

NVIDIAの超巨大AI「Nemotron 3 Ultra」のPodcast
下記のPodcastは、Geminiで作成しました。
はじめに:AIエージェント時代の到来と新しい課題
人工知能(AI)の世界は、今や「単に質問に答えるだけのチャットボット」から、自立して複雑な仕事をこなす「AIエージェント」の時代へと急速にシフトしています 。AIエージェントとは、人間から大まかな指示を受け取ると、自分で必要なツールを選び、プログラムを書いて実行し、エラーが出たら自己修正しながら目標を達成する persistent(永続的)なAIシステムのことです 。
しかし、AIエージェントが長時間にわたって何十回、何百回とツールを呼び出しながら動き続けると、いくつかの大きな壁に突き当たります 。
その一つが「ゴール・ドリフト(目的の喪失)」です 。これは、AIがやり取りを重ねて文脈が長くなる(コンテキストが爆発する)につれて、最初に与えられた本来の目的を途中で見失ってしまう現象です 。
もう一つが「思考税(Thinking Tax)」と呼ばれるコストの問題です 。ちょっとした簡単な作業(サブタスク)を実行するだけでも、従来の巨大なAIモデルはすべてのネットワークをフル稼働させていたため、莫大な計算パワー(電気代やクラウド費用)と時間がかかっていました 。
こうした課題を劇的に解決し、AIエージェントが「速く」「安く」「賢く」働き続けられるように設計されたのが、NVIDIAが2026年6月4日に発表した最新のオープン言語モデル「Nemotron 3 Ultra(ネモトロン・スリー・ウルトラ)」です 。本報告書では、この革新的なAIの仕組みや実力について、初心者の方にも分かりやすく丁寧に解説します。
【自律型AIエージェントの活動イメージ】

第1章 Nemotronシリーズの歴史と進化の道のり
NVIDIAといえばグラフィックボード(GPU)のメーカーとして有名ですが、実は最先端のAIモデルを開発する強力な開発者でもあります 。Nemotron(ネモトロン)は、NVIDIAが企業向けに提供している高性能なAIモデルファミリーの名称です 。その進化の歴史を振り返ることで、今回登場した「Ultra」の位置づけがより深く理解できます。
- 2023年11月:Nemotron-3 8Bの登場NVIDIAが初めて公開したNemotronブランドのモデルです 。企業用のチャットボットやコパイロットを開発するための、80億(8B)パラメータのコンパクトなモデルでした。このシリーズには、質問回答に特化した「QA-4k」や、対話形式でアライメントされた「Chat-SFT」などがあり、NVIDIA NeMoフレームワークで動かす基盤となりました 。
- 2025年:ハイブリッド構造へのシフト(Nemotron-H / Nano 2)2025年に入ると、NVIDIAは処理を劇的に高速化するため、従来のアテンション技術と最新の「Mamba(マンバ)」技術を組み合わせた「ハイブリッドモデル」の研究開発を進めました 。
- 2025年12月:新しい「Nemotron 3」ファミリーの始動ここで大きな転換点を迎えます 。NVIDIAは、AIエージェント向けに特化したオープンモデルとして「Nemotron 3」ファミリーを発表しました 。最初にリリースされたのが、スマートフォンやローカルPCでも動く、総パラメータ数300億(30B)の超軽量モデル「Nemotron 3 Nano」でした , 。
- 2026年3月:中型モデル「Nemotron 3 Super」のリリース総パラメータ数1200億(120B)、実際に動くアクティブパラメータ数120億(12B)の「Super」がリリースされました 。
- 2026年6月4日:ついに最高峰「Nemotron 3 Ultra」が誕生そして今回、シリーズの集大成であり、最も高い知能を持つ超大型モデル「Nemotron 3 Ultra」が満を持して登場しました 。
これら「Nemotron 3」シリーズのスペックを一覧表で比較してみましょう。
