

超高速テキスト生成AI「DiffusionGemma」のPodcast
下記のPodcastは、Geminiで作成しました。
はじめに
人工知能(AI)の進化スピードは目覚ましく、日々私たちの常識を塗り替えるような技術革新が生まれています。2026年6月10日、Google DeepMindはテキスト生成の新たな地平を切り拓く実験的なオープンウェイトモデル「DiffusionGemma」を発表しました , 。このモデルは、これまでの大規模言語モデル(LLM)が採用していた「文字を1文字ずつ順番に出力する」というアプローチを根底から覆し、画像生成AIのように「文章のかたまりを同時に生成・洗練する」という全く新しい手法を採用しています 。これにより、特定のハードウェア環境下において従来のモデルを遥かに凌駕する、最大4倍もの超高速なテキスト生成能力を実現しました 。本レポートでは、AIに興味を持ち始めた初心者の方にも分かりやすいよう、この画期的な新技術の仕組み、驚異的なパフォーマンス、そしてその具体的なユースケースやトレードオフについて、丁寧に解説します。
従来のAIの限界とメモリ帯域幅の壁
最新技術の仕組みを深く理解するために、まずはこれまでのAIがどのように文章を作っていたのかを紐解いてみましょう。ChatGPTや従来のGemmaシリーズなどの一般的な言語モデルは、「自己回帰モデル(Autoregressive Model / ARモデル)」と呼ばれています 。この方式は、ユーザーから入力された指示(プロンプト)に対して、「次に来る確率が最も高い言葉(トークン)」を1文字ずつ順番に予測し、それを履歴に付け足してまた次の1文字を予測する、というプロセスをループさせています 。
この「1文字ずつ順番に書く」というアプローチは、非常に自然で高精度な文章を作成できるという大きな利点がある一方で、物理的な処理速度において致命的な弱点を抱えていました。それが「メモリ帯域幅の制限(メモリ・バンド幅のボトルネック)」と呼ばれる現象です 。AIが1文字を出力するたびに、グラフィックボード(GPU)などのプロセッサは、AIの頭脳にあたる巨大なモデルの重みデータをメモリから毎回丸ごと読み込み直さなければなりません 。どれだけプロセッサ自体の計算能力が高速であっても、この「メモリからデータを引き出す速度」が追いつかないため、プロセッサの処理コアは次のメモリ転送をただ待つだけの手持ち無沙汰な状態に陥ってしまいます 。特に、クラウドサーバーではなく個人のパソコン(ローカル環境)で1人のユーザーがAIを動かす場合、この非効率さは顕著になり、ハードウェアの持つ潜在的な能力がほとんど引き出せないという課題がありました 。
DiffusionGemmaの核心技術「Uniform State Diffusion」
このメモリ帯域幅の限界をスマートに突破するために開発されたのが、DiffusionGemmaの核となる「Uniform State Diffusion(均一状態拡散)」という技術です 。これは、私たちが日頃目にする画像生成AIの仕組みをテキストに応用したものです 。画像生成AIは、最初にザラザラとした砂嵐のようなノイズ画像を用意し、そこから段階的にノイズを取り除く(デノイズする)ことで綺麗なイラストを浮かび上がらせます 。DiffusionGemmaも全く同じプロセスを「言葉」に対して実行します 。
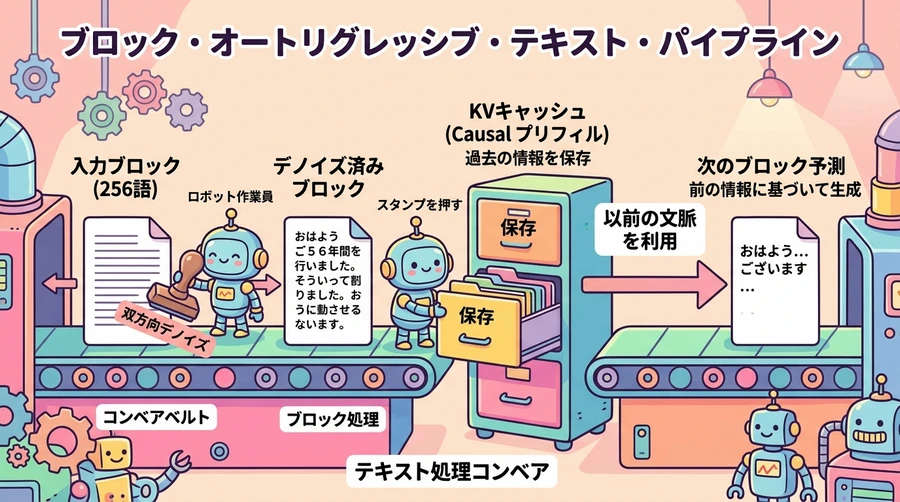
Uniform State Diffusionの具体的なプロセス
- ランダムなキャンバスの展開:AIは、最初に256文字(256トークン)分の枠を持った「プレースホルダー(文字の砂嵐)」のようなキャンバスを広げます 。
- 並列デノイジング(磨き上げ):AIはキャンバスの全体を何度もスキャンしながら、確率的に最も確信度の高い部分から少しずつ言葉を確定させていきます 。
- 全体のシャープ化:何回かの磨き上げのステップを経ることで、最初はバラバラだった意味をなさない文字の羅列が、まるでカメラのピントが合うように、一気にパッと意味の通じる美しい文章へと収束します。
この手法の最大の強みは、一度の処理で256文字という大量の計算をGPUに一括で任せられる点にあります 。これにより、ボトルネックは「メモリの読み込み速度」から「プロセッサの計算能力(コンピュート)」へと完全に移行します 。GPUの得意分野である並列処理を最大限に活かせるため、文字の生成スピードが爆発的に向上するのです 。
