

AIがもっと身近に!Googleの最新技術「Gemini Embedding 2」で広がる新しい世界のPodcast
下記のPodcastは、Geminiで作成しました。

はじめに
2026年3月10日、Googleは人工知能(AI)の歴史に新たな1ページを刻む革新的な技術を発表しました。それが、最新の埋め込みモデル「Gemini Embedding 2」です [1]。このモデルは、私たちがコンピュータに情報を「理解」させる方法を根本から変えてしまう可能性を秘めています。
これまでのAIは、テキストはテキスト、画像は画像といった具合に、情報の種類(モダリティ)ごとにバラバラに処理する必要がありました。しかし、Gemini Embedding 2は、これらすべての情報を一つの共通の「数学的な空間」で同時に扱うことができる「マルチモーダル」な性質を持っています [1]。
本レポートでは、AIの初心者の方にも分かりやすく、このGemini Embedding 2がどのような仕組みで動き、私たちの生活やビジネスをどう変えていくのかを丁寧に解説します。
エンベディング(埋め込み)とは何か:情報の「意味」を数値化する魔法
まず、そもそも「埋め込み(エンベディング)」とは何でしょうか。専門的な言葉で言えば、「高次元のデータを低次元のベクトルに変換するプロセス」ですが、これでは少し難しく感じてしまいます [2]。もっと親しみやすい例えで説明しましょう。私たちが地図上で場所を探すとき、北緯や東経といった「座標」を使います。エンベディングとは、いわば情報の「意味の地図」における座標を決める技術です [2]。
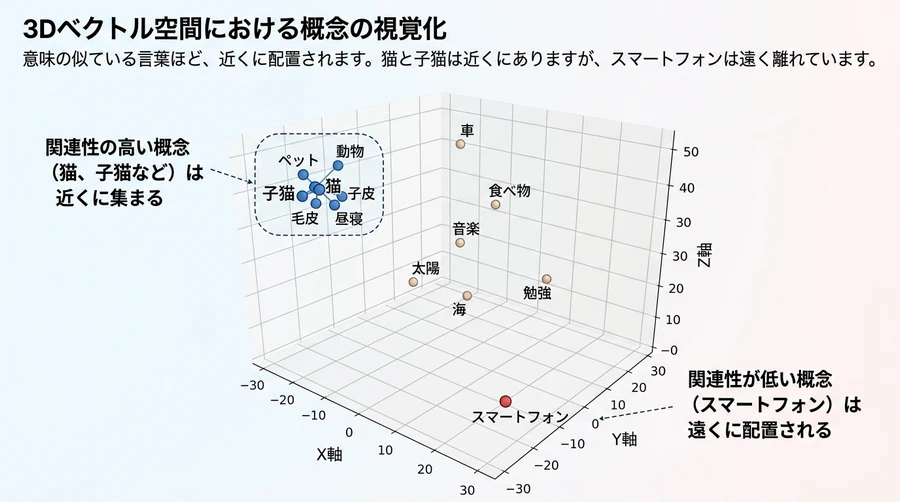
意味が近いものは、近くに配置される
例えば、「猫」と「子猫」という言葉を考えてみましょう。これらは文字こそ違いますが、意味はとても似ています。エンベディングの技術を使うと、コンピュータはこの2つの言葉を、意味の地図上で非常に近い場所に配置します [2]。一方で「猫」と「スマートフォン」は全く違う意味なので、地図上では遠く離れた場所に配置されます [2]。このように、あらゆる情報を「数値の羅列(ベクトル)」に変換し、その数値同士の距離を測ることで、コンピュータは情報の「意味的な近さ」を理解できるようになるのです [2]。
コンピュータが見ている世界
コンピュータは私たちのように「猫」という文字を見て可愛いと感じることはできませんが、ベクトルとして表現された $[0.12, -0.44, 0.03, \dots]$ という数値の集まりを処理することは得意です [2]。Gemini Embedding 2は、この「数値化」の精度が極めて高く、さらにテキスト以外のデータも同じように数値化できる点が画期的なのです [2]。
Gemini Embedding 2が実現する「マルチモーダル」の衝撃
これまでの一般的な埋め込みモデルは、主にテキスト(文字)だけを対象にしていました。しかし、現実の世界には画像、動画、音声、PDFといった多様な情報があふれています。Gemini Embedding 2の最大の武器は、これらすべての情報をたった一つのモデルで、同じ基準の数値(ベクトル)に変換できる「ネイティブ・マルチモーダル」対応にあります [1]。
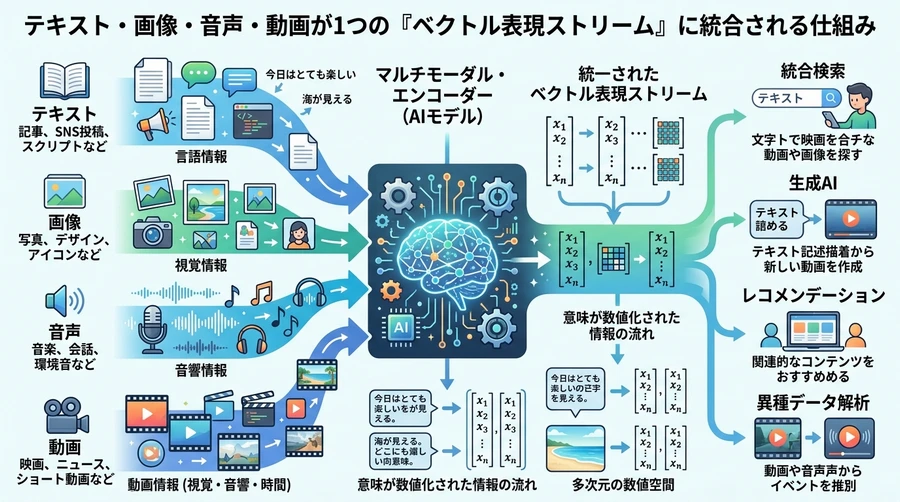
バラバラだった情報が一つにつながる
従来のシステムで「夕焼けの動画」を探そうとした場合、まず動画の中身を文字に起こし、その文字と検索キーワードを照らい合わせるという複雑な工程が必要でした [1]。しかし、Gemini Embedding 2では、動画そのものを直接ベクトルに変換できます [1]。これにより、以下のようなことが可能になります。