| モデル名 | 総パラメータ数 | アクティブパラメータ数 | 主な用途・特徴 |
| Nemotron 3 Nano | 316億(30Bクラス) , | 32億(3.2B) , | ローカルPCやエッジデバイス向け、1M長文対応 |
| Nemotron 3 Super | 1200億(120B) , | 120億(12B) , | コストパフォーマンス重視のビジネスエージェント向け |
| Nemotron 3 Ultra | 5500億(550B) | 550億(55B) | 最先端の推論、プログラミング、超高難度の調査向け |
第2章 基本スペックと「混合専門家(MoE)」の驚くべきスケール
Nemotron 3 Ultraは、総パラメータ数が「5500億(550B)」という驚異的なスケールを持っています 。一般的なオープンAIモデルが数百億パラメータ程度であることを考えると、その巨大さが分かります。
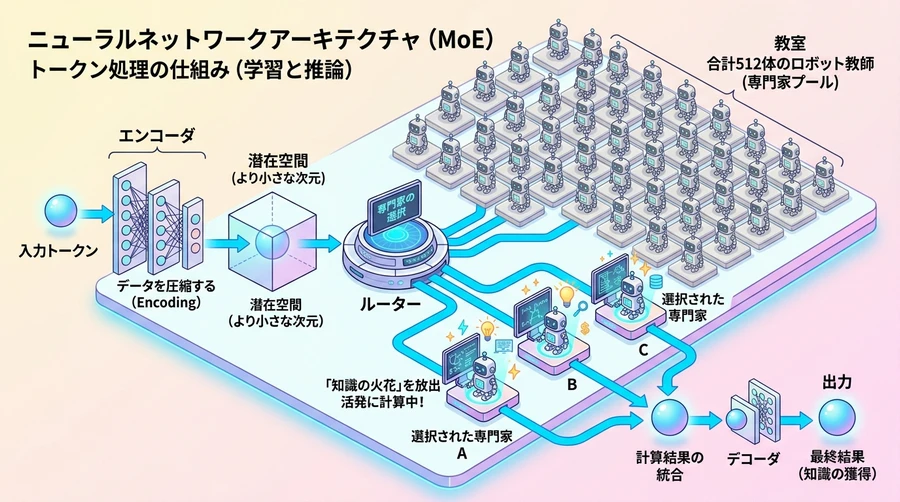
しかし、パラメータが大きくなると、動かすためのサーバー費用が跳ね上がってしまいます。そこで採用されているのが「混合専門家(Mixture of Experts:MoE)」という設計思想です 。
MoEとは、AIの内部を「特定の分野に強い専門家(エキスパート)」の集まりにする仕組みです , 。Nemotron 3 Ultraの内部には、1つのレイヤーの中に512人もの専門家が配置されています 。
ユーザーから質問が届くと、AIの「ルーター(交通整理係)」が、その質問を解くのに最適な専門家を自動的に選び出します , 。
このモデルでは、5500億パラメータのうち、一度に働く(アクティブになる)のは「550億パラメータ(全体の10%)」だけです , 。
この仕組みにより、AI全体としては「5500億パラメータ分の膨大な知識と深い思考力」を蓄えながらも、実際に動かすときは「550億パラメータ分の軽いコストとハイスピード」で処理できるという、夢のような両立を果たしているのです 。
さらに、一度に読み込める文字の量(コンテキストウィンドウ)は、最大で100万(1M)トークンに達します。これは、日本語の本に換算すると数冊分に相当し、開発中のプログラムコード全体や、何十枚もの論文・レポートを一度に丸ごと読み込ませて分析させることが可能です 。
第3章 なぜ速くて賢いの?Nemotron 3 Ultraを支える5つの最先端技術
Nemotron 3 Ultraが驚異的なスピードと高い知能を両立している背景には、NVIDIAが詰め込んだ5つの革新的なアーキテクチャ(設計)があります , 。
1. ハイブリッド Mamba-Attention(マンバ・アテンション)
これまでのAIの多くは「トランスフォーマー」と呼ばれる、文章のつながりを理解する仕組み(アテンション)を使っていました。しかし、アテンションには「文章が長くなればなるほど、計算量が指数関数的に増えて、処理がどんどん遅くなる」という弱点がありました 。
そこでUltraは、このアテンション層と、驚異的な処理スピードを誇る状態空間モデル「Mamba-2(マンバ・ツー)」層を交互に組み合わせる「ハイブリッド構造」を採用しました , 。これにより、100万トークンの長大なテキストを入力しても、一切処理が遅くならず、高い正確性を維持したまま高速で処理できるようになりました 。
2. LatentMoE(レイテント・エムオーイー)
MoE(混合専門家)モデルでは、多数の専門家たちの間でデータを行き来させる必要がありますが、このデータの通信量が大きすぎて、GPU(半導体)の内部で通信渋滞(ボトルネック)が発生することが大きな悩みでした。
これを克服するために開発されたのが「LatentMoE」技術です 。これは、データを専門家に届ける前に、一度「ぎゅっとコンパクトに圧縮(ダウンプロジェクション)」してから通信を行い、計算が終わった後に元の大きさに戻す(アッププロジェクション)というアプローチです 。
