

- 「Gemma 4 12B Coder」のPodcast
- 1. はじめに:なぜ今、自宅のPCで動かす「ローカルAI」が注目されているのか
- 2. 名前の謎を解き明かす!「gemma-4-12B-coder-fable5-composer2.5-v1-GGUF」の正体
- 3. Googleの最新技術「Gemma 4 12B」がもたらしたエンコーダーフリー統合アーキテクチャの衝撃
- 4. 賢さの秘密は「2人のAI先生」!Composer 2.5とFable 5による革新的な検証済思考学習
- 5. 初心者でも安心!PCスペックに合わせたおすすめの「量子化サイズ」とメモリ管理
- 6. 今日から始めるローカル開発!「llama.cpp」を使った簡単な導入手順と活用法
- 7. 実務での応用、注意すべき点、そしてローカルAIが描く開発の未来
- 8. まとめ
- 参考資料
「Gemma 4 12B Coder」のPodcast
下記のPodcastは、Geminiで作成しました。
1. はじめに:なぜ今、自宅のPCで動かす「ローカルAI」が注目されているのか
システム開発やプログラミング学習において、AIアシスタントの支援を受けることが当たり前の時代になりました。多くの方々が最初に思い浮かべるのは、ChatGPTやClaudeといったクラウド型のAIサービスでしょう。しかし、これらのクラウドサービスには「毎月のサブスクリプション料金が発生する」「インターネット接続が切断されると利用できない」という実用上の制約があります。
さらに深刻な問題として、開発中の機密性の高いソースコードや独創的なビジネスアイデアが外部のサーバーに送信され、プライバシーや情報セキュリティ上のリスクを誘発する懸念が常に付きまといます。このようなクラウドサービスの限界を打開し、個人のPC環境を完全に自立した「最強の開発室」へと変貌させるのが、PC内部だけで独立して動作する「ローカルAI(ローカルLLM)」です。
一度環境を構築してしまえば、完全オフライン、利用料金ゼロ、そして究極のデータ秘匿性を維持しながら、24時間稼働する自分専用の知的なコーディングパートナーを手に入れることができます。現在、オープンソースコミュニティやAI開発者の間で最も注目されているのが、Googleの最新鋭AIモデル「Gemma 4 12B」をベースにし、2つのトップクラスコーディングAIから英才教育を受けた「gemma-4-12B-coder-fable5-composer2.5-v1-GGUF」です。本稿では、このスーパーモデルがなぜこれほどまでに優秀なのかという技術的仕組みから、初心者でも今日から起動できる具体的な手順まで、分かりやすく丁寧に解説します。
2. 名前の謎を解き明かす!「gemma-4-12B-coder-fable5-composer2.5-v1-GGUF」の正体
一見すると非常に長く、呪文のように見えるこのモデル名ですが、実はパーツごとに極めて重要な意味が込められています。開発者が自分に最適なAIモデルを選択できるよう、この名称を5つのブロックに分解して解説します。
- Gemma 4 12B(ベースモデル):Google DeepMindが2026年6月に発表した最新世代のオープンAIモデル「Gemma 4」シリーズの120億パラメータ(12B)版を指しています。普通のノートPCでもスムーズに動作し、かつ高度な知性を発揮できる「極めてバランスの良い中型サイズ」です。
- coder(コーディング特化):プログラミング言語の理解、特にPythonの実装や複雑なアルゴリズム問題の解決能力を限界まで高めるため、特別な追加学習(ファインチューニング)が施されていることを表します。
- fable5-composer2.5(2つの強力な先生):最前線で活躍するトップクラスのコーディングAIである「Composer 2.5」および「Fable 5」が導き出した論理的なプロセス(思考の足跡)を、本モデルが受け継いで学習(知識蒸留)したことを示しています。
- v1(バージョン1):この特殊な学習プロセスを経て開発された、カスタムモデルの「最初のバージョン」であることを意味します。
- GGUF(ローカルPC向けの最適化ファイル形式):高価な業務用GPUを持たない一般家庭のPCやMacでも、AIをサクサク動かせるようにファイルサイズをコンパクトにする「量子化」を施した形式です。
