

Googleの最新技術「TurboQuant」をやさしく解説!AIのメモリ不足を解決する魔法の仕組みとは?のPodcast
下記のPodcastは、Geminiで作成しました。

はじめに:AIが抱える「物忘れ」と「メモリ不足」の悩み
人工知能(AI)、特にChatGPTやGeminiのような大規模言語モデル(LLM)は、私たちの生活を劇的に変えつつあります。しかし、これらのAIには、人間と同じように「物覚え」に関する深刻な課題がありました。AIと長い会話を続けたり、分厚い本を一冊丸ごと読み込ませようとすると、コンピュータのメモリ(作業スペース)がすぐに一杯になってしまうのです [1]。
この問題の主な原因は「KVキャッシュ(キー・バリュー・キャッシュ)」と呼ばれる、AIにとっての「一時的なメモ帳」にあります。AIは会話が進むにつれて、これまでのやり取りをこのメモ帳に書き込んでいきますが、会話が長くなればなるほど、メモ帳のサイズは膨れ上がり、最終的にはコンピュータのメモリ限界を超えてしまいます [2]。
これを解決するために、Google Researchが2026年3月に発表したのが、画期的な圧縮技術「TurboQuant(ターボクアント)」です [3]。本記事では、この技術がどのようにしてAIのメモリ不足を解消し、私たちの未来をどう変えるのか、初心者の方にも分かりやすく丁寧に解説します。
TurboQuantの驚異的な性能:6倍小さく、8倍速い
TurboQuantは、一言で言えば「AIの記憶を、賢さを落とさずに極限まで小さくする技術」です。これまでの圧縮技術では、データを小さくするとAIの回答精度が落ちてしまうという弱点がありました。しかし、TurboQuantはこの常識を覆しました [4]。
まず、TurboQuantがどれほど優れた技術なのか、主要な性能を以下の表にまとめました。この数値は、世界最高峰のAI計算機であるNVIDIA H100を用いて測定されたものです [5]。
| 項目 | 従来の標準(FP16/32) | TurboQuant適用時 | 改善効果 |
|---|---|---|---|
| メモリ消費量 | 100% | 約16%以下 | 6倍以上の削減 |
| データの精度 | 16/32ビット | 3ビット 〜 3.5ビット | 極限の圧縮 |
| 計算速度(アテンション) | 1.0倍 | 最大8.0倍 | 8倍の高速化 |
| AIの賢さ(精度) | 基準値 | 変化なし | 精度損失がほぼゼロ |
| 追加の学習 | 必要 | 不要 | 既存AIに即導入可能 |
この数値が示す通り、TurboQuantを使えば、同じメモリ容量で6倍長い会話ができるようになり、しかも返答スピードは最大で8倍も速くなる可能性があります [6]。さらに素晴らしいことに、AIをトレーニングし直す必要がなく、今あるAIにそのまま適用できるのです [7]。
なぜメモリが足りなくなるのか:KVキャッシュの正体
AIが言葉を生成する際、過去のすべての単語との関係性を計算します。この時、一度計算した結果を「KVキャッシュ」という形で保存しておくことで、計算の重複を避けています [8]。しかし、このキャッシュが「データのブラックホール」となってしまうのです。
蓄積の仕組み: AIは一文字生成するごとに、その情報を「ベクトル」と呼ばれる数字のリストとしてメモリに書き込みます。
容量の爆発: 10万トークン(ビジネス書一冊分に相当)の情報を処理しようとすると、このメモ帳だけで数十ギガバイトものメモリを消費します [9]。
ハードウェアの限界: 多くのスマートフォンやパソコンでは、AI本体を読み込むだけでメモリが手一杯であり、長い会話を支えるだけのスペースが残されていません [10]。
TurboQuantは、この「メモリの使い道」を工夫することで、情報の密度を劇的に高めることに成功しました [11]。
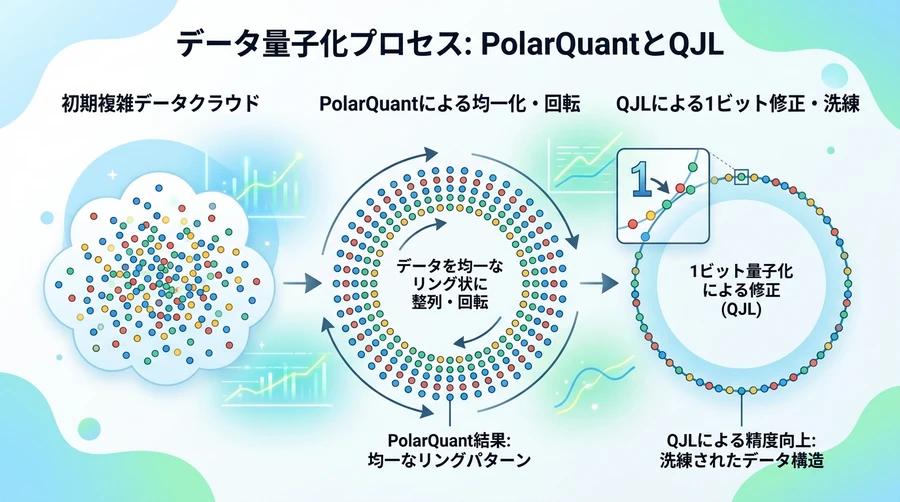
TurboQuantを支える二つの魔法:PolarQuantとQJL
TurboQuantが「精度を落とさずに6倍も圧縮できる」秘密は、二段階の数学的な工夫にあります。それぞれ「PolarQuant(ポラークアント)」と「QJL(量子化されたジョンソン=リンデンシュトラウス変換)」と呼ばれています [12]。
第一段階:PolarQuantによる「幾何学的な整理」
私たちが場所を伝えるとき、「東に3キロ、北に4キロ」と言う代わりに「北東に5キロ」と言うことができます。前者は「直交座標」、後者は「極座標」と呼ばれます。PolarQuantは、AIのデータをこの「極座標(半径と角度)」に変換する手法です [13]。