AIモデルの本来のデータ次元数を $d$、圧縮後の次元数を $\ell$ とすると、Nemotron 3 Ultraでは $d = 8192$、$\ell = 2048$ に設計されています 。これにより、通信にかかる負荷(ルーティングされるデータ量)を次のように大幅に削減しています。
つまり、通信に必要な負荷を約4分の1にカットすることに成功しました 。
この削減によって浮いた分の計算パワーを、さらに多くの専門家を配置することや、同時に多くの専門家(上位22人のエキスパート)を動かすことに再投資したため、知能とスピードを劇的に向上させることが可能になりました。
3. マルチトークン予測(MTP)
一般的なAIは、「私は」の後に続く言葉を「りんご」「を」「食べます」と、1語ずつ順番に考えて出力します。
しかし、Nemotron 3 Ultraには「マルチトークン予測(MTP)」という技術が組み込まれており、一度に2語以上の言葉(トークン)を同時に予測して出力します 。これにより、あたかもAIが「次に言うべきことの文脈を下書きしながら話す」ような状態になり、文章を生成するスピード(トークンスループット)が跳ね上がります。
4. NVFP4精度(4ビット浮動小数点数)
AIが計算を行う際、扱う数字の細かさ(精度)を「16ビット」から、NVIDIAが開発した極めて効率的な「4ビット(NVFP4精度)」へと軽量化して事前学習を行っています。
これにより、必要なメモリ容量を大幅に削減し、高価なGPUを節約しながら、極めて高速にAIを動作させることができるようになりました 。
5. 推論バジェット(思考時間)のコントロール機能
簡単な質問には「一瞬で答える」、難しい数学やロジックのパズルには「時間をかけて深く考える(推論バジェットを増やす)」という調整が、プログラムの設定(フラグ)一つで簡単に行えるようになっています 。これにより、無駄なクラウド費用(思考税)を支払う必要がなくなります 。
【LatentMoEのデータの圧縮と伝達プロセス】
第4章 驚異の性能をデータで検証!最新ベンチマークの比較
言葉の説明だけでなく、実際の性能評価(ベンチマーク)の結果を見れば、Nemotron 3 Ultraがいかに傑出したモデルであるかが分かります 。
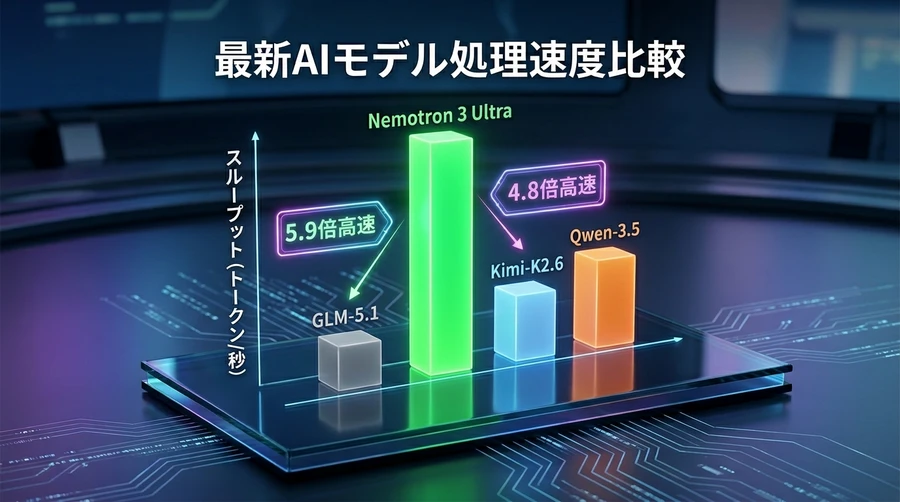
まず、何万文字もの長い文章をAIに読み込ませて、長大な回答を出力させる「長文スループット(1秒間あたりの文字生成量)」のテスト結果を比較してみましょう 。8000文字を入力し、6万4000文字を出力させる過酷な環境において、Ultraは他モデルを圧倒しています 。
- GLM-5.1-754B(他社の大型モデル)に比べて、約5.9倍高速
- Kimi-K2.6-1T(他社の超大型モデル)に比べて、約4.8倍高速
- Qwen-3.5-397B(他社の最新モデル)に比べて、約1.6倍高速
この圧倒的なスピードのおかげで、何度もやり取りを繰り返すAIエージェントの作業完了コスト(料金)を、従来のオープンモデルに比べて最大30%も削減することに成功しています 。
また、AIの総合的な知能の高さを評価する「Artificial Analysis Intelligence Index」のスコア比較は以下の通りです 。
| モデル名 | 総合知能スコア(Intelligence Index) | ポジション |
| Nemotron 3 Ultra | 47.7 | 米国製オープンモデルで堂々の第1位 , |
| Gemma 4 31B | 39.0 | Googleが開発した最新モデル |
| Nemotron 3 Super | 36.0 | NVIDIAの中型モデル , |
| GPT-OSS 120B | 33.0 | 代表的なオープンソースモデル |
このスコアからも分かるように、Nemotron 3 Ultraは、誰でも自由にダウンロードして自前の環境で動かせる「オープンモデル」としては、世界最高峰の頭脳を持っています 。
さらに、システム開発(プログラミング)の能力を評価する「SWE-Bench Verified」では71.9%という極めて高い正解率を記録しており、複雑なコードの自動修正を任せるのにも十分な実力を備えています , 。