さらに、DiffusionGemmaは「双方向アテンション(Bidirectional Attention)」を採用しています 。従来の1文字ずつ書くAIは、左から右へと過去の文字しか見ることができませんでした 。しかし、双方向アテンションでは、キャンバス内のすべてのトークンが他のすべての位置のトークンと同時につながり、前後左右の文脈を一度に評価できます 。これにより、生成の途中で「文脈が崩れた」と判断した場合、その部分をもう一度ノイズに戻して正しい言葉に置き換える「リアルタイムのエラー自己修正(セルフコレクション)」が可能になりました。これは従来の自己回帰モデルには絶対に真似できない、非常に画期的な能力です 。
タイプライター方式(自己回帰)と超高速印刷機方式(デプロイ)の比較図

長文テキストも思いのまま!ブロック自己回帰デノイジングの連携
1回で処理できるキャンバスが256文字分だけであるとすれば、長大な物語や複雑なソースコードを書くことはできないのではないか、という疑問が生じるかもしれません。この問題を極めてエレガントに解決したのが、「ブロック自己回帰デノイジング(Block Autoregressive Denoising)」というハイブリッドな制御システムです 。
このシステムは、拡散モデルが持つ「ブロック単位の圧倒的な並列処理速度」と、自己回帰モデルが持つ「長い文章を破綻なく繋げるシーケンシャルな安定性」を巧みに融合させています 。
長文生成における処理のバトンリレー
- 初期プロンプトの読み込み(プレフィル):AIは、ユーザーが入力した指示内容(コンテキスト)を「因果的アテンション(Causal Attention)」によって効率的に読み込み、これを「KVキャッシュ」と呼ばれるメモリ本棚に一度だけしっかりと記憶します 。
- ブロック単位の拡散(デノイズ):次に、保存された記憶をもとにして、最初の256文字のキャンバスを双方向アテンションで高速に磨き上げ、確定させます 。
- 記憶の追記と次のブロックへの移行:確定した最初の256文字ブロックを再びKVキャッシュに追記して本棚に格納します 。そして、その直前のブロックの記憶を条件(コンテキスト)として引き継ぎながら、次の新しい256文字のキャンバスを広げてデノイズを行います 。
この「一気に出力して、記憶して、次のブロックに繋ぐ」というプロセスをリレーのように繰り返すことで、DiffusionGemmaはどれほど長い文章であっても、驚異的なハイスピードを維持したまま、文脈を乱さずに書き進めることができるのです 。
キャンバスの砂嵐から文字が浮かび上がるデノイジングのステップ

ブロック自己回帰デノイジングのバトンリレー
NVIDIAハードウェアにおける驚異的なパフォーマンスと導入方法
Google DeepMindは、この実験的なアーキテクチャを単なる理論に留めず、誰もが使える実用的なソフトウェアとして届けるため、半導体大手のNVIDIAとDay 0(発表初日)から緊密に最適化を行いました 。その結果、最新のプロセッサが持つ演算コア(テンサーコアなど)のパワーを限界まで引き出し、圧倒的なパフォーマンスを記録しています 。
以下の表は、各動作プラットフォームにおけるDiffusionGemmaの言葉の出力速度(トークン毎秒:1秒間に出力できる単語や文字の構成単位の数)を示したものです , 。
| 動作環境・グラフィックボード (GPU) | 1秒間あたりの文字生成速度(トークン毎秒) | 主な特徴とターゲット層 |
| NVIDIA H100 Tensor コア | 1,000トークン以上 / 秒 , | 大規模な研究開発やエンタープライズ向けの、最高峰の超高速演算能力環境 |
| NVIDIA GeForce RTX 5090 | 700トークン以上 / 秒 , | 一般のAI愛好家や個人開発者が手に入れられる、最高峰の一般向けローカルグラフィックボード , |
| NVIDIA DGX Spark | 150トークン / 秒 | Grace Blackwell Superchipを搭載した、個人利用も可能なデスクトップAIスーパーコンピュータ |
この圧倒的な処理能力を、クリエイターや研究者たちはすぐに自身の環境へ導入することができます。DiffusionGemmaは、発表と同時に以下の主要なオープンソースエコシステムやツールとの連携がサポートされました , 。
- Unsloth & Hugging Face:Unslothを使用することで、通常よりも少ないメモリ消費で最大2倍高速にモデルを動かしたり、ローカルPC用のGGUF形式への変換、さらには個人でのファインチューニング(追加学習)を簡単に行うことができます 。また、Hugging Face上には、公式のモデルデータセットが誰でも利用可能な形でコレクションとして公開されています 。