クロスモーダル検索: 「波の音がする動画」という言葉(テキスト)を入力するだけで、音声を直接解析して、その特徴に合致する動画ファイルを検索できます [1]。
インターリーブ入力(混ぜこぜ入力): 「この写真に写っている車で、エンジンについて詳しく説明している文書」といった具合に、画像とテキストを組み合わせて一度に処理し、最適な情報を探し出すことができます [1]。
情報の欠落を防ぐ: 文字起こしの過程で消えてしまいがちだった「音声のトーン」や「動画の動き」「資料のレイアウト」といった微細なニュアンスも、AIが直接読み取って数値化してくれます [1]。
Gemini Embedding 2が対応しているデータの種類と、一度に送れるデータの量(制限)は、以下の表の通りです。
| データの種類 | 入力制限(1回のリクエストあたり) | 対応形式 |
|---|---|---|
| テキスト | 最大 8,192 トークン(一般的な本数ページ分) | 文字データ全般 |
| 画像 | 最大 6 枚 | PNG, JPEG |
| 動画 | 最大 120 秒(音声なし) / 80 秒(音声あり) | MP4, MOV |
| 音声 | 最大 80 秒 | MP3, WAV |
| PDF文書 | 最大 6 ページ |
この「一つの空間ですべてを語る」能力は、情報を整理するパイプラインを劇的にシンプルにし、システム全体のスピード(レイテンシ)を最大で70%も向上させたと報告されています [1]。
賢く節約!「マトリョーシカ」技術の秘密
AIの運用にはお金がかかります。特に大量のデータをベクトル化して保存する場合、その「サイズ」が大きな問題になります。Gemini Embedding 2には、この問題を解決するための「マトリョーシカ表現学習(Matryoshka Representation Learning, MRL)」という賢い技術が使われています [3]。
ロシアの入れ子人形のような仕組み
マトリョーシカ人形は、大きな人形の中に一回り小さな人形が入っており、それを開けるとさらに小さな人形が出てきます。これと同じように、MRLで作成されたベクトルは、その「先頭部分」だけに注目しても、情報の重要なエッセンスがぎゅっと詰まっているという特徴があります [3]。
通常、Gemini Embedding 2は3,072個の数値(3,072次元)を使って非常に精密に情報を表現します。しかし、保存コストを抑えたい場合は、この数値の後ろの方を切り捨てて、例えば768個や256個だけを使うことができます [3]。
段階的な検索でスピードアップ
この技術を活用すると、まずは小さいサイズのベクトル(256次元など)を使って数百万件のデータから高速に候補を絞り込み、最後に残った10件だけを精密なベクトル(3,072次元)で精査するという「二段構え」の検索が可能になります [3]。
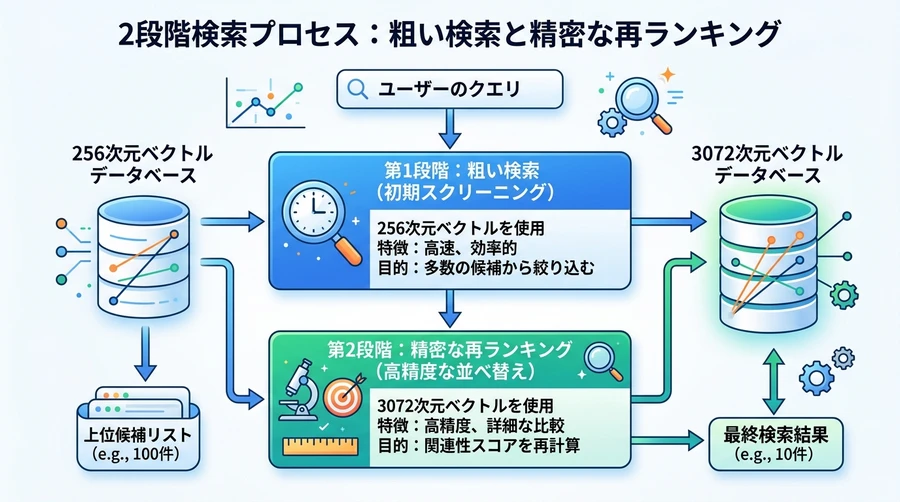
| 推奨される次元数 | 用途とメリット |
|---|---|
| 3,072次元(デフォルト) | 最高の精度が必要な分析や、非常に細かい違いを見分ける際に使用。 |
| 1,536 / 768次元 | 精度とコストのバランスが最も良く、一般的なビジネス用途に推奨。 |
| 128次元〜 | 高速な初期検索や、極限まで保存コストを下げたいモバイル端末内での処理などに適しています。 |
このように、モデルを再学習させることなく、用途に合わせて「サイズ」を自由に変えられる柔軟性が、開発者にとって非常に大きな魅力となっています [3]。
さっそく使ってみよう:Gemini Embedding 2の始め方
