

- 「1ビット」がAIの常識を覆す?Microsoftの革新的技術『BitNet』を徹底解説! 〜省エネ・高速・低コストな次世代AIの仕組み〜のPodcast
- 序論:大規模言語モデルが抱える「重厚長大」の壁
- 従来のLLMが抱える課題:電力、メモリ、コストの限界
- BitNetの誕生と進化:1ビットから1.58ビットへ
- 技術的深掘り:BitLinearと三値重みのメカニズム
- 驚異の効率性:なぜ「足し算だけ」で計算できるのか
- 実証データ:フル精度モデルとの性能比較
- 最新研究:BitNet b1.58 2B4Tの衝撃
- 実行環境の変革:bitnet.cppとCPU推論の可能性
- 業界へのインパクト:ハードウェア、Edge AI、そして民主化
- 結論:持続可能なAI社会に向けて
- 参考資料
「1ビット」がAIの常識を覆す?Microsoftの革新的技術『BitNet』を徹底解説! 〜省エネ・高速・低コストな次世代AIの仕組み〜のPodcast
下記のPodcastは、Geminiで作成しました。

序論:大規模言語モデルが抱える「重厚長大」の壁
現在、大規模言語モデル(LLM)は、ChatGPTやClaude、Geminiといったサービスを通じて私たちの生活やビジネスに欠かせない存在となっています。しかし、これらのモデルが「賢さ」を追求すればするほど、その裏側では膨大な計算資源と電力が消費されています。
従来のLLMは、FP16(16ビット浮動小数点数)やBF16といった高精度なデータ形式を用いてパラメータを保持しており、モデルの規模が大きくなるにつれて必要となるビデオメモリ(VRAM)や計算コストは指数関数的に増大してきました [1]。例えば、70億のパラメータを持つ「7Bモデル」を動かすだけでも、重みの保持だけで約14GBのVRAMが必要となります [1]。これをさらに巨大な100B(1000億)規模のモデルにスケールさせれば、一般のコンシューマー向けハードウェアでは手も足も出ない状況となります。
この「計算資源の壁」と「環境負荷の増大」こそが、AIのさらなる普及と進化を阻む最大の課題となっていました [1]。こうした中、Microsoft Researchが提案した「BitNet」およびその進化形である「BitNet b1.58」は、この状況を根本から変える可能性を秘めています。パラメータの精度を極限まで落とし、各数値をわずか「1.58ビット」で表現するというこの技術は、AIの「知能」を維持したまま「重さ」と「消費電力」を劇的に削減することに成功しました [1]。本報告書では、この魔法のような技術の仕組みから、最新の「2B4T」モデルの実力、そしてAIの未来にどのような変革をもたらすのかを詳しく解説します。
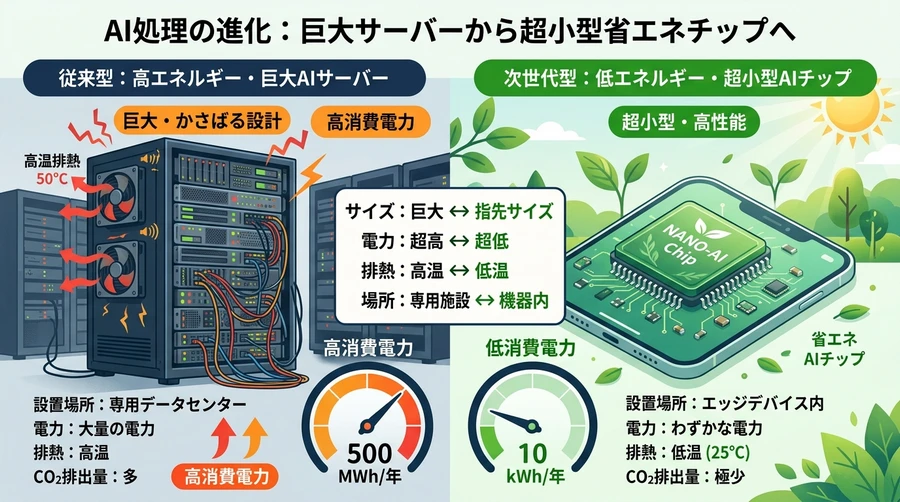
従来のLLMが抱える課題:電力、メモリ、コストの限界
今日のAIブームを支えるTransformerアーキテクチャに基づいたLLMは、本質的に「巨大な行列演算の塊」です。AIの推論過程では、入力されたデータに対して何十億、何千億という「重み(パラメータ)」が掛け合わされ、次の言葉が予測されます。この演算を支える標準的な形式であるFP16は、一つの数字を表すのに16個の「0か1」のスイッチを使用します。これにより、非常に細かい数値(小数点以下の複雑な数字)を表現でき、高い学習精度を保つことができます [1]。しかし、この精度には大きな代償が伴います。
計算コストとエネルギー消費
FP16での行列演算には「浮動小数点数の掛け算(Multiplication)」が含まれます。コンピュータの演算チップにとって、小数の掛け算は非常に複雑で重い処理であり、膨大な電力を消費します [1]。データセンターではこれらの演算のために大量のGPUが稼働し、その消費電力は国家レベルに匹敵するとさえ言われるほどです [1]。
メモリ帯域のボトルネック
モデルが巨大化すると、演算そのものよりも「メモリからデータを読み出す速度」が処理の足かせになります(メモリ帯域制限)。パラメータがFP16のように大きいと、それだけ読み出しに時間がかかり、推論の待ち時間(レイテンシ)が増大します [1]。