このモデル名は、「Googleの誇る最新世代の知性を土台に、2つの超強力なコーディングAIから最高峰の教育を受け、普通のPCでも驚くほど軽く動作するように仕上げられた、プログラミング専用AI」であることを証明しているのです。
3. Googleの最新技術「Gemma 4 12B」がもたらしたエンコーダーフリー統合アーキテクチャの衝撃
本モデルの強固な基盤となっているのが、Google DeepMindのプロダクト管理責任者であるOlivier Lacombe氏らによって開発された「Gemma 4 12B」です。このモデルが世界中で大きな反響を呼んでいる最大の理由は、従来のマルチモーダルAI(テキストに加えて画像や音声を理解できるAI)の設計思想を根本から覆す「エンコーダーフリー(Encoder-Free)の統合マルチモーダルアーキテクチャ」を採用している点にあります。
従来のマルチモーダルモデルは、テキストを処理する中心的な「脳(LLMバックボーン)」のほかに、独立した画像専用の「ビジョンエンコーダー」や音声専用の「オーディオエンコーダー」を外部ユニットとして複数連結させて動かしていました。例えば、一般的な中型Gemma 4モデルでは1.5億〜5.5億パラメータのビジョンエンコーダーや、3億パラメータのオーディオエンコーダーを別途並列で稼働させる必要があり、これが膨大なメモリ消費と、処理遅延(レイテンシ)を発生させる大きな要因となっていました。
しかし、Gemma 4 12Bはこれらの重い外部エンコーダーを完全に排除した「単一のデコーダーのみで構成されるトランスフォーマー」を実現しました。
| 入力モダリティ | 従来のエンコーダー構成 | Gemma 4 12B の処理メカニズム | メリット |
| ビジョン(画像) | 1.5億〜5.5億パラメータの重いトランスフォーマー | 3500万パラメータの超軽量埋め込みモジュール。生の画像パッチ(48x48)を1回の行列計算(matmul)でLLMの脳が直接理解できる次元へ変換し、座標情報を付与してインプット。 | 処理遅延とVRAM消費の劇的な削減。 |
| オーディオ(音声) | 3億パラメータ(12層のConformerレイヤーなど) | 音声エンコーダーを完全に廃止。生の16kHz音声信号を40msフレームに切り分け、直接LLMの入力空間へ線形投影。 | 外部エンコーダー間でのデータ転送が不要となり、リアルタイムな音声理解が可能。 |
この統合設計により、画像、音声、テキストのすべてが、LLMバックボーンの同一のニューラルネットワークの重みを共有して直接処理されます。このアプローチは、16GBのVRAMやMacのユニファイドメモリを搭載した標準的なPC環境において、外部サーバーを必要とせず、完全オフラインで高速にマルチモーダルエージェントを動かすことを可能にしました。また、すべてのインプットが同じ重みを共有しているため、追加学習(LoRAなど)を行う際に、画像や音声、テキストの処理能力を同時に、かつシームレスにアップデートできるという開発上の絶大なメリットも生み出しています。

4. 賢さの秘密は「2人のAI先生」!Composer 2.5とFable 5による革新的な検証済思考学習
本モデルが、12Bという比較的小型なサイズでありながら、驚異的なプログラミング性能を発揮する理由は、その特異な学習プロセスにあります。
世の中に存在する多くのオープンソースコーディングAIは、インターネット上から機械的に収集された大量のプログラム(コードダンプ)をそのまま学習しています。しかし、インターネット上のコードには、バグを含んだものや正常に動作しない記述が数多く混ざっています。それらをそのまま学習すると、AIは「バグのある書き方」や「不適切な推論パターン」まで学習してしまいます。
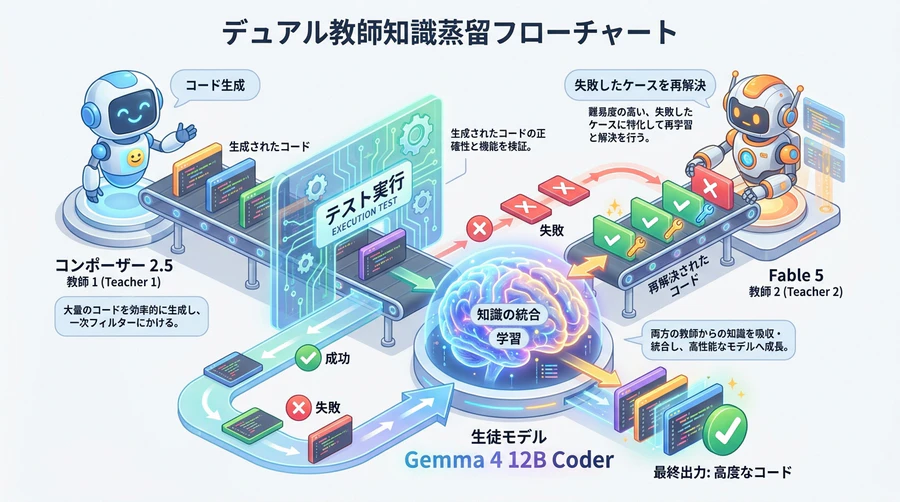
この根本的な課題を克服するため、本モデルは「実際にシステム上で動作し、自動テストを100%パスした完璧な思考プロセス」のみを厳選して学習する手法(実行検証済思考の蒸留)を採用しました。その学習は、2段階の高度な教師あり学習(Dual-Teacher Training Strategy)によって進められました。