【他モデルとの処理速度(スループット)の比較】
第5章 具体的なビジネス活用法と最先端のユースケース
これほど「速くて」「賢く」「長文を覚えられる」Nemotron 3 Ultraは、私たちの実務においてどのような変化をもたらすのでしょうか。具体的な活用例を4つ紹介します 。
1. 24時間走り続ける「自律型プログラマー(Coding Agent)」
これまでのコーディング支援AIは、1行コードを書いては人間に確認を求める「助手」のような存在でした。
しかし、Nemotron 3 Ultraを搭載した開発エージェント(「Kilo Code」や「Claude Code」など)は、開発プロジェクト全体のファイルを頭の中に読み込み、自分で新しいコードを書き、テストプログラムを実行し、エラーが出たら自動で原因を特定して修正する、という一連のステップを人間の手を借りずに自動で完遂できます , 。
開発者向けツール「CodeRabbit」のテストでは、従来の開発ワークフローと比較して処理速度を16%も短縮したことが実証されています 。
2. 複数のAIを束ねて仕事をこなす「AIの指揮者(Orchestration)」
大きなビジネスプロセスを自動化する場合、1つのAIがすべてをやるのではなく、役割を細分化した複数の「部下AI」を作って動かすのが効率的です。
Nemotron 3 Ultraは、これら複数の部下AI(情報収集、分析、文書作成、校正など)に適切な仕事を割り振り、進行を管理する「プロジェクトリーダー(指揮者)」として、非常に優れた調整能力を発揮します 。
3. 数千ページの書類を一度に読み解く「深層調査(Deep Research)」
学術論文、分厚い契約書、特許資料、企業の財務報告書など、数千ページに及ぶ膨大な資料を一度にすべて頭の中に読み込ませて、矛盾点を見つけたり、複雑なデータを集計・要約させたりすることができます 。 100万トークンの記憶枠をフルに活かして、資料全体の文脈を理解しながら、高いレベルの回答を導き出します 。
4. 信頼性の高い「法律・金融実務の自動化」
Nemotron 3 Ultraの事前学習には、40億トークンの高品質な「法律関連データ(契約書や判例)」や、350億トークンの「Wikipedia事実データ」が追加で注入されています 。これにより、嘘(ハルシネーション)を極力排除し、事実に基づいた高度な法的・金融的な事務処理を行うことが可能になっています 。
また、本モデルは日本語を含む10種類の主要な多言語を公式にサポートしているため、日本のビジネスシーンや公的書類の読み込み・作成にもその強みを遺憾なく発揮します 。
【複数の部下AIを統率するプロジェクトリーダーAI】

第6章 モデルの公開バリエーションと導入ガイド
NVIDIAは、この高性能なAIモデルをオープンソースとして一般公開しており、誰もが自由にダウンロードして自前の環境で動かすことができます 。用途に合わせて、以下の4種類の「チェックポイント(モデルのバリエーション)」が用意されています , 。
- Nemotron 3 Ultra 550B-A55B NVFP4(軽量高速版)軽量で動作が非常に速い、実務に最もおすすめの推奨バージョンです 。
- Nemotron 3 Ultra 550B-A55B BF16(高精度フルスペック版)通常規格の16ビットで出力される、最も正確で賢いバージョンです 。
- Nemotron 3 Ultra 550B-A55B Base BF16(基礎モデル)追加の学習をしていない、ベースとなる状態のモデルです。独自のデータでAIを鍛え直したい開発者向けです 。
- Nemotron 3 Ultra 550B-A55B GenRM(報酬モデル)AIの回答の良し悪しを採点するための特殊なモデルで、AIの訓練(強化学習)のプロセスで使用されます 。
導入のための推奨ハードウェア
BF16版(標準バージョン)を自社のサーバーで動かすためには、非常に強力なグラフィックボード(GPU)が必要になります 。最低でも以下のいずれかの構成が必要になります 。