AIの独占状態
高性能なAIを動かすには高価なNVIDIA製GPUなどが不可欠であり、これが可能なのは巨大な資本を持つ一部の企業や組織に限られてきました。一般の個人や中小企業が独自のモデルをローカル環境で動かすには、ハードウェアのコストがあまりに高すぎたのです [1]。BitNetは、これらの問題を「精度を落とす」という逆転の発想で解決しようとしています [1]。
BitNetの誕生と進化:1ビットから1.58ビットへ
BitNetの歴史は、まず「1ビット」という極端な量子化から始まりました。
初代BitNetの衝撃
2023年10月、Microsoft Researchは「BitNet: Scaling 1-bit Transformers for Large Language Models」と題した論文を発表しました [1]。この初代BitNetの最大の特徴は、モデルの重みを $\{-1, 1\}$ の2値(1ビット)のみで表現した点にあります。これまでの常識では、これほどまでに精度を落とせばAIとしての性能は崩壊すると考えられてきました。しかし、研究チームは学習プロセスの中で適切に量子化を行う手法(Quantization-Aware Training)を開発し、驚くべきことにフル精度のモデルに近い性能を維持できることを示したのです [1]。
決定版となった「BitNet b1.58」
初代BitNetの発表から間もない2024年2月、さらに洗練された「BitNet b1.58」が登場しました [1]。この「1.58ビット」という中途半端な数値こそが、この技術を実用的なものにした鍵です。
1.58ビットとは、数学的には $\log_2 3$ に相当し、各パラメータが $\{-1, 0, 1\}$ の3つの値(三値)のいずれかを取ることを意味します [1]。初代の2値(-1と1)に「0」が加わったことは、単なる数字の増加以上の意味を持ちました。この「0」の存在により、モデルは「特定の情報の重みをゼロにする(情報を遮断する)」という、いわば情報の取捨選択(フィーチャー・フィルタリング)が可能になったのです [1]。この能力によって、1.58ビットモデルは同等サイズのFP16モデルと全く遜色ない性能を発揮できるようになりました [1]。
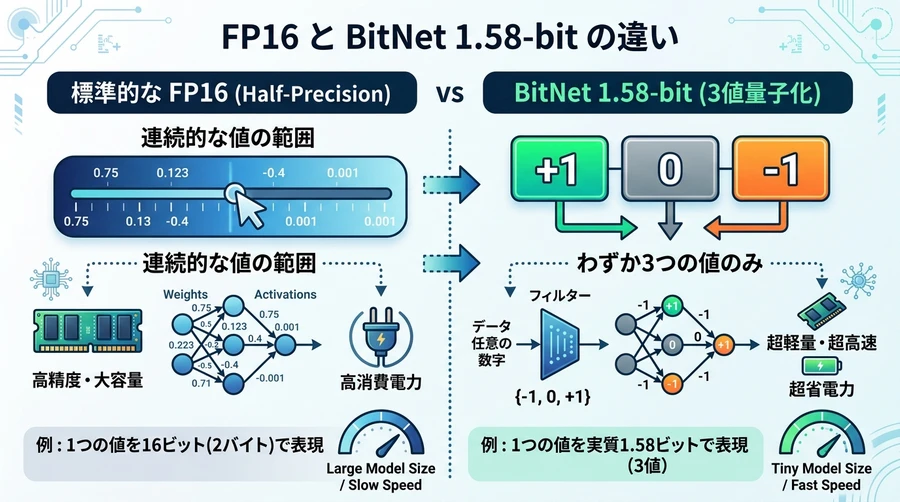
技術的深掘り:BitLinearと三値重みのメカニズム
BitNetがなぜこれほど効率的なのかを理解するには、その心臓部である「BitLinear」レイヤーの仕組みを知る必要があります。
BitLinearレイヤー
従来のTransformerモデルでは、標準的な `nn.Linear` という層が使われ、そこで複雑な掛け算が行われます。BitNetではこれを「BitLinear」という独自の層に置き換えます [1]。
BitLinearでは、モデルの重みを $\{-1, 0, 1\}$ に量子化し、さらに計算を安定させるために、入力データ(アクティベーション)も8ビット(INT8)などの低い精度に変換します [1]。
absmean量子化のプロセス
重みを三値に変換するために「absmean(絶対平均値)量子化」という手法が用いられます [1]。
スケーリング: 重み行列全体の絶対値の平均( $\gamma$ )を算出します。
丸め処理: 個々の重みを $\gamma$ で割り、最も近い整数 $\{-1, 0, 1\}$ に丸めます [1]。
このシンプルな処理により、学習時にも勾配の流れを維持しながら、重みを極限まで圧縮することが可能になりました [1]。
アーキテクチャの最適化
最新のBitNet(2B4Tモデルなど)では、Llama 3に近いコンポーネントが採用されています [1]:
RMSNorm/SubLN: 学習の安定性を高めるための正規化手法 [1]。
RoPE (Rotary Position Embeddings): 位置情報を表現する最新の埋め込み手法 [1]。
Squared ReLU: 推論の効率化に貢献する活性化関数 [1]。
