

「OpenViking」のPodcast
下記のPodcastは、Geminiで作成しました。
はじめに
AIエージェントの開発において、直面する最も大きな障壁の一つが「文脈(コンテキスト)の崩壊」です。本レポートでは、ByteDance(バイトダンス)社の火山エンジンチームが開発した画期的な文脈データベース「OpenViking(オープンバイキング)」について、初心者にも分かりやすく丁寧に解説します 。従来のRAG(検索拡張生成)の限界をどのように突破し、AIエージェントに自律的かつ高度な記憶力を与えるのか、その仕組みと実装方法を体系的に解き明かしていきます 。
1. AIエージェントが直面する「記憶力」の壁(ゴールドフィッシュ問題)
現在のAIエージェント開発において、開発者を最も悩ませているのが、AIの「極端な物忘れ」です。高度な大規模言語モデル(LLM)であっても、長時間の対話や複雑なタスクを実行しているうちに、最初に指示したルールや重要な前提条件をすっかり忘れてしまう現象が頻発します 。この現象は、開発者の間で「金魚の記憶力問題(ゴールドフィッシュ・プロブレム)」と呼ばれています 。
LLMには「コンテキストウィンドウ(一度に処理できる情報量)」という物理的な限界が存在します 。会話の履歴、参照ドキュメント、実行すべきプログラムコードなどがこの窓から溢れてしまうと、古い情報から順に削られてしまい、AIにとっては「最初から存在しなかったこと」になってしまいます 。
この課題に対し、これまでは「RAG(検索拡張生成)」という技術が解決策として広く使われてきました 。RAGは、膨大なドキュメントから質問に関連する部分だけを検索してAIに渡す便利な仕組みです 。しかし、従来のRAGには「ベクタースープ(ベクトルごちゃ混ぜスープ)」と呼ばれる致命的な問題がありました 。ドキュメントを意味のない平坦なテキストの塊(チャンク)に切り刻んでベクトル空間に放り込むため、目次の階層構造や、ドキュメント同士の論理的なつながり、フォルダによる整理といった「構造的な情報」がすべて失われてしまうのです 。その結果、AIは「木を見て森を見ず」の状態に陥り、複雑な指示や長文の資料を正しく解釈できなくなっていました 。
【ベクタースープに溺れるAIと失われる構造情報】

2. 新星「OpenViking」の誕生とその背景
こうした「記憶の断片化」や「構造の喪失」といった難題を根本から解決するために生み出されたのが、OpenViking(オープンバイキング)です 。
OpenVikingは、TikTokなどを運営するByteDance社のクラウド部門「Volcano Engine(火山エンジン)」に所属する、非構造化データおよびスマート検索の専門家チームである「Vikingチーム」によって開発された、AIエージェント専用のオープンソース文脈データベース(Context Database)です 。火山エンジンは、数千社にのぼる企業向けにAIアシスタントや検索インフラを提供してきた実績があり、その過程で培われた商業的な知見がOpenVikingの設計に凝縮されています 。
2026年1月にオープンソースとして世界に公開されて以来、OpenVikingはその圧倒的な実用性から瞬く間にコミュニティに受け入れられました 。GitHubでのスター数は数か月で15,000から24,000を超え、TencentやAlibaba、Xiaomiといった数々のテックジャイアントが自社開発のAIフレームワークと連携させるなど、中国発のAIエージェントエコシステムにおいて爆発的な普及を遂げています 。現在は初期の「バージョン0.2.1」段階にありますが、今後は強固なプラグインエコシステムや、サードパーティ製拡張機能の開発といった第2フェーズへの進化が計画されています 。
3. 従来のRAGと何が違う?フォルダで整理する新パラダイム
OpenVikingの最大の特徴は、従来のフラットなベクトル空間での検索を廃止し、私たち人間がパソコンでファイルを管理するような「仮想ファイルシステム(仮想フォルダ構造)のパラダイム」を導入した点にあります。