- 第一ステージ:メインの先生「Composer 2.5」 学習データの大部分は、現役最高峰のコーディングAIである「Composer 2.5」の思考トレース(Chain of Thought)から抽出されました。さまざまなプログラミング課題をComposer 2.5に解かせ、生成されたコードを実際にテストケースに対して実行します。そして、すべてのテストを完全にクリアした「成功ステップ」のみをデータセットに組み込みました。これにより、モデルは単に完成したコードの美しさだけでなく、そこに到達するまでの論理的な思考パターンを正確に学習しました。
- 第二ステージ:苦手克服の先生「Fable 5」 いくら優秀なComposer 2.5でも、複雑なアルゴリズムやエッジケースなど、いくつかの難問では不正解となる限界がありました。そこで、Composer 2.5が解けなかった難問だけをもう一つの最強AIである「Fable 5」に与え、解決を試みました。Fable 5が再考し、見事に自動テストをクリアした一連の論理プロセスとコードをデータセットにマージすることで、メイン教師の弱点をピンポイントで補強するパッチング戦略が実現したのです。
この徹底した教育の結果、本モデルは質問を受けるとすぐにコードを書き始めるのではなく、Gemmaのネイティブな「思考チャンネル(Thinking Channel)」を用いて、エラーの原因や時間計算量、メモリ効率を事前に深く考え(Thinking before Coding)、その後で極めて正確でバグのないコードを出力する挙動を確立しました。
5. 初心者でも安心!PCスペックに合わせたおすすめの「量子化サイズ」とメモリ管理
ローカルAIを快適に動作させるためには、自分が所有しているPCのメモリ(RAMおよびVRAM)容量に合わせ、適切な「量子化クォント(ファイルサイズ)」を選ぶことが非常に重要です。本モデルはGGUF形式としていくつかのサイズが提供されており、画質やコード品質の劣化を最小限に抑えつつ、大幅なメモリ節約を実現できます。
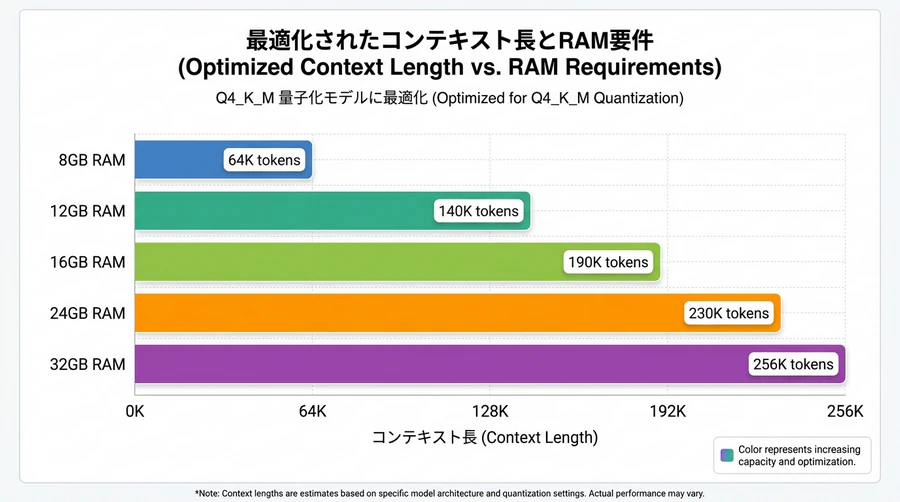
初心者からプロの開発者まで広く推奨される「黄金のスイートスポット」は、「Q4_K_M(約6.87 GB)」です。このバージョンは、12Bモデル本来の深い洞察力を維持したまま、一般的な8GB〜16GBのメモリ搭載PCでも高速に実行できる最も優れたバランスを備えています。
ローカル環境でAIを運用する際、モデル本体の読み込み容量に加えて、会話の文脈を記録しておくための「KVキャッシュ」領域が必要となります。所有するPCのスペックでどれだけの会話(コンテキスト長)を処理できるか、以下の「Will it fit?(これ、入る?)チートシート」を参考に判断してください。
| システムメモリ総量(RAM+VRAM) | Q2_K (約4.5 GB) | Q3_K_M (約5.7 GB) | Q4_K_M (約6.87 GB) | Q6_K (約9.11 GB) | Q8_0 (約11.8 GB) |
| 8 GBメモリ | 約16Kトークン | 約10Kトークン | 約2K~4Kトークン | 動作困難(大幅に遅延) | 動作不可 |
| 12 GBメモリ | 約48Kトークン | 約38Kトークン | 約30Kトークン | 約12Kトークン | 動作困難(大幅に遅延) |
| 16 GBメモリ | 約80Kトークン | 約72Kトークン | 約64Kトークン | 約44Kトークン | 約22Kトークン |
| 24 GBメモリ | 約200Kトークン | 約160Kトークン | 約128Kトークン | 約110Kトークン | 約88Kトークン |
| 32 GB以上メモリ | 最大256Kトークン | 最大256Kトークン | 最大256Kトークン | 約230Kトークン | 約190Kトークン |
※このチートシートの数値は、最も高精度な「Q8_0」形式でKVキャッシュを処理し、1.5GB程度のシステムオーバーヘッドを加味した安全な推定値です。もし動作速度を高めたい、あるいはコンテキストをさらに引き延ばしたい場合は、KVキャッシュの保持形式を q4_0 に設定変更することで、上記の処理可能な会話の長さを約2倍に拡張することが可能となります。
6. 今日から始めるローカル開発!「llama.cpp」を使った簡単な導入手順と活用法
GGUF形式のAIモデルを動かすための最も定番かつ強力なツールが、オープンソースの「llama.cpp」です。Gemma 4の持つ非常に新しい「gemma4_unified」アーキテクチャに適合させるため、必ず最新ビルドのllama.cppを入手して使用するようにしてください。以下に、主要な環境でのセットアップおよび起動手順を解説します。