バイアスの排除: 計算をさらに簡略化するため、全層からバイアス項を取り除いています [1]。
驚異の効率性:なぜ「足し算だけ」で計算できるのか
BitNetがもたらす最大の革命は、行列演算から「掛け算」を追放したことにあります。
掛け算から足し算への転換
通常のAIが行う行列演算 $y = W \times x$ において、$W$(重み)が $\{-1, 0, 1\}$ のいずれかである場合、計算は劇的に簡略化されます [1]:
重みが 1 の時:入力をそのまま出力に足す。
重みが -1 の時:入力の符号を反転させて足す(引く)。
重みが 0 の時:その入力を無視する。
これにより、最もエネルギーを消費する「浮動小数点数の積和演算」が、単純な「整数の加減算」に置き換わります [1]。
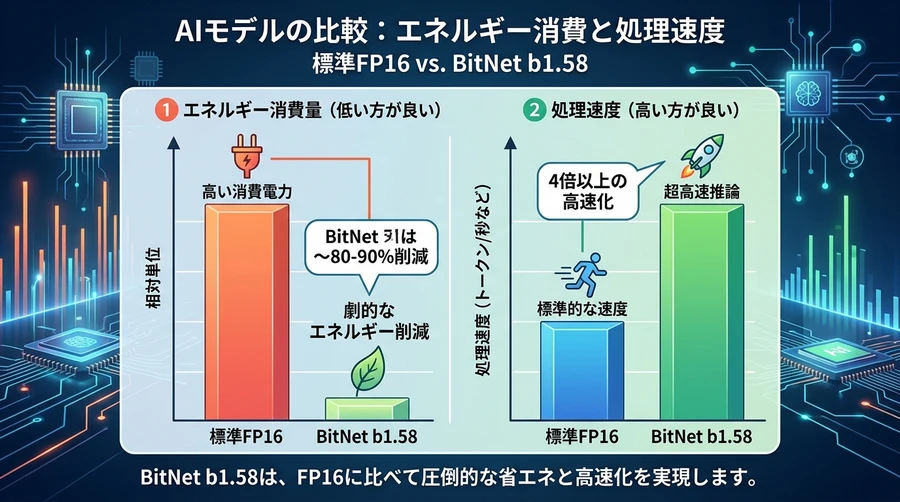
効率性の数値データ
BitNet b1.58が示す効率性の改善は、以下の比較表に顕著に表れています。
| 指標 | 従来のFP16モデル | BitNet b1.58 | 改善率 |
|---|---|---|---|
| 行列演算のエネルギー効率 | 1.0x (基準) | 約71.4x 効率的 | 70倍以上の削減 |
| 3BモデルのGPUメモリ使用量 | 7.89 GB | 2.22 GB | 約3.55倍の削減 |
| 推論のスループット(70B) | 1.0x (基準) | 8.9x 高速 | 約9倍の処理能力 |
| 算術演算コスト | 1.0x (基準) | 0.25x | 4分の1以下 |
特筆すべきは、モデルの規模が大きくなるほど、これらの効率化の恩恵が拡大していく点です [1]。これは、将来的に数兆規模のパラメータを持つ超巨大AIを構築する際、BitNetが唯一現実的な選択肢になる可能性を示唆しています [1]。
実証データ:フル精度モデルとの性能比較
「性能が低いから軽い」のであれば驚きはありません。BitNet b1.58が革命的であるのは、「軽いのに、フル精度モデルと同等以上に賢い」という点です [1]。
スケーリング則の成立
研究チームは、BitNetも従来のTransformerと同様に「モデルの規模と学習データの量を増やせば、予測性能(Perplexity)が綺麗に向上する」というスケーリング則に従うことを確認しました [1]。さらに、モデルが大きくなるほど、FP16モデルとの性能差が縮まっていくことが実証されています [1]。
ゼロショット性能の比較
以下の表は、30億パラメータ(3B)規模での各種ベンチマーク結果をまとめたものです。
| ベンチマーク | LLaMA 3B (FP16) | BitNet b1.58 3B | 優位性 |
|---|---|---|---|
| ARC-Challenge | 基準値 | 匹敵 | 同等 |
| HellaSwag | 基準値 | 匹敵 | 同等 |
| Winogrande | 基準値 | 匹敵 | 同等 |
| 3.9Bモデルとの比較 | 3.0B FP16 | 3.9B b1.58 | b1.58が圧倒 |
30億パラメータの時点ですでにFP16モデルと同等の精度に達しており、39億パラメータに微増させたBitNet b1.58は、30億パラメータのFP16モデルをあらゆる面で凌駕しつつ、依然としてメモリ消費や速度では圧倒的に優位に立っています [1]。これは、同じハードウェア資源であれば、BitNetを用いることでより大規模で賢いモデルを動かせることを意味します [1]。
最新研究:BitNet b1.58 2B4Tの衝撃
2025年4月、Microsoft Researchは最新の成果として「BitNet b1.58 2B4T」テクニカルレポートを公開しました [1]。これは、この技術がすでに研究室のプロトタイプを脱し、実用レベルに達したことを象徴する出来事です。
4兆トークンによる極限の学習
「2B4T」の名前の通り、このモデルは20億パラメータという軽量な構成ながら、4兆トークン(4 Trillion Tokens)という膨大なデータセットで一から学習されています [1]。学習データには、高品質なテキストデータセットである「DCLM」や「FineWeb-EDU」、さらには合成された数学データなどが含まれています [1]。