AIエージェントが必要とする情報を、「記憶(Memory)」「知識(Resources)」「特技(Skills)」という3つのカテゴリに分け、これらをすべて viking:// という独自のプロトコル(スキーム)を用いたフォルダツリーの中に体系的に整理します 。
【AIエージェントの脳内を整理するOpenVikingの本棚】

このアプローチにより、AIエージェントは単に言葉が部分的に一致するデータを引っ張ってくるだけでなく、「どのフォルダにどんな情報が収められているか」という全体像を把握した上で、まるで人間がエクスプローラーやファインダーを使ってファイルを開くように、正確かつ追跡可能な形で情報にアクセスできるようになります 。
従来のフラットなRAGシステムと、OpenVikingの違いを詳細に比較してみましょう 。
| 比較項目 | 従来のフラットなRAGシステム | OpenViking |
| データ構造 | 平坦なチャンク(断片化されたテキストの塊) | viking:// による階層的な仮想ファイルシステム |
| 検索手法 | 単一のTop-K類似度検索(全体から言葉が似た部分を抜き出す) | 意図分析とディレクトリ再帰下行による高度な構造検索 |
| 文脈のロード方式 | 一度に大量のドキュメントを流し込む、または適当に切り詰める | L0(要約)、L1(概要)、L2(原文)の段階的なオンデマンド読み込み |
| 透明性とデバッグ | なぜその回答が選ばれたのかブラックボックスで追跡困難 | 検索したフォルダの軌跡が完全にログに残る(高い可視性) |
| 記憶の自動更新 | 手動でデータベースを更新しない限り、過去の対話は静的なまま | 会話終了時に自動で情報を抽出し、自己進化するセッションメモリ |
4. OpenVikingを支える「4つの画期的な仕組み」
OpenVikingがAIエージェントのパフォーマンスを劇的に向上させる背景には、4つの極めて洗練されたシステム設計が存在します 。それぞれの技術的な仕組みを、概念レベルから分かりやすく紐解いていきます。
① 体系的なマッピングを行う「Viking URI」
すべての文脈情報は、一意のURI(Uniform Resource Identifier)によって識別されます 。フォーマットは viking://{領域}/{パス} となり、用途に応じて厳密に分離されています 。
viking://resources/:ユーザーが登録したプロジェクト仕様書やAPIマニュアル、ソースコードなどを整理する静的な知識領域です 。viking://user/memories/:ユーザーの執筆スタイルやプログラミングの好み、過去に交わした重要な合意などを、個人用記憶として蓄積します 。viking://agent/skills/:エージェントが使用可能な各種外部ツール(Web検索、データ分析、カレンダー連携など)のスキーマ定義を格納します 。
この統一されたアクセスパスにより、AIエージェントはUnixコマンドのように ls(ファイル一覧表示)や read(内容読み込み)を用いて、直接かつ確実な情報操作を行うことが可能になります 。
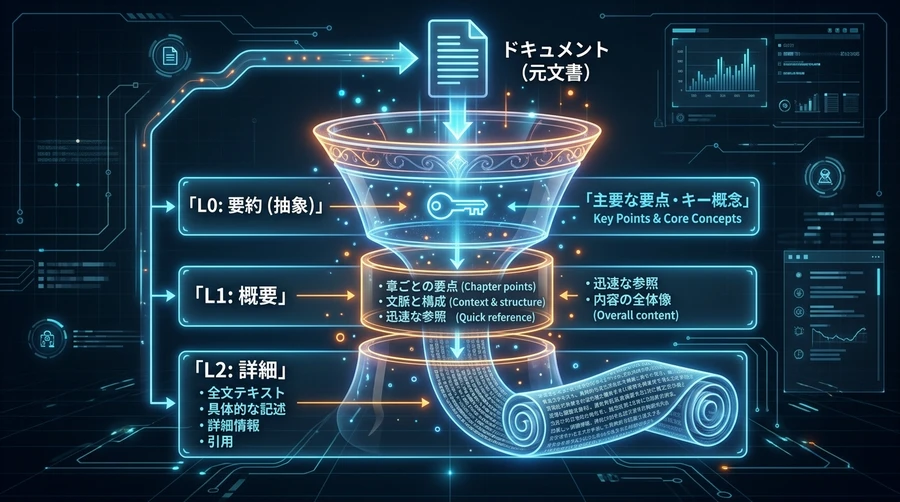
② 圧倒的なトークン削減率を誇る「3層フィルター(L0/L1/L2)」
コンテキストの肥大化によるAPI利用コストの上昇を抑えるため、OpenVikingは登録されたすべてのファイルに対して、バックグラウンドで自動的に3つのレイヤー(厚さ)の要約ファイルを生成します 。
- L0(Abstract):約100トークンの超短い1行要約です 。素早いフォルダ全体の関連性スキャンのために用いられます 。
- L1(Overview):約2,000トークンで構成される、ドキュメントの章構成や要点、主なユースケースをまとめた全体像です 。AIがどのアプローチを採るべきかプランニングする段階でロードされます 。
- L2(Details):ドキュメントのオリジナルデータそのものです 。AIが「この部分の具体的なパラメータ値やプログラムコードが知りたい」と必要性を判断した瞬間にのみ、ピンポイントで読み込まれます 。