AIのデータは、多次元空間の中で非常に複雑な形をしており、そのままでは圧縮が困難です。PolarQuantは、まずデータを「ランダムに回転」させます [14]。
回転の魔法: データを回転させると、特定の場所に集中していた数字の偏りが均らされ、非常に予測しやすい分布(ベータ分布)に変化します [15]。
角度の集中: 回転後のデータは、角度の分布が特定の範囲にギュッと集まる性質があります。このパターンは数学的に予測可能であるため、データ一つひとつに詳細な説明書を付ける必要がなくなります [16]。
これにより、余計な説明用データを省きつつ、本質的な情報だけを非常に小さいサイズで保存できるようになるのです [17]。
第二段階:QJLによる「1ビットの誤差修正」
第一段階のPolarQuantで大幅にデータを削ると、どうしても「わずかな誤差」が生まれます。この誤差が積み重なると、AIが言葉の意味を取り違える原因になります。そこで、第二段階のQJLが「お直し」を担当します [18]。
QJLは、PolarQuantで削り落とされた「最後の残りカス(誤差)」を、わずか「1ビット(プラスかマイナスか)」の情報だけで記録します [19]。
誤差のキャッチ: PolarQuantで保存したデータと、元のデータの間の小さなズレを計算します。
数学的な補正: この1ビットの情報を付け加えることで、計算上の「偏り」が魔法のように消え去ります [20]。
数学的に表現すると、元のベクトルを $x$、量子化後のベクトルを $\mathcal{Q}(x)$ とした際、任意ベクトル $y$ との内積の期待値が、元の内積と完全に一致するように設計されています。
この「偏りがない」という性質こそが、極限の圧縮状態でも、AIの「賢さ」を100%維持できる理由なのです [21]。
実証された圧倒的な成果:長文読解でも「完璧」
Googleの研究チームは、このTurboQuantを「Gemma」や「Mistral」、「Llama 3.1」といった世界的に有名なAIモデルに適用し、その性能を厳格にテストしました [22]。
特に注目されたのが、膨大な文章から特定の情報を探し出すテスト(Needle-in-a-Haystack)です。10万文字を超える長文を読み込ませた際、従来の圧縮技術では正解率が大きく下がることがありましたが、TurboQuantは未圧縮のモデルと全く同じ「正解率100%」を維持しました [23]。
また、計算速度の面でも驚くべき結果が出ています。AIがどこに注目すべきかを決める「アテンション計算」において、以下のようなパフォーマンスの向上が確認されました [24]。
| 測定シーン | 速度向上 |
|---|---|
| NVIDIA H100での計算 | 最大8.0倍 |
| メモリ帯域幅の節約 | 約6.0倍 |
| 実際の文章生成速度 | 2〜3倍の高速化 |
これにより、より多くの人が同時にAIを使ってもシステムが重くならず、運営コストも大幅に削減できる可能性があると報告されています [25]。
私たちの生活への影響:スマホが「超・記憶力」を持つ
TurboQuantは、単なる技術的な進歩にとどまらず、私たちの生活を直接的に便利にします。特に「ローカルAI(自分のデバイスで動くAI)」の分野で革命が起きます。
自宅のPCやスマホで「本一冊」を丸暗記
これまでは、自分のパソコンで高性能なAIを動かそうとしても、メモリが足りず、短い会話しかできませんでした。しかし、TurboQuantを使えば、これまでの数倍の情報を覚えさせられます [26]。
具体例: 24GBのメモリを持つPCでも、数十万トークンの資料をすべて読み込ませた状態で、プライバシーを保ちながら高速に相談できるようになります [27]。
AIエージェントが「物忘れ」を克服
最近注目されている「AIエージェント(指示に従って作業を代行するAI)」は、作業時間が長くなるほど過去のステップを忘れてしまい、同じ失敗を繰り返す弱点がありました [28]。
TurboQuantによって記憶のコストが劇減すれば、AIは過去の数百ステップにおよぶ作業内容を一言一句忘れずに保持し続けられるようになります。これにより、より複雑なタスクを任せられる「本当に頼れる相棒」へと進化します [29]。
産業界への影響:メモリ市場の動揺と将来
この技術の発表は、産業界にも波及しました。Googleが「メモリを劇的に節約する技術」を発表したことで、「将来的にメモリチップが売れなくなるのではないか」という懸念が一時的に広がりました [30]。実際、発表直後にはサムスン電子やSKハイニックスといったメモリ大手の株価が急落しました [31]。
しかし、多くの専門家は、長期的にはむしろ「メモリ需要はさらに増える」と予測しています。
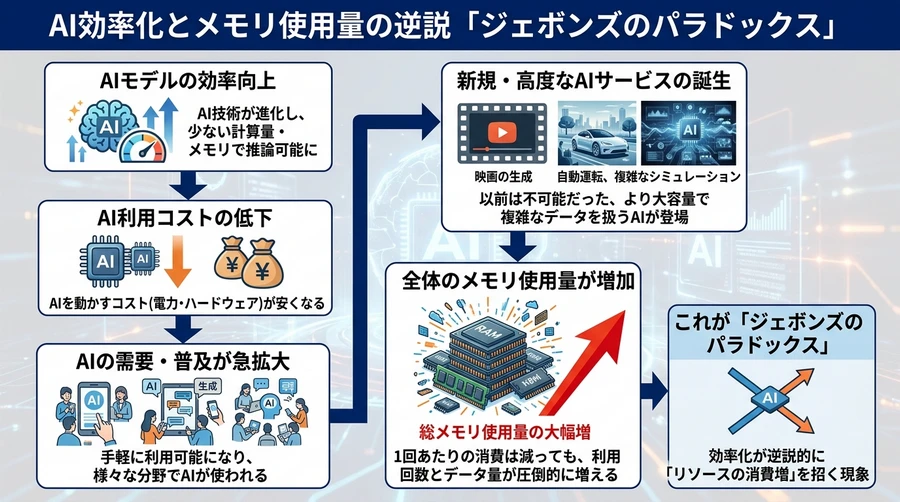