- vLLM & vime:高速な推論サーバーとしてコミュニティで最も支持されているvLLMも、発表直後からDiffusionGemmaをネイティブサポートしています 。さらに、vLLMのエコシステム内で公開された最新のポストトレーニング用フレームワークである「vime」を使用すれば、複数のGPUにまたがる分散環境下でも安定して高速な学習と推論の整合性を保つことができます 。
- NVIDIA NIM:企業向けの本格的な展開には、コンテナ化されたマイクロサービスであるNVIDIA NIMが最適です 。以下のPythonコードのように、使い慣れたOpenAI互換のシンプルなAPIを叩くだけで、数行で超高速な拡散テキスト生成システムをローカルサーバー上に立ち上げることができます 。
Python
from openai import OpenAI
# ローカルに立ち上げたNIMサーバーに接続します
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="not-required"
)
# テキスト拡散モデルを呼び出して、詩を作ってもらいます
response = client.chat.completions.create(
model="google/diffusiongemma-26b-a4b-it",
messages=,
max_tokens=256
)
print(response.choices.message.content)
ユースケースの探究:数独ソルバーに見る双方向文脈と自己修正の圧倒的優位性
DiffusionGemmaの「双方向アテンション」と「自己修正」という特徴が、従来のAIに比べてどれほど優れているのかを示す、極めて興味深い具体例が「数独(Sudoku)パズル」の攻略実験です 。
数独は、9×9のグリッドに1から9までの数字を、縦・横・ブロックですべて重複しないように埋めていく数学パズルです。従来の1文字ずつ文字を出力するAI(自己帰帰モデル)にとって、数独を解くことは悪夢のような難題でした 。なぜなら、1つのマスに入力する数字を決めるためには、まだ埋めていない未来の空欄や、右下、左上といった盤面全体のあらゆる交差ルールを同時に考慮しなければならないからです 。自己回帰モデルは左から右へと進むことしかできず、途中で「あ、この数字をここに置くと、後で矛盾が生じる」と気付いても、過去に戻って修正することができません 。
Googleの研究チームは、JAXベースのモジュール型研究用ツールボックス「Hackable Diffusion」を用いて、DiffusionGemmaに数独のデータセットを学習(ファインチューニング)させる実験を行いました 。その結果、AIの能力に劇的な変化が現れました。
- ファインチューニング前のベースモデル:数独を解くためのルールや盤面の把握ができず、成功率はほぼ 0% でした 。
- ファインチューニング後のDiffusionGemma:一変して、パズルを正しく解き明かす成功率は 80% にまで急上昇しました 。
この実験において、DiffusionGemmaは盤面全体を一つの大きなキャンバスとして同時に見渡し、双方向アテンションによってすべてのマスの依存関係を並行して考慮しました 。そして、確信度の低い数字を検出した場合には、そのマスのデータを「再ノイズ化(Re-Noising)」して消し去り、その場で正しいと思われる別の数字に書き換えるという、まさに人間が消しゴムを使ってパズルを解くようなアプローチを実践したのです 。さらに、盤面が安定して全ての制約が解決されたとAIが判断した時点で、規定のステップ数を待たずに処理を切り上げる「適応的早期終了(Adaptive Early Stopping)」が働き、わずか12ステップという圧倒的な短時間で正解に到達することに成功しました 。
標準モデルとのトレードオフおよび今後の展望
DiffusionGemmaは、260億パラメータ(26B)の規模を持つ「Gemma 4 26B A4B MoE(Mixture of Experts / 専門家たちの混合)」という最先端の脳みそをベースに構築されています 。このアーキテクチャの秀逸な点は、必要なときにだけ特定の専門家グループを呼び出して計算を行うため、実際に推論を行う瞬間(実行時)にアクティブになるパラメータの数はわずか38億(3.8B)に抑えられている点です 。そのため、重みを量子化(データの軽量化)することで、家庭用の高性能なパソコンが備える18GBのグラフィックメモリ(VRAM)の制限の中に美しく収まり、ローカル環境での高速な動作を可能にしています 。
しかし、開発元のGoogle DeepMind自身も指摘している通り、この驚異的なスピードを手に入れるためには、いくつかの明確なトレードオフ(妥協点)を受け入れる必要があります 。
トレードオフと使用上のポイント
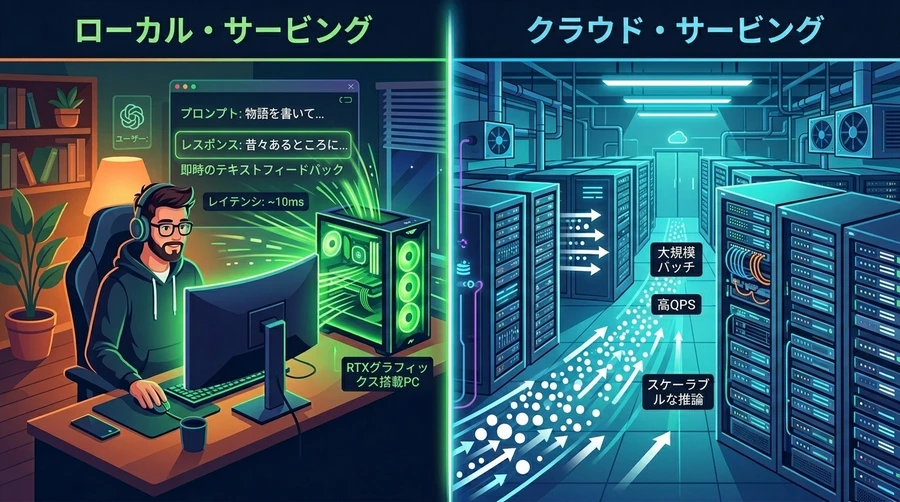