例えば、システム内に50冊の障害対応手順書(合計約5万トークン)があるとします 。従来のRAGであれば関係する手順書の全文をロードしてコンテキストを圧迫しますが、OpenVikingであれば、まず50冊分のL0(約5千トークン)をスキャンしてアタリをつけ、最も可能性の高い3冊のL1(約6千トークン)をロードして比較し、最終的に本当に必要な1冊のL2のみを展開します 。この多段階構造により、無駄なデータ入力を排除し、APIコストを最大91%削減することに成功しました 。
【3層フィルターによる効率的なデータロード】
③ 精度の高い情報探索「ディレクトリ再帰検索」
従来のベクトル検索のように類似度の上位K件(Top-K)を盲目的に取り出すのではなく、人間の思考プロセスに近い再帰的な検索を実装しています 。
- 意図分析(Intent Analysis):ユーザーが発した質問を解釈し、何を探しているのか、どういう性質の回答を求めているのかを分析します 。
- 初期配置(Initial Positioning):まずL0情報を頼りに、最も合致度の高い特定の親ディレクトリ(例:
/docs/api/)をピンポイントで特定します 。 - 精密探索と再帰降下:選ばれたフォルダの内部を再帰的にスキャンし、さらに深いサブフォルダやファイルを詳細に評価します 。
- 結果の集約:論理的な整合性を保ちながら、最適な情報だけを最終的なコンテキストとしてまとめ上げます 。
このプロセスにおいて、探索の履歴(どのフォルダを通り、どのファイルを候補から外したかなど)が可視化された「軌跡(トレース)」としてすべてログに保存されます 。ブラックボックスになりがちだったAIの思考過程を高い透明性をもってデバッグできるのは、開発者にとってこの上ない強みです 。
④ 自動で自己進化する「セッションメモリ」
対話やタスクが終了した瞬間、OpenVikingはバックグラウンドで会話全体の文脈を圧縮し、そこから得られた新しい「経験や知識」を自動で抽出します 。 このデータは自動的に「6つの主要な引き出し(記憶カテゴリ)」に分類されて永続化されます 。
- Profile(プロフィール):ユーザー自身の名前や職業などの基本情報 。
- Preferences(好み):話題ごとのユーザーのこだわりや、希望する出力形式 。
- Entities(固有名詞):会話に登場した製品、企業、プロジェクト、人物の関係性 。
- Events(出来事):意思決定のプロセスや、過去のタイムライン上の重要なマイルストーン 。
- Cases(経験事例):特定の不具合に対してAIがどのようなツールを使い解決したかという「学習ケース」 。
- Patterns(行動・思考パターン):特定のタスクを実行する際にAIが学習した効率的な段取りやパターン 。
これらの情報は蓄積されるだけでなく、次回以降の対話において自動的に呼び出され、AIエージェントの振る舞いを時間とともにどんどん洗練させていく仕組みになっています 。
5. AIエージェントフレームワーク「OpenClaw」との驚異的なシナジー
OpenVikingは、世界的にも著名なAIオープンソース開発者のPeter Steinberger氏(後にOpenAI社へ移籍)によって開発された、大人気エージェントフレームワーク「OpenClaw(オープンクロー)」と極めて深い親和性を持っています 。
OpenClawは、AIが電子メールを送信したり、カレンダーをチェックしたり、ブラウザを操作したりするための、いわば「身体と手足(エージェント・ハーネス)」に該当します 。これに対し、OpenVikingはそれらの行動に基づいた学びを記憶に留める「脳の長期記憶領域」の役割を果たします 。
この手足と脳の強力な統合がもたらす効果は、ByteDanceチームが行った標準性能テスト(LoCoMo10データセット)において、以下の驚くべきデータとなって実証されています 。
| 指標 | OpenClaw(単体・ベースライン) | OpenClaw + LanceDB(他社ベクトルDB) | OpenClaw + OpenViking |
| タスクの完了率(高いほど優秀) | 35.65% | 44.55% | 52.08% (メモリコア連携で80%以上に到達可能) |
| 消費された入力トークン数 | 2,460万トークン | 5,160万トークン | 430万トークン (メモリコア有効時は210万) |