- NVIDIA H100(80GB)× 16枚
- NVIDIA H200 × 8枚
- NVIDIA Blackwell(GB200 / B200 / GB300 / B300)× 8枚
軽量なNVFP4版であれば、さらに少ない台数(例えばH100×8枚や、B200×4枚)で稼働させることができます。
また、個人開発者や少規模なテストを行いたい場合は、AIを簡単に動かせるシステム「vLLM」や「SGLang」、あるいはOpenRouterなどのクラウドAPI経由で、サーバーを自前で用意せずに「無料枠」や低コストで手軽に体験することも可能です。
おわりに
NVIDIAの「Nemotron 3 Ultra」は、単に質問に賢く回答するだけのAIを超え、人間のように自律して動き続ける「AIエージェント」を支えるために、細部までこだわり抜いて設計された最先端のインフラ技術です , 。
「Mamba-Attention」や「LatentMoE」といった数々の最新の仕組みを駆使することで、これまでにない「超高速」「超長文処理」「圧倒的な低コスト」を実現しています , 。 すべてのデータや設計図がオープンソースとして公開されているため、特定の企業のサービスに依存することなく、安全に自社専用のスーパーAIエージェントを構築・カスタマイズすることができます 。
これから訪れるAIエージェント社会の推進力として、Nemotron 3 Ultraは開発者や企業に大きな変革をもたらしてくれるでしょう。
参考資料
- NVIDIA Nemotron 3 Ultra now available on Amazon SageMaker JumpStart, https://aws.amazon.com/blogs/machine-learning/nvidia-nemotron-3-ultra-now-available-on-amazon-sagemaker-jumpstart/
- OpenRouter - NVIDIA: Nemotron 3 Super 120B (Free), https://openrouter.ai/nvidia/nemotron-3-super-120b-a12b:free
- NVIDIA Developer Blog - NVIDIA Nemotron 3 Ultra Powers Faster, More Efficient Reasoning for Long-Running Agents, https://developer.nvidia.com/blog/nvidia-nemotron-3-ultra-powers-faster-more-efficient-reasoning-for-long-running-agents/
- NVIDIA Research - Nemotron 3 Ultra, https://research.nvidia.com/labs/nemotron/Nemotron-3-Ultra/
- OpenRouter - NVIDIA: Nemotron 3 Ultra 550B (Free), https://openrouter.ai/nvidia/nemotron-3-ultra-550b-a55b:free
- Ollama Library - nemotron-3-ultra, https://ollama.com/library/nemotron-3-ultra
- CodeRabbit Blog - Nemotron 3 Ultra Release, https://www.coderabbit.ai/blog/nemotron-3-ultra-release
- Azure AI Model Catalog - Nemotron-3-8B-QA-4k, https://ai.azure.com/catalog/models/Nemotron-3-8B-QA-4k
- Wikipedia - Nemotron, https://en.wikipedia.org/wiki/Nemotron