驚異のベンチマーク結果
この最新モデルは、20億パラメータというサイズ制限がありながら、既存の主要なフル精度モデル(LLaMA 3.2 1BやQwen 2.5 1.5Bなど)と比較しても極めて高い競争力を持っています [1]。
| モデル | パラメータ | 平均スコア(11項目) | 推論エネルギー |
|---|---|---|---|
| BitNet b1.58 2B4T | 2.0B | 54.19 | 0.028 J |
| Qwen 2.5 1.5B | 1.5B | 55.23 | 0.347 J |
| LLaMA 3.2 1B | 1.0B | 44.90 | 0.258 J |
※のデータを基に統合。この結果で最も注目すべきは「エネルギー効率」です。BitNetは、Qwen 2.5 1.5Bと比較して約12倍、LLaMA 3.2 1Bと比較しても約10倍近く少ない電力で、同等以上の「賢さ」を発揮しています [1]。特に数学問題(GSM8K)や推論(ARC)において、重いフル精度モデルを凌駕するスコアを記録している点は驚異的です [1]。
学習の安定性とスケジュール
BitNetは学習が不安定になりやすい量子化モデルの弱点も克服しています。2段階の学習率スケジュール(一定期間維持した後に急激に減衰させる「クールダウン」フェーズ)を採用することで、非常に高い学習安定性を実現しました [1]。これは、将来的にさらに巨大なモデルを学習させる際にも、トラブルなくスケールできることを示しています [1]。
実行環境の変革:bitnet.cppとCPU推論の可能性
BitNetの凄さは、スーパーコンピュータの中だけでなく、私たちの身近なパソコンやスマートフォンでこそ実感できます。
CPUがAIの主役になる
従来のLLM推論は、その膨大な演算負荷からGPUが必須とされてきました。しかし、Microsoftが公開した推論フレームワーク「bitnet.cpp」は、この常識を覆しました [1]。
BitNetの「足し算だけの計算」は、実は現代のCPUに搭載されているSIMD(命令セット)と非常に相性が良いのです。
2026年の驚愕ベンチマーク
最新の報告(2026年1月時点)によると、bitnet.cppを用いた推論パフォーマンスは以下の通りです [1]:
100BモデルのCPU駆動: 1000億パラメータという、これまで企業向けの超高性能サーバーでしか動かなかった巨大AIが、一般的なコンシューマー向けCPUで「人間が文章を読むスピード(毎秒5〜7トークン)」で動作します [1]。
圧倒的な高速化: x86系CPUでは、従来の同規模モデルと比較して2.37倍から6.17倍の速度向上を記録しています [1]。
省メモリ: 2Bモデルであれば、OSも含めてわずか0.4GB程度のRAMがあれば動作可能です [1]。
実際に動作するデバイス
この技術により、以下のようなシーンが現実味を帯びてきました [1]:
スマートフォン: インターネットに接続せず、機内モードの状態でも、ChatGPTレベルの応答が可能なAIアシスタント。
IoT機器: 洗濯機や冷蔵庫に内蔵された小さなチップで、音声による高度な対話操作を実現。
エッジデバイス: セキュリティ上の理由でデータをクラウドに送れない工場や医療現場でのローカルAI活用。

業界へのインパクト:ハードウェア、Edge AI、そして民主化
BitNetは単なる一つのモデルではなく、AI業界全体の構造を変えるインパクトを持っています。
ハードウェア設計の転換
現在のGPU(Graphics Processing Unit)は、その名の通り「画像処理」や「複雑な小数の掛け算」のために進化してきました。しかし、BitNetのような「三値(-1, 0, 1)の足し算」が主流になれば、ハードウェア側もそれ専用に最適化される必要があります [1]。