「そんなにすごい技術なら、使い方も難しいのでは?」と思われるかもしれません。しかし、Googleが提供する「Google GenAI SDK」を使えば、初心者の方でも驚くほど簡単に使い始めることができます [4]。
準備するもの
Google Cloud または Google AI Studio のアカウント: ここで「APIキー」を取得します [4]。
Python: プログラミング言語ですが、非常にシンプルに書けます [4]。
SDKのインストール: パソコンのターミナル(黒い画面)で `pip install google-genai` と入力するだけです [4]。
基本的なプログラムの例
以下のコードは、ある文章をAIに理解させる(ベクトル化する)ための最も基本的なプログラムです [4]。
python
from google import genai
# クライアントの作成(取得したAPIキーを設定します)
client = genai.Client(api_key="YOUR_API_KEY")
# 文をベクトルに変換(埋め込み)
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents="AIは私たちの生活をより豊かにするパートナーです。"
)
# 生成された数値の集まり(ベクトル)を表示
print(result.embeddings.values)この数行のコードだけで、あなたの入力した言葉が「意味の地図」上の座標に変換されます。
マルチモーダル(画像+テキスト)の例
画像とテキストを組み合わせて一つのベクトルを作るのも簡単です [4]。
python
# 画像ファイルを読み込み
with open("landscape.jpg", "rb") as f:
image_bytes = f.read()
# 画像とテキストを一緒に送る
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
"この写真のような、美しい夕焼けの風景を探して",
{"mime_type": "image/jpeg", "data": image_bytes}
]
)このように、複数の情報を「一つの概念」としてまとめて処理できるのが、Gemini Embedding 2の真骨頂です [4]。
気になるお値段:コストパフォーマンスの高さ
どんなに優れた技術でも、高額すぎては手が出せません。Gemini Embedding 2は、非常に強力な機能を持ちながらも、多くの開発者が利用しやすい価格設定になっています [5]。
料金プランの概要
Gemini APIには、無料枠(Free Tier)と有料枠(Paid Tier)があります [5]。
無料枠: 1分間に数回程度のリクエストであれば、無料で利用できます。個人での学習やプロトタイプの作成に最適です [5]。ただし、入力したデータがモデルの改善に使用される場合がある点には注意が必要です。
有料枠: ビジネスで使用する場合、処理したデータの量(トークン数)に応じて課金されます。
| データの種類 | 有料枠の料金(100万トークンあたり) |
|---|---|
| テキスト / 画像 / 動画 | $0.25 (約40円程度) |
| 音声(ネイティブ処理) | $0.50 (約80円程度) |
※1トークンは、日本語の場合1文字〜数文字程度に相当します [5]。
※音声データはAIにとって処理が重いため「オーディオ・プレミアム」として少し高めの設定になっていますが、文字起こしの手間が省けることを考えれば、トータルのコストは大幅に抑えられるでしょう [5]。
実務での活用シーン:何が良くなるのか?