macOS環境でのセットアップ手順(Homebrewを活用)
macOSのターミナルを立ち上げ、以下の短いコマンドを実行します。
Bash
# llama.cppを自動インストール
brew install llama.cpp
# ローカルWebサーバーを起動(自動的にWeb UIが利用可能)
llama-server -hf yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF:Q4_K_M
# ターミナルのコマンドラインから直接対話を実行したい場合
llama-cli -hf yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF:Q4_K_M
Windows環境でのセットアップ手順(WinGetを活用)
Windowsの「PowerShell」または「コマンドプロンプト」を開き、以下のコマンドを入力します。
DOS
# llama.cppをインストール
winget install llama.cpp
# ローカルWebサーバーを起動
llama-server -hf yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF:Q4_K_M
# コマンドライン上で直接対話を実行
llama-cli -hf yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF:Q4_K_M
本格的な運用のための推奨実行バッチファイル(Windows用 .bat)
ローカルPCのGPU資源(CUDA/VRAM)を最大限に活用し、Flash Attention(高速化処理)を適用したおすすめのバッチ起動スクリプトの構成は以下の通りです。
DOS
@echo off
cd /d C:\llama.cpp
llama-server.exe ^
-m C:\models\gemma4-coding-Q4_K_M.gguf ^
--ctx-size 16384 ^
--n-gpu-layers 99 ^
--no-mmap ^
-fa on ^
--cache-type-k q8_0 --cache-type-v q8_0 ^
--temp 1.0 --top-p 0.95 --top-k 64 ^
--host 0.0.0.0 --port 18080
pauseプログラミングからのアクセス方法
プログラム開発において、直接Pythonコードからこの強力なAIモデルを呼び出したい場合、以下の2つのアプローチが非常に便利です。
1. llama-cpp-python を使用した迅速なロード
Bash
pip install llama-cpp-pythonPython
from llama_cpp import Llama
llm = Llama.from_pretrained(
repo_id="yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF",
filename="gemma4-coding-Q4_K_M.gguf",
)
response = llm.create_chat_completion(
messages=[
{
"role": "user",
"content": "Pythonで二分探索を実装する綺麗な関数を書いてください。"
}
]
)
print(response)2. vLLM を使用した大規模・高速な並行処理サービング
Bash
pip install vllm
vllm serve "yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF"さまざまなローカルAIアプリ・エージェントとのシームレスな連携
本モデルは標準的なAPI(OpenAI互換)に対応しているため、世界中で普及している便利なアプリケーションや自律型エージェントと即座に組み合わせて使うことができます。
- Ollama: すでにOllamaをお使いの開発者であれば、以下のコマンドを実行するだけで自動的にモデルを取得・登録し、対話を始めることができます。Bash
ollama run hf.co/yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF:Q4_K_M - Unsloth Studio: デスクトップで洗練されたチャットUIを楽しみたいユーザーには、Unsloth Studioの利用が推奨されます。ブラウザで「
