

Googleの新技術「MTP」のPodcast
下記のPodcastは、Geminiで作成しました。

AIの「待ち時間」を解消する魔法の技術:MTPの幕開け
私たちがスマートフォンやパソコンで人工知能(AI)と対話するとき、回答が生成されるまでの数秒間、画面を見つめて待つことがあります。これまでの技術では、AIの「知能」が高まれば高まるほど、その計算は複雑になり、結果として言葉を紡ぎ出すスピードが遅くなるという避けられない問題がありました 。しかし、Google DeepMindが発表した最新のオープンモデル「Gemma 4」ファミリーは、この常識を打ち破る「マルチトークン予測(Multi-Token Prediction: MTP)」という画期的な技術を導入しました 。
MTPは、一言で言えば「AIが未来の言葉を先読みし、まとめて処理する」技術です。従来のAIが一つ一つの文字を順番に、慎重に確認しながら書いていたのに対し、MTPを搭載したAIは数手先までの「下書き」を瞬時に作成し、それをメインの強力なAIがまとめてチェックすることで、生成速度を劇的に向上させます 。Googleの報告によれば、この技術によって、AIの回答品質を一切落とすことなく、処理速度を最大で3倍にまで引き上げることが可能になりました 。
本報告書では、このMTPという技術がどのような仕組みで動いているのか、なぜそれほどまでに速いのか、そして私たちの日常やビジネスにどのような変化をもたらすのかを、専門的な知見に基づきながらも、初めての方に分かりやすく丁寧に解説していきます。
MTPの基本コンセプト