Gemini Embedding 2を導入することで、具体的に私たちの仕事やサービスはどう変わるのでしょうか。いくつかの具体的な場面を想像してみましょう。
1. 進化したカスタマーサポート(RAG)
最近増えている「AIチャットボット」は、社内マニュアルなどを読み込ませて回答させる「RAG(検索拡張生成)」という仕組みを使っています [6]。Gemini Embedding 2を使えば、これまでは文字しか読めなかったボットが、「マニュアル内の図解」や「操作説明の動画」まで検索対象にできるようになります。ユーザーが「このエラーランプはどういう意味?」と聞けば、AIは画像を直接理解して、最適な解決策を提示できるようになります。
2. 放送・メディア業界での革命
テレビ局や動画配信サービスには、膨大なアーカイブ映像が眠っています。これまでは、人間が手作業で「タグ」を付けて検索できるようにしていました。Gemini Embedding 2を使えば、「緊迫した雰囲気のチェイスシーン」といった抽象的な言葉で、数千時間の映像の中から瞬時に該当する箇所を見つけ出すことができます。音響の効果や視覚的なスリルもAIが直接感じ取っているからです [6]。
3. 多言語ビジネスの強力なサポーター
Gemini Embedding 2は100以上の言語に対応しています [6]。これは単に翻訳ができるということではありません。「日本語のクエリで、英語の技術文書やドイツ語のプロモーション動画を検索する」といった、言語の壁を超えた情報のやり取りが可能になるということです [6]。日本にいながら、世界中の情報を母国語のように扱える時代がやってきます。
まとめ:AIが「世界をそのまま理解する」時代へ
Gemini Embedding 2の登場は、AIが私たちの扱う多様なデータを、より人間に近い感覚で「そのまま」理解し始めたことを意味しています。テキスト、画像、音声をバラバラのデータとしてではなく、一つの豊かな情報のまとまりとして捉えることで、これまでは不可能だった高度な検索や分析が可能になります [1]。
数学的な距離で測る「意味」
最後に、少しだけ専門的な話に触れておきましょう。AIが「似ている」と判断する基準は、ベクトル同士の角度を測る「コサイン類似度」という数式に基づいています [7]。
この式により、1に近いほど「そっくり」、0に近いほど「無関係」と判定されます [7]。Gemini Embedding 2は、この「そっくり度」を判定する能力が、世界最高レベルに達しています [7]。
AIの世界は、日々驚くべきスピードで進化しています。このGemini Embedding 2という新しいツールを手に、ぜひ皆さんも自分だけの画期的なサービスや、便利な道具を作ってみてください。未来はもう、すぐそこにまで来ています [1]。
参考資料
1. Gemini Embedding 2: Our first natively multimodal embedding model, https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/
2. Gemini Embedding 2 model details - Google AI for Developers, https://ai.google.dev/gemini-api/docs/models/gemini-embedding-2-preview
3. What is Matryoshka Representation Learning, https://www.mindstudio.ai/blog/matryoshka-representation-learning
4. Gemini API Docs - Changelog, https://ai.google.dev/gemini-api/docs/changelog
5. Gemini API Pricing, https://ai.google.dev/gemini-api/pricing
6. Build a RAG pipeline with Gemini Embeddings and Vector Search, https://medium.com/google-cloud/build-a-rag-pipeline-with-gemini-embeddings-and-vector-search-a-deep-dive-full-code-bcd521ad9e1c
7. Choosing Embedding Models by MTEB Score, https://app.ailog.fr/en/blog/guides/choosing-embedding-models
AI Visual SuggestionGenerate Image
コサイン類似度:ベクトル間の角度で「意味の近さ」を判定する仕組みのイメージ図A simplified infographic showing the cosine similarity formula applied to two vectors, illustrating how distance equals similarity


コメント