ジェボンズのパラドックス(効率化の逆説)
19世紀の経済学者ジェボンズは「資源の利用効率が上がると、かえってその資源の消費量が増える」という現象を指摘しました [32]。
AIへの適用: メモリが効率的に使えるようになれば、これまでコストのせいで諦めていた「より高度なAI」の利用が爆発的に増えます [33]。
結果: 個々のAIが使うメモリは減っても、AI自体の利用数やモデルの巨大化が進むため、最終的にはより多くのメモリチップが必要になるという、プラスの循環が生まれると考えられています [34]。
開発者と未来:オープンソースへの広がり
TurboQuantは、すでに世界中のエンジニアによって活用され始めています。
コミュニティの動き: すでに「llama.cpp」や「MLX」といった人気のAI実行ツールへの移植が進んでおり、一般のユーザーもその恩恵を受けられるようになりつつあります [35]。
導入のしやすさ: 前述の通り、AIを追加で学習させる必要がないため、モデルをダウンロードして設定をオンにするだけで、即座にメモリを節約できるのが大きな強みです [36]。
Pythonでの利用: デベロッパー向けには簡単に導入できるパッケージも開発されており、AIアプリ開発の現場でも標準的な技術になると見られています [37]。
まとめ:AIの「メモリの壁」は崩れ去った
Google Researchが発表したTurboQuantは、AI技術の発展を妨げてきた「メモリ不足」という最大の障壁を取り除く、極めて重要なブレイクスルーです [38]。
PolarQuantが、データを美しく整理し [39]、QJLが、わずか1ビットの情報で数学的な完璧さを補完する [40]。この二段階の魔法によって、AIは「小さく、速く、そして賢い」まま、私たちの身近なデバイスへと入ってきます。これまでクラウド上のスーパーコンピュータでしかできなかった「超・長文読解」や「複雑な思考」が、あなたのスマートフォンで日常的に行われるようになる日は、すぐそこまで来ています [41]。
参考資料
- Google TurboQuant: Say Bye to GPUs for AI?, https://medium.com/data-science-in-your-pocket/google-turboquant-say-bye-to-gpus-for-ai-fdaf5356c7e0
- How Google's latest AI breakthrough may end global memory shortage problem, https://timesofindia.indiatimes.com/technology/tech-news/how-googles-latest-ai-breakthrough-may-end-global-memory-shortage-problem/articleshow/129829266.cms
- TurboQuant: Redefining AI efficiency with extreme compression, https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
- Google unveils TurboQuant AI-compression algorithm, which it claims can hugely reduce LLM memory usage, https://www.techradar.com/pro/a-high-speed-digital-cheat-sheet-google-unveils-turboquant-ai-compression-algorithm-which-it-claims-can-hugely-reduce-llm-memory-usage
- Google's new AI algorithm that has sent stocks of Samsung and other biggest memory makers plummeting, https://timesofindia.indiatimes.com/technology/tech-news/what-is-googles-new-ai-algorithm-that-has-sent-stocks-of-samsung-and-other-biggest-memory-makers-plummeting/articleshow/129861835.cms
- Google Unveils TurboQuant, a New AI Memory Compression Algorithm, https://www.mitsloanme.com/article/google-unveils-turboquant-a-new-ai-memory-compression-algorithm/