- 生成クオリティのわずかな低下:DiffusionGemmaの出力する文章の総合的な知的な質や表現力は、従来の1文字ずつ慎重に書き上げる「標準のGemma 4モデル」に比べると、いくつかの評価テストにおいて少しだけ下回っています 。そのため、何よりも文章の美しさや正確な知識の出力が最優先されるビジネス文書の作成などのタスクには、従来の自己回帰モデルを使用することが推奨されます 。また、ローカルで動く知的なマルチモーダル(画像や音声の直接処理)モデルとしては、軽量ながら最先端の推論が可能な「Gemma 4 12B」などもリリースされており、用途に合わせた適切なモデル選択が必要です 。
- クラウドでの大量処理における逆転現象:1秒間に何千もの問い合わせが同時に殺到する大規模なクラウドサーバー環境(高QPSワークロード)では、従来の自己回帰モデルの方が、ハードウェアを隙間なく満たして効率的に並行処理できるため、結果としてコストパフォーマンスが良くなります 。DiffusionGemmaの並列デコードによる爆速の恩恵は、少人数や個人のパソコンで動かす「低コプロセッサ・低並行性」のローカル環境において最も強く発揮されます 。
- 入力データの対応範囲:DiffusionGemmaは、テキスト、画像(様々な縦横比や解像度に対応)、そして動画の入力をネイティブに受け取り、その内容を理解してテキストで出力する「マルチモーダル能力」を備えています 。ただし、音声データ(オーディオ入力)の直接の読み込みには対応していないため、マイクからの声などを直接入力するような用途には使えません 。
これらの特性や長所・短所を綺麗に整理し、どのようなパラメータ設定で動かすのが最もパフォーマンスを最大化できるかについて、公式に推奨されている設定値を以下の表にまとめました 。
ローカル環境とクラウド環境における処理効率のトレードオフ
推奨される動作設定パラメーター
| 設定項目 (パラメータ) | 公式推奨値 | 設定の意図と詳細な仕組み |
| 最大デノイジング・ステップ数 | 48 | キャンバス1ブロックあたりに許容する、最大の磨き上げ(デノイズ)回数の上限です。簡単な作業やコード生成では、自動的に12〜16ステップ程度で早期に終了します 。 |
| 温度減衰スケジュール (Temperature) | Linear 0.8 -> 0.4 | 出力の創造性とランダムさを制御します。生成の初期フェーズ(0.8)では高い自由度で多様なアイデアを探索し、終盤(0.4)にかけて数字を低くして最も確実な言葉をキャンバスに固定させます , 。 |
| 適応的早期終了の閾値 (Entropy) | エントロピー閾値:0.005 | キャンバス全体の文字に対する「迷い(エントロピー)」の平均値がこの閾値を下回り、なおかつ2回連続でAIが予測した文章が完全に一致した場合に、ステップの途中でも処理を早期に切り上げて応答速度を上げます , 。 |
| トークン選択の不確実性境界 | エントロピー境界:0.1 | 各ステップにおいて、AIが極めて高い自信(不確実性が0.1以下)を持っている言葉だけをキャンバスにロックして保存し、少しでも確信が持てないトークンは容赦なく再び砂嵐(ノイズ)に戻して、次のステップで再推論します , 。 |
結論
Google DeepMindが開発したDiffusionGemmaは、従来の「1文字ずつタイプライターで打つ」テキスト生成から、「キャンバス全体を一気に印刷し、リアルタイムに何度も推敲する」という新たな生成プロトコルへの道を切り拓きました 。双方向アテンションがもたらす完璧なフォーマット処理能力や、数独のようなグローバルな整合性を必要とする難解なタスクに対する卓越した能力は、拡散テキスト生成モデルの計り知れない可能性を示しています 。
標準の自己回帰モデルに比べて知的な性能においてわずかな譲歩があるものの、専用のGPUを搭載したパーソナルな開発環境やオンデバイス環境においては、文字通り「瞬きする間」に数百もの文字が生成される極上のレスポンスを提供します 。リアルタイムのインラインコード編集、推敲アシスタント、低遅延な自律型AIエージェントの構築など、ローカルの制約を打ち破りたい多くのエンジニアやクリエイターにとって、DiffusionGemmaはこれからのデスクトップAI開発における最強の頼れる相棒となるでしょう 。
参考資料
- Google Launches DiffusionGemma with 4x Faster Text Generation, https://www.investing.com/news/stock-market-news/google-launches-diffusiongemma-with-4x-faster-text-generation-93CH-4735827
