンではありません。それは、AIを「特定の分野の専門家」として育てるための土台です 。
知識は「静的なデータ」から「動的なスキル」へ
これまでは、AIにデータを「渡す」だけでした。しかし、Corpus2Skillによって、AIはデータを自ら「使いこなす」術を学びます。今後は、マニュアルを読み取るだけでなく、その知識に基づいて「実際にツールを操作する」「コードを書く」「顧客にメールを送る」といった具体的な行動(アクション)へと繋がる「アクティブなスキル」へと進化していくでしょう 。
パーソナライズされたAI地図
将来的には、ユーザー一人ひとりの好みや仕事の進め方に合わせた「自分専用の知識地図」が自動で生成されるようになるかもしれません。あなたの過去のメールやドキュメントが、あなたを助ける強力な「スキル」としてAIの中に蓄積されていく世界です 。
結論:Corpus2Skillが切り拓く新しいAIのカタチ
AIが私たちの良きパートナーとなるためには、単に物知りであるだけでなく、情報の「探し方」や「整理のされ方」を理解している必要があります。Corpus2Skillは、そんなAIに「知性の地図」を授けるための鍵となる技術です 。
これまで「AIの回答がズレている」「マニュアルを読み込ませたのにうまく答えてくれない」と悩んでいた方は、ぜひこの「検索からナビゲーションへ」という新しい波を体験してみてください 。バラバラだった知識が、AIの手によって洗練された「スキル」へと変わるとき、あなたのビジネスやクリエイティビティは、また一段高いステージへと引き上げられるはずです。
参考資料
- Corpus2Skill (後編) - AIエージェントのための知識検索ガイド, https://shinichi.noguchi.jp.net/blog/2026-04-29-corpus2skill-kouhen.html
- Corpus2Skill (前編) - RAGの終焉とナビゲーションの時代, https://shinichi.noguchi.jp.net/blog/2026-04-29-corpus2skill-zenpen.html
- dukesun99/Corpus2Skill GitHub Repository, https://github.com/dukesun99/Corpus2Skill
- Don't Retrieve, Navigate: Distilling Enterprise Knowledge into Navigable Agent Skills for QA and RAG (arXiv), https://arxiv.org/abs/2604.14572
- Prompt Caching Infrastructure: LLM Cost and Latency Reduction Guide 2025, https://introl.com/blog/prompt-caching-infrastructure-llm-cost-latency-reduction-guide-2025
- WixQA: A Multi-Dataset Benchmark for Enterprise Retrieval, https://www.semanticscholar.org/paper/WixQA%3A-A-Multi-Dataset-Benchmark-for-Enterprise-Cohen-Burg/df26fb159ee3c22884a3b74f1459d54df6bb21d2
- The SKILL.md Pattern: How to Write AI Agent Skills That Actually Work, https://bibek-poudel.medium.com/the-skill-md-pattern-how-to-write-ai-agent-skills-that-actually-work-72a3169dd7ee
- Anthropic Skills API Documentation, https://www.firecrawl.dev/blog/agent-skills
- Corpus2Skill Technical Documentation and README, https://github.com/dukesun99/Corpus2Skill/blob/main/README.md
- Prompt Caching: Reducing LLM Costs by Up to 90%, https://medium.com/@pur4v/prompt-caching-reducing-llm-costs-by-up-to-90-part-1-of-n-042ff459537f
- How We Cut LLM Costs With Prompt Caching, https://projectdiscovery.io/blog/how-we-cut-llm-cost-with-prompt-caching
- Agent Skills and SKILL.md Standard, https://www.gitbook.com/blog/skill-md
- WixQA Benchmark Performance and Metrics, https://arxiv.org/html/2505.08643v1
- Semantic Caching for AI Cost Reduction, https://yuv.ai/blog/prompt-caching-cut-our-ai-costs-by-70


コメント