【身体としてのOpenClawと脳としてのOpenVikingの共創】

このデータが示す通り、OpenVikingを接続するだけで、処理の確実性が約1.5倍に向上するだけでなく、開発者が支払うAPI料金を10分の1近くまで圧縮することが可能となります 。これは商用サービスを運用する企業にとって極めて大きな革新です 。
6. 実践!手元のパソコンでOpenVikingを動かす手順とコード例
それでは、実際に手元のPC環境(Windows, macOS, Linux)にOpenVikingを導入し、初めてのプログラムを実行するまでのステップを丁寧に追っていきましょう 。
システム要件の確認
OpenVikingをローカルでビルドして動かすためには、事前に以下のツールがインストールされている必要があります 。
- Python 3.10以上
- Go 1.22以上(高速なファイルシステムコンポーネント「AGFS」の構築に必要)
- C++コンパイラ(GCC 9以上、またはClang 11以上)
ステップ1:パッケージのインストール
ターミナルを開き、以下のpipコマンドを使ってOpenVikingをインストールします 。
Bash
pip install openviking --upgrade --force-reinstall
ステップ2:設定ファイル ov.conf の配置
デフォルトでは、設定ファイルは ~/.openviking/ov.conf というパスに作成します 。 ディレクトリを作成して設定ファイルを開き、以下の内容を貼り付けます 。ここでは、最も推奨されている火山エンジンの「豆包(Doubao)」モデルを使用する例を示します 。
JSON
{
"storage": {
"workspace": "./openviking_workspace"
},
"log": {
"level": "INFO",
"output": "stdout"
},
"embedding": {
"dense": {
"provider": "volcengine",
"model": "doubao-embedding-vision-251215",
"api_key": "YOUR_VOLCENGINE_API_KEY",
"api_base": "https://ark.cn-beijing.volces.com/api/v3",
"dimension": 1024
}
},
"vlm": {
"provider": "volcengine",
"model": "doubao-seed-2-0-pro-260215",
"api_key": "YOUR_VOLCENGINE_API_KEY",
"api_base": "https://ark.cn-beijing.volces.com/api/v3"
}
}
※ OpenAI(GPT-4Vなど)や、LiteLLMを経由した各種ローカルモデル(OllamaのLlama 3.1、DashScope経由のQwenなど)も指定のプロバイダ名に変更することで柔軟に使用できます 。また、設定ファイルの場所をカスタマイズしたい場合は、環境変数 OPENVIKING_CONFIG_FILE に任意のパスを設定すれば、システムが起動時にそのパスを読み込みます 。
Bash
# Linux / macOSの場合
export OPENVIKING_CONFIG_FILE=~/.openviking/ov.conf
# Windows PowerShellの場合
$env:OPENVIKING_CONFIG_FILE = "$HOME\.openviking\ov.conf"
ステップ3:初めてのPythonプログラムの実行
準備が整ったら、test_viking.py という新しいファイルを作成し、以下のサンプルコードを実行してみましょう 。
Python
import openviking as ov
# クライアントを指定のデータフォルダで初期化します
client = ov.SyncOpenViking(path="./data")
try:
# 接続を初期化します
client.initialize()
print("✅ OpenVikingが正常に起動しました!")