- Google Debuts DiffusionGemma for Faster Text Generation, https://letsdatascience.com/news/google-debuts-diffusiongemma-for-faster-text-generation-fb1eee25
- Run DiffusionGemma on NVIDIA for Developer-Ready, High-Throughput Text Generation, https://developer.nvidia.com/blog/run-diffusiongemma-on-nvidia-for-developer-ready-high-throughput-text-generation/
- DiffusionGemma: 4x faster text generation, https://blog.google/innovation-and-ai/technology/developers-tools/diffusion-gemma-faster-text-generation/
- DiffusionGemma: The Developer Guide, https://developers.googleblog.com/diffusiongemma-the-developer-guide/
- Hacker News Discussion on DiffusionGemma: 4x Faster Text Generation, https://news.ycombinator.com/item?id=48478471
- NVIDIA Accelerates Google DeepMind's DiffusionGemma for Local AI, https://blogs.nvidia.com/blog/rtx-ai-garage-local-gemma-diffusion/
- Google releases DiffusionGemma, an experimental 26B MoE model that generates text blocks in parallel, https://digg.com/ai/z4mvl1gb
- Reddit LocalLLaMA - DiffusionGemma: 4x Faster Text Generation, https://www.reddit.com/r/LocalLLaMA/comments/1u26s8n/diffusiongemma_4x_faster_text_generation/
- Reddit Singularity - Google releases DiffusionGemma, new experimental..., https://www.reddit.com/r/singularity/comments/1u27fga/google_releases_diffusiongemma_new_experimental/
- DiffusionGemma model overview, https://ai.google.dev/gemma/docs/diffusiongemma
- DiffusionGemma model card, https://ai.google.dev/gemma/docs/diffusiongemma/model_card
- Google Developers Blog - An Important Update: Transitioning Gemini CLI to Antigravity CLI, https://developers.googleblog.com/an-important-update-transitioning-gemini-cli-to-antigravity-cli/
- vLLM Blog - Announcing vime, https://vllm.ai/blog/2026-06-09-announcing-vime
- Hugging Face - DiffusionGemma Collection, https://huggingface.co/collections/google/diffusiongemma
- Google Blog - Introducing Gemma 4 12B: a unified, encoder-free multimodal model, https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12b/

コメント