研究チームは、三値演算に特化した「1ビットプロセッサ(LPUや専用アクセラレータ)」の設計を呼びかけています。もしこれが実現すれば、現在のGPUのさらに数十倍、数百倍という次元の効率でAIを動かせるようになるかもしれません [1]。
環境負荷の低減とサステナビリティ
AIのトレーニングと推論にかかる莫大な電気代とCO2排出量は、今や無視できない社会問題です。BitNetは行列演算のエネルギーを70倍以上削減できるため、環境に優しい「グリーンなAI」の代表格として期待されています [1]。
AIの民主化
高価なGPUを買わなければ最新のAIを研究・開発できない「GPU格差」は、技術の独占を生んでいました。しかし、BitNetによって「普通のパソコンのCPU」で高性能なAIが動くようになれば、世界中の研究者や開発者がAIの改良に参加できるようになります [1]。これは、AIという強力なツールが一部の巨大テック企業だけでなく、人類全体のものになる「民主化」への大きな一歩です [1]。
プライバシーとセキュリティ
「ローカルで動く」ということは、自分の個人的な会話や機密情報を外部のサーバー(クラウド)に送信する必要がないことを意味します。プライバシーを究極まで重視するビジネス利用や、機微な情報を扱う医療・法務分野において、BitNetの軽量性は強力な武器となります [1]。
結論:持続可能なAI社会に向けて
MicrosoftのBitNet、特にBitNet b1.58は、大規模言語モデルがこれまで歩んできた「巨大化による性能向上」という道の先に、初めて「効率性と知能の両立」という新たな選択肢を提示しました。わずか「1.58ビット」という極限の精度でありながら、フル精度のモデルに匹敵する知能を持ち、かつてないほどの省エネと高速化を実現したこの技術は、SF映画で描かれるような「あらゆるモノにAIが宿る世界」を現実のものにするための鍵です。
もちろん、まだ課題がないわけではありません。特定の言語(非英語圏)への対応や、非常に長い文章(コンテキスト)を扱う際の最適化、さらには既存のソフトウェア・エコシステムへの完全な統合など、さらなる研究が必要です [1]。しかし、Microsoftがこの技術をオープンソースとして公開し、すでに多くの開発者がこれを支持しているという事実は、この潮流が本物であることを示しています [1]。
私たちは今、AIが「重くて高価な特別な道具」から、「軽くて安価な、空気のようにどこにでもある存在」へと変わる転換点に立っています。BitNetという魔法の技術が、より持続可能で、より公平で、より便利な未来を切り拓いていくことは間違いありません。
参考資料
1. BitNet b1.58 2B4T Technical Report, https://arxiv.org/abs/2504.12285
2. The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits, https://arxiv.org/abs/2402.17764
3. Microsoft BitNet b1.58 2B4T on Hugging Face, https://huggingface.co/microsoft/bitnet-b1.58-2B-4T
4. BitNet: Scaling 1-bit Transformers for Large Language Models, https://arxiv.org/abs/2310.11453
5. Microsoft BitNet GitHub Repository (bitnet.cpp), https://github.com/microsoft/BitNet
6. The Future of AI Efficiency with BitNet b1.58 and 1-bit LLMs, https://www.cloudthat.com/resources/blog/the-future-of-ai-efficiency-with-bitnet-b1-58-and-1-bit-llms