# リソース(ここではWeb上にあるREADMEマニュアル)を登録します
# wait=Trueにすることで、自動でバックグラウンドで行われる3層要約処理が完了するのを待ちます
print("ドキュメントを読み込んで解析中です。しばらくお待ちください...")
result = client.add_resource(
path="https://raw.githubusercontent.com/volcengine/OpenViking/refs/heads/main/README.md",
wait=True
)
root_uri = result['root_uri']
print(f"ドキュメントが保存されたViking URI: {root_uri}")
# 仮想フォルダのツリー階層を確認してみます
ls_result = client.ls(root_uri)
print(f"\n📂 フォルダ構造の解析結果:\n{ls_result}\n")
# 自動生成されたL0、L1レイヤーを取得します
abstract = client.abstract(root_uri)
overview = client.overview(root_uri)
print(f"📖 L0 超要約:\n{abstract}\n")
print(f"📖 L1 概要:\n{overview}\n")
# セマンティック検索を実行して、関係する記述を抽出します
print("🔍 セマンティック検索(意味による検索)を実行中...")
search_results = client.find("what is openviking", target_uri=root_uri)
print("\n💡 検索で見つかった情報:")
for r in search_results.resources:
print(f" ・URI: {r.uri} (合致度スコア: {r.score:.4f})")
print(f" 内容: {r.content[:150]}...\n")
# セッション(対話履歴)を作成し、自動で長期記憶に変換するデモ
session = client.create_session()
session_id = session["session_id"]
# ユーザーとアシスタントのやり取りを履歴として追加します
client.add_message(session_id, "user", "私の名前はアリスです。PythonとOpenVikingを勉強しています。")
client.add_message(session_id, "assistant", "アリスさん、よろしくお願いします!素晴らしい挑戦ですね。")
# セッションをコミットすることで、背後で自動的に「引き出し(記憶領域)」に格納されます
client.commit_session(session_id)
print("✨ 会話から得た新しい記憶(アリスの名前や趣味)の抽出・永続化が完了しました。")
except Exception as e:
print(f"❌ エラーが発生しました: {e}")
finally:
client.close()
print("\n👋 処理を正常に終了しました。")
このコードを実行すると、コンソール上に整然としたフォルダツリーが表示され、AIが文脈を高い解像度で理解し、会話から自動でパーソナリティ記憶を構築する革新的なプロセスの全体を体感することができます 。
トラブルシューティング
初めて動かす際につまずきやすいポイントとその対策です 。
- ファイル名の重複によるインポート失敗:同じディレクトリ階層に全く同じファイル名を追加しようとすると、システムがコンフリクトを起こす場合があります 。ファイル名をユニークなものにリネームするか、バージョン管理機能をONにして追加してください 。
- 接続タイムアウトまたは認証エラー:火山エンジンのコンソール等でAPIキーが「アクティブ(有効)」になっているか、またクレジットカードの残高や無料トライアル枠が不足していないか確認してください 。また、海外環境やVPN経由で接続している場合は、
api_baseへの到達性も確認し、必要に応じてタイムアウト制限時間を延ばす設定を行ってください 。
7. これからのAIエージェント開発とOpenVikingの展望
AIエージェントが、ただ「その場限りの優秀な会話相手」から「あなたの業務プロセスを永続的にサポートしてくれるスマートな同僚」へと進化するためには、強固でかつ破綻しない記憶システムが不可欠です 。
従来のRAGが持つ、バラバラに刻んでごちゃ混ぜにする「平坦なベクトル手法」は、ドキュメントが持つ論理構造や複雑な業務コンテキストを完全に捉えきれず、限界を迎えつつありました 。これに対し、仮想ファイルシステムという古くからある、しかし最も直感的で信頼性の高い方法で文脈を体系化するOpenVikingは、今後のAIエージェントインフラストラクチャにおける全く新しいパラダイム(標準基準)を提示しました 。
火山エンジンという強力なビジネス検証環境から生まれ、オープンソースコミュニティとの強烈な連動によってものすごいスピードで進化を続けるこの文脈データベースは、これからさらに多くのフレームワークとの標準連携が進んでいくと考えられます 。手元のエージェントに「本当の意味での脳みそ」を実装し、賢く、安く、精度高く、そして永遠に自己成長させたい開発者にとって、OpenVikingは最もエキサイティングで実用的な選択肢となるでしょう 。