- TurboQuant: Redefining AI efficiency with extreme compression (YouTube), https://m.youtube.com/watch?v=L_kfhB0uMpk
- Google Research TurboQuant: Redefining AI efficiency with extreme compression (Reddit), https://www.reddit.com/r/LocalLLaMA/comments/1s2su28/google_research_turboquant_redefining_ai/
- TurboQuant: What Developers Need to Know About Google's KV Cache Compression, https://dev.to/arshtechpro/turboquant-what-developers-need-to-know-about-googles-kv-cache-compression-eeg
- Googleの「TurboQuant」でメモリ株急落――予想PER6倍台のMicronは"買い場"なのか, https://bloomo.co.jp/learn/library/article/google-turboquant-260327/
- Google TurboQuant: The 2026 LLM Compression Guide, https://o-mega.ai/articles/google-turboquant-the-2026-llm-compression-guide
- A simple explanation of the key idea behind TurboQuant, https://www.reddit.com/r/LocalLLaMA/comments/1s62g5v/a_simple_explanation_of_the_key_idea_behind/
- TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate, https://arxiv.org/abs/2504.19874
- 【論文解説】TurboQuant: KVキャッシュを1/6に圧縮しても精度劣化ゼロ?, https://zenn.dev/kuma18/articles/f66b5f529bc753
- Google Research Outlines Algorithms That May Ease AI Memory Squeeze, https://www.constellationr.com/insights/news/google-research-outlines-algorithms-may-ease-ai-memory-squeeze
- Googleの最新AI技術「TurboQuant」、KVキャッシュを6分の1に圧縮 精度落とさず高速化, https://www.itmedia.co.jp/news/articles/2603/27/news067.html
- Google's TurboQuant: Solving the AI Memory Crisis Without Sacrificing Intelligence, https://beeble.com/en/blog/google-s-turboquant-solving-the-ai-memory-crisis-without-sacrificing-intelligence
- TurboQuant shakes SanDisk: What should you do with SNDK stock now?, https://www.barchart.com/story/news/1012147/googles-turboquant-shakes-sandisk-what-should-you-do-with-sndk-stock-now
- PolarQuant: Vector Quantization with Polar Transformation, https://openreview.net/forum?id=Igzjw1Pkds
- TurboQuant Reference Implementation: Engineering Insights for KV Cache Compression, https://github.com/scos-lab/turboquant


コメント