- NVIDIA NGC Model Catalog - Nemotron-3-8B-Base-4k, https://catalog.ngc.nvidia.com/orgs/nvidia/teams/nemo/models/nemotron-3-8b-base-4k
- Azure AI Model Catalog - Nemotron-3-8B-Chat-SFT, https://ai.azure.com/catalog/models/Nemotron-3-8B-Chat-SFT
- Nemotron Model Family, https://nemotron-ai.com/
- OpenRouter - NVIDIA: Nemotron 3 Ultra 550B (Free) Benchmarks, https://openrouter.ai/nvidia/nemotron-3-ultra-550b-a55b:free/benchmarks
- Hugging Face - NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16, https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16
- note - NVIDIA Nemotron-3-Nano-30B 日本語, https://note.com/catap_art3d/n/ne965e3410fbb
- NVIDIA Developer Blog - Introducing Nemotron 3 Super, https://developer.nvidia.com/ja-jp/blog/introducing-nemotron-3-super-an-open-hybrid-mamba-transformer-moe-for-agentic-reasoning/
- AI Revolution - Nemotron 3 Nano Omni とは?, https://ai-revolution.co.jp/media/what-is-nemotron-3-nano-omni/
- NVIDIA Nemotron 3 Ultra Technical Report PDF, https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Ultra-Technical-Report.pdf
- BuildFastWithAI - NVIDIA Nemotron 3 Ultra Review 2026, https://www.buildfastwithai.com/blogs/nvidia-nemotron-3-ultra-review-2026
- Hugging Face - NVIDIA-Nemotron-3-Ultra-550B-A55B-Base-BF16, https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-Base-BF16
- vLLM Blog - Announcing Day-0 Support for NVIDIA Nemotron 3 Ultra on vLLM, https://vllm.ai/blog/2026-06-04-nemotron-3-ultra-vllm


コメント
「Nemotron 3 Ultra」の解説、とてもわかりやすかったです。特に、AIエージェントが長時間動き続けると目的を見失ってしまう「ゴール・ドリフト」という問題には、なるほどと納得しました。5500億パラメータという規模でありながら、必要な部分だけを動かす工夫でコストを抑えているというのも、現実的で素晴らしいですね。こうした技術の進歩を聞くと、AIがもっと身近で頼れる存在になる日も近いと感じます。ちなみに、私のように音声でメモを取ることが多い人間には、shownotes generatorのようなツールも、AI時代の便利な相棒になってくれそうです。