7. I benchmarked 1 bit models on CPU and the results surprised me - Reddit discussion, https://www.reddit.com/r/LocalLLaMA/comments/1r2ez9c/i_benchmarked_1_bit_models_on_cpu_and_the_results/
8. BitNet: Microsoft's 100B LLM Runs on CPUs, Not GPUs, https://byteiota.com/bitnet-microsofts-100b-llm-runs-on-cpus-not-gpus/
9. The era of 1-bit LLMs: lower compute and costs, https://codingscape.com/blog/era-of-1-bit-llms-lower-compute-and-costs
10. BitNet b1.58 2B4T for Efficient AI Processing, https://dasarpai.com/dsblog/bitnet-b1-58-2b4t-for-efficient-ai-processing/
11. What Happens When You Build an LLM Using Only 1s and 0s?, https://towardsdatascience.com/what-happens-when-you-build-an-llm-using-only-1s-and-0s/
12. BitNet b1.58 2B4T Technical Report on alphaXiv, https://www.alphaxiv.org/overview/2504.12285
13. BitNet b1.58: Microsoft's 1-bit LLMs that run on your CPU, https://dev.to/bspann/bitnet-microsoft-1-bit-llms-that-run-on-your-cpu-20h8
14. Understanding 1-bit LLMs | Paper Notes, https://en.bioerrorlog.work/entry/1-58bit-llm-paper
15. BitNet: Scaling 1-bit Transformers for Large Language Models - JMLR Volume 26, http://www.jmlr.org/papers/volume26/24-2050/24-2050.pdf
16. The Era of 1-bit LLMs: A New Dawn for Powerful and Efficient Language Models, https://anilpise7.medium.com/the-era-of-1-bit-llms-a-new-dawn-for-powerful-and-efficient-language-models-f20b306fb49f
17. BitNet b1.58 vs. LLaMA performance comparison, https://minchocoin.github.io/paper-review/bitnet-scaling-1-bit-transformers-for-large-language-models-review/
18. Discussion on BitNet b1.58 Pareto improvements - Hacker News, https://news.ycombinator.com/item?id=39536673
19. BitNet b1.58 2B4T for efficient local AI workflows, https://www.junia.ai/blog/bitnet-1-bit-model-local-ai-workflows
20. BitNet b1.58: 日本語解説とエネルギー効率, https://qiita.com/tech-Mira/items/67dec9c5a5f025d2727a


コメント