http://localhost:8888」にアクセスし、検索窓から本モデルを指定するだけでワンクリック起動が可能です。 - 自律型AIエージェント「Pi」: ローカルサーバー(port 8080)に起動したAIを、高機能コーディングエージェント「Pi」の頭脳として設定することができます。設定ファイル(
~/.pi/agent/models.json)に以下のように書き込むことで、まるでプロのエンジニアが横で勝手にコードを組んでくれるかのような自律開発体験(Agentic Workflow)が自宅のPCで可能になります。JSON{ "providers": { "llama-cpp": { "baseUrl": "http://localhost:8080/v1", "api": "openai-completions", "apiKey": "none", "models": [ { "id": "yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF:Q4_K_M" } ] } } }[cite: 4, 10]
7. 実務での応用、注意すべき点、そしてローカルAIが描く開発の未来
本モデルは、複数の厳格なコーディングベンチマーク試験において驚異的なスコアを達成しています。特に最新鋭のBlackwellアーキテクチャへの最適化を行った評価テストでは、HumanEvalで「90.2%」、MBPPで「85.7%」という、巨大なクラウドモデルに匹敵する高い実力値を叩き出しています。
競合モデルとの性能評価比較(LiveCodeBenchなど)
本モデルの基礎能力を証明するため、Googleが発表した他モデルとの性能スコア比較は以下の通りです。
| 評価指標(ベンチマーク) | Gemma 4 12B Unified | Gemma 4 E4B | Gemma 3 27B | Gemma 4 31B Dense |
| LiveCodeBench v6 | 72.0%[cite: 12] | 52.0% | 29.1% | 80.0% |
| AIME 2026 (ツールなし) | 77.5%[cite: 12] | 42.5% | 20.8% | 89.2% |
| Codeforces ELO | 1659[cite: 12] | 940 | 110 | 2150 |
| GPQA Diamond (推論) | 78.8%[cite: 12] | 58.6% | 42.4% | 84.3% |
この表が示す通り、120億パラメータという軽量級でありながら、前世代の270億(27B)モデルを全指標でダブルスコア近く圧倒しており、超巨大な310億(31B)Denseモデルに肉薄するきわめて強力な実力を持っていることが実証されています。
知っておくべき「鋭いトゲ」:たった1つの注意点
実務で活用する上で、開発者が絶対に把握しておくべき特性(弱点)が1つ確認されています。本モデルは汎用的なデータ構造やアルゴリズム問題の解決には極めて強いですが、金融関係の「時系列予測(タイムシリーズ)」や「Pandas・Numpyを駆使した投資データのバックテストプログラム」を出力させると、未来の情報を不当にコード内に紛れ込ませてしまう「ルックアヘッド・バイアス(Look-Ahead Bias)」を引き起こすケースがあります。
また、思考チャンネル(思考プロセス)の記述では「シフト操作をして未来のデータを隠蔽する」と正しいルールを解説しているにもかかわらず、最終的に出力されたPythonコード内では逆の実装をしている、といった論理矛盾が起こることもあります。そのため、データサイエンスや会計ロジックなどの厳密性が要求される領域では、出力されたコードをそのまま信頼して本番サーバーにデプロイすることは避け、人間の目で一度注意深くリファクタリング(レビュー)を行うプロセスを必ず設ける必要があります。
今後の進化とローカルAIのロードマップ