参考資料
- Topics - context-database - Python、https://github.com/topics/context-database?l=python
- OpenViking Official Website、https://openviking.ai/
- OpenViking:给AI Agent 一座“可管理、可追踪、会自我进化”的上下文基地、https://vampireachao.github.io/2026/03/19/OpenViking/index.html
- Tutorial for Using OpenViking in OpenClaw、https://medium.com/@swizardlv/tutorial-for-using-openviking-in-openclaw-d07e3103d99a
- 火山引擎 OpenViking 项目概述与团队背景、https://github.com/volcengine/OpenViking/blob/main/docs/zh/about/01-about-us.md
- 火山方舟購入流程与 API 登録ガイド、https://github.com/volcengine/OpenViking/blob/main/docs/zh/guides/02-volcengine-purchase-guide.md
- OpenViking Cloud deployment and multi-tenant setup、https://github.com/volcengine/OpenViking/blob/main/examples/cloud/GUIDE.md
- OpenViking Quickstart Guide and Docker Deployment、https://github.com/volcengine/OpenViking/blob/main/docs/zh/getting-started/02-quickstart.md
- 火山引擎 Agent 社区ブログ、https://developer.volcengine.com/user/1328665155612552
- BytePlus ModelArk OpenViking Guide、https://docs.byteplus.com/en/docs/ModelArk/2288685
- OpenViking: ByteDance's Open-Source Context Database That Gives AI Agents Real Memory、https://emelia.io/hub/openviking-context-database-ai-agents
- Apidog Blog - OpenViking: The Filesystem Paradigm Context Database for AI Agents、https://apidog.com/blog/openviking/
- Reddit machinelearningnews - Meet OpenViking、https://www.reddit.com/r/machinelearningnews/comments/1rumjkt/meet_openviking_an_opensource_context_database/
- OpenViking Python SDK Example and Quickstart、https://github.com/volcengine/OpenViking/blob/main/docs/en/getting-started/02-quickstart.md
- OpenViking Server deployment and HTTP Client Connection、https://github.com/volcengine/OpenViking/blob/main/docs/en/getting-started/03-quickstart-server.md
- Marktechpost - Meet OpenViking: An Open-Source Context Database、https://www.marktechpost.com/2026/03/15/meet-openviking-an-open-source-context-database-that-brings-filesystem-based-memory-and-retrieval-to-ai-agent-systems-like-openclaw/
- PyPI openviking project documentation、https://pypi.org/project/openviking/0.1.12/
- OpenViking Mintlify Quickstart and Python SDK setup、https://volcengine-openviking.mintlify.app/quickstart
- OpenViking Docs - Viking URI format and path variables、https://github.com/volcengine/OpenViking/blob/main/docs/en/concepts/04-viking-uri.md


コメント