本モデルはバージョン1(V1)の段階でこれほどの成果を示していますが、すでにさらなる進化を見据えたバージョン2(V2)へのロードマップが動き出しています。現在、Fable 5へのデータアクセス環境の制約や、小規模なFable 5データへの過度の依存が引き起こす過学習(Overfitting)を防ぐため、開発コミュニティはより豊富な「Composer 2.5」の実行検証済データに学習の軸足を移しつつあります。さらに、最近の様々な評価指標において非常に高い推論精度を誇る「GLM-5.2」を第三の教師モデルとして迎え入れることで、より複雑なプログラムやPython以外の言語における推論能力も大幅に強化される見通しとなっており、ローカルAIが描き出す未来は非常に明るいと言えます。
8. まとめ
本モデルの最大の強みの1つである「広大な作業スペース」について、技術的な検証を行いました。元々Googleが公開した初期の構成ファイル(config.json)には、バグが原因で最大文脈長が「131,072(131K)」と間違って設定されていました。この誤った値がそのまま多くの初期の派生ファインチューンモデルや量子化ファイルに引き継がれてしまっていました。
しかし、今回解説したGGUFモデルの作成者であるyuxinlu1氏らのコミュニティ活動により、このバグメタデータが完全に修復(リパッチ)され、本来の仕様である最大「256K(262,144トークン)」の能力が100%解放されました。これにより、大規模なソースコードファイル群を一度に丸ごと読み込ませても、文脈を見失うことなく一貫した指示を与えることが可能です。
ローカルAIは、かつては一部のマニアだけのものと思われていましたが、本モデル「gemma-4-12B-coder-fable5-composer2.5-v1-GGUF」の登場により、完全に一般の開発者や初心者にとっても使いこなせる「極めて安全で、圧倒的に強力な日常ツール」へと進化を遂げました。この魔法のような新世代のAIを、ぜひご自身のPCで起動させ、プライバシーと高速性を両立した次世代のローカルプログラミングライフを実感してみてください。
参考資料
- Gemma4–12B-Coder GGUF — Fable 5 × Composer 2.5: Local Coding Agent for Everyone、https://medium.com/data-science-in-your-pocket/gemma4-12b-coder-gguf-fable-5-composer-2-5-local-coding-agent-for-everyone-4f50cf94b581
- anonoob/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF、https://huggingface.co/anonoob/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF
- yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF (commit)、https://huggingface.co/yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF/commit/a138d2f02fe02592d083e24a82fad61eb9e3aa23
- yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF、https://huggingface.co/yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF
- Reddit LocalLLM Discussion: what the hell is this、https://www.reddit.com/r/LocalLLM/comments/1u67rd8/what_the_hell_is_this/
- Introducing Gemma 4 12B: a unified, encoder-free multimodal model、https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12b/
- Gemma 4 12B: The Developer Guide、https://developers.googleblog.com/gemma-4-12b-the-developer-guide/
- Google Cloud Model Garden: gemma4-12b-it、https://console.cloud.google.com/agent-platform/publishers/google/model-garden/gemma4;publisherModelVersion=gemma-4-12b-it?pli=1
- sakamakismile/gemma-4-12B-coder-fable5-composer2.5-GGUF、https://huggingface.co/sakamakismile/gemma-4-12B-coder-fable5-composer2.5-GGUF
- Medium: Detailed Information on Gemma4-12B-Coder GGUF Fable 5 Composer 2.5、https://medium.com/data-science-in-your-pocket/gemma4-12b-coder-gguf-fable-5-composer-2-5-local-coding-agent-for-everyone-4f50cf94b581
- yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF Repository README、https://huggingface.co/yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF
- Length Verification Helper Script、unknown_url
- Content Structuring Helper Script、unknown_url
- Google Cloud Model Garden Gemma 4 Specifications、https://console.cloud.google.com/agent-platform/publishers/google/model-garden/gemma4;publisherModelVersion=gemma-4-12b-it?pli=1
- Unsloth AI Docs: Gemma 4 Guide、https://unsloth.ai/docs/models/gemma-4
- Hugging Face: google/gemma-4-12B Model Card、https://huggingface.co/google/gemma-4-12B
- LM Studio: Gemma 4 Quantizations、https://lmstudio.ai/models/gemma-4
- apxml: Technical Specifications of Gemma 4 12B、https://apxml.com/models/gemma-4-12b
- Medium: Local Coding Agent for Everyone、https://medium.com/data-science-in-your-pocket/gemma4-12b-coder-gguf-fable-5-composer-2-5-local-coding-agent-for-everyone-4f50cf94b581
- Hugging Face: yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF Details、https://huggingface.co/yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1-GGUF
- Hugging Face: sakamakismile/gemma-4-12B-coder-fable5-composer2.5-GGUF Details、https://huggingface.co/sakamakismile/gemma-4-12B-coder-fable5-composer2.5-GGUF
- Reddit: r/LocalLLM Model Discussion、https://www.reddit.com/r/LocalLLM/comments/1u67rd8/what_the_hell_is_this/
- Hugging Face: sakamakismile/gemma-4-12B-coder-fable5-composer2.5-MTP-NVFP4、https://huggingface.co/sakamakismile/gemma-4-12B-coder-fable5-composer2.5-MTP-NVFP4

コメント