第1章:MTPの正体とその仕組み
AIが言葉を生成する際、内部では「トークン」と呼ばれる文字や単語の断片を積み上げています。これまでの一般的な大規模言語モデル(LLM)は、「自己回帰的生成」という手法を採っていました。これは、前の言葉をすべて読み返してから「次の一文字」を決めるという、非常に几帳面ですが時間のかかる作業です 。
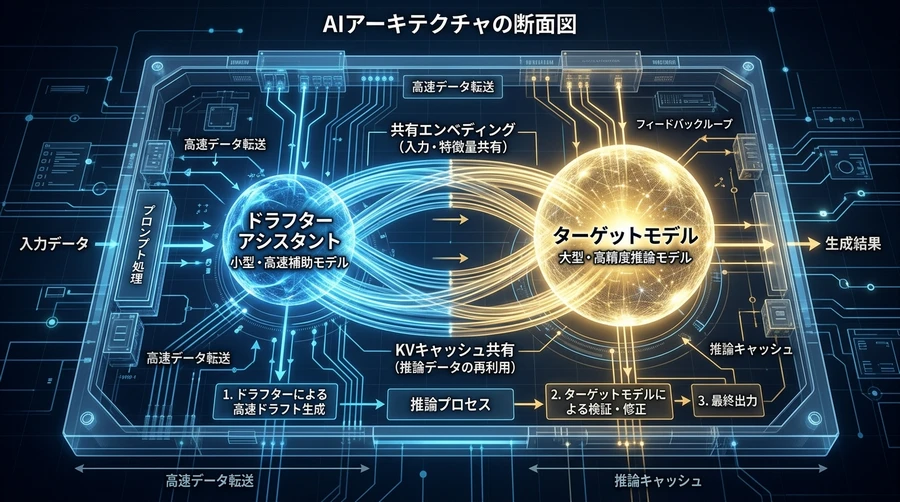
下書き担当と清書担当の連携
MTP(マルチトークン予測)は、この作業を「スペキュラティブ・デコーディング(推測的デコード)」という戦略で効率化します 。このシステムには、役割の異なる二つのAIが登場します。
- ドラフトモデル(Drafter / Assistant): メインのAIよりもずっと小さくて身軽な「アシスタント」です。メインのAIが一つ言葉を選ぶ時間を使って、その先に続くであろう言葉を数個、一気に「下書き」します。
- ターゲットモデル(Target Model): 非常に高い知能を持つ、メインの「責任者」です。アシスタントが持ってきた下書きを一度に読み込み、それが正しいかどうかを並列で検証します 。
もしアシスタントの下書きが正しければ、一度の計算で複数の言葉が完成します。もし間違っていれば、責任者がその場で正解を書き込み、そこからまた作業を続けます。この「まとめてチェックする」仕組みこそが、高速化の最大の秘密です 。
「品質」へのこだわり
多くの方が「推測で言葉を作るなら、間違いが増えるのではないか」と心配されるかもしれません。しかし、MTPの素晴らしい点は、最終的な決定権が常に最強の知能を持つ「ターゲットモデル」にあることです 。下書きが採用されるのは、ターゲットモデルが「これなら自分が出した答えと全く同じだ」と認めた時だけです 。そのため、出力される回答の正確さや論理の鋭さは、MTPを使わない場合と数学的に完全に一致します 。
| 項目 | 従来の方式 | MTP方式 |
| 生成ステップ | 1回につき1文字 | 1回につき複数文字(下書き活用) |
| 速度 | 標準的(モデルの規模に依存) | 高速(最大3倍) |
| 正確性 | モデルの実力通り | 変わらない(同一の品質) |
| 主なメリット | 構造がシンプル | 待ち時間が極めて短い |
第2章:Gemma 4がもたらした技術的ブレイクスルー
MTPという概念自体は以前から存在していましたが、GoogleがGemma 4で行ったことは、その効率を極限まで高めるための「専用設計」です 。単に二つのAIを並べただけではなく、体の一部を共有するかのような深い統合がなされています。
共有される知能のパーツ
Gemma 4のMTPアシスタント(ドラフトモデル)は、メインモデルと以下の要素を共有しています。
- 入力埋め込みの共有(Shared Input Embeddings): 言葉を数字のデータに変換するための「辞書」を、メインモデルと全く同じものを使います。これにより、情報の食い違いを防ぎます 。
- 計算結果の再利用(Target Activation Sharing): メインモデルが一度計算した文脈のデータを、アシスタントがそのまま受け取って予測の材料にします。これにより、アシスタントはゼロから考え直す手間を省き、より正確な「下書き」ができるようになります 。
- メモリ(KVキャッシュ)の共通化: 長い会話の内容を記憶しておくための領域を共有します。これにより、パソコンやスマートフォンのメモリ消費を抑えつつ、長い文章でもスピードを維持できます 。
効率化の工夫:トークン・クラスタリング
Gemma 4の2Bや4Bといった小さなモデル(E2B、E4B)では、さらに「効率的な埋め込み処理(Efficient Embedder)」という技術が使われています 。AIが扱う言葉の数は数十万種類に及びますが、アシスタントがそれらすべてを等しく計算するのは非効率です。そこで、似た意味の言葉をグループ(クラスター)に分け、まずどのグループかを絞り込んでから言葉を選ぶという二段構えの処理を行うことで、驚異的な軽快さを実現しています 。
Gemma 4の内部構造
第3章:驚異のパフォーマンス分析
MTPの導入によって、実際にどれほどの速度向上が得られるのでしょうか。具体的な数字を見ていきましょう。
タスクごとの加速率
MTPの効果は、AIが生成する内容が「どれだけ予測しやすいか」によって変わります 。
- プログラミング(コーディング): プログラムには決まった構文や単語の繰り返しが多いため、アシスタントの予測が非常に当たりやすく、最も大きな効果が得られます。特定の条件下では、標準的な生成に比べて3.82倍という驚異的な加速が記録されています 。
- 数学と論理的推論: 数式や論理の展開も一定のパターンがあるため、3倍以上のスピード向上が期待できます 。
- 一般的な執筆や創作: 物語の展開など、意外性が求められる文章では予測が外れやすくなりますが、それでも1.5倍から2倍程度の速度向上が見込めます 。
| タスクの種類 | 速度向上の目安(倍率) | 理由 |
| コーディング | 3.5倍 〜 3.8倍 | 構文や変数名の予測が容易 |
| 数学的推論 | 3.0倍 〜 3.4倍 | 論理ステップに定型性がある |
| STEM(科学技術) | 2.1倍 〜 2.5倍 | 専門用語や客観的記述が多い |
| 日常会話・執筆 | 1.5倍 〜 1.9倍 | 自由度が高く、意外な展開がある |
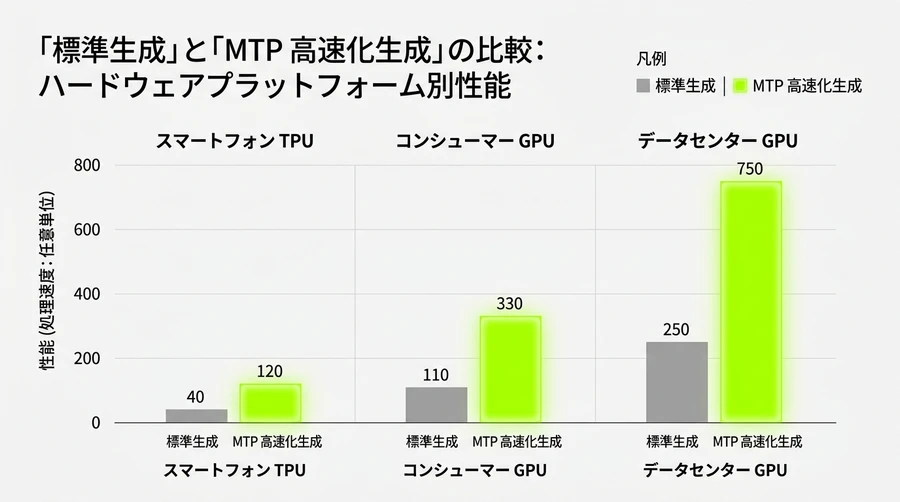
ハードウェア別の実測値
Google A100のような高性能なデータセンター用GPUから、MacBook Pro、さらにはGoogle Pixelスマートフォンのようなモバイル端末まで、幅広い環境でMTPの恩恵を受けることができます 。特に、自分の手元でAIを動かす「ローカルLLM」のコミュニティでは、Apple Silicon上での2.2倍の高速化や、NVIDIA B200での15%のさらなる効率向上が注目を集めています 。
MTPによる生成速度(トークン/秒)の比較
第4章:Gemma 4のラインナップとMTPの適用
Gemma 4には、利用者のニーズや持っている機材に合わせて、いくつかの「サイズ」が用意されています。そして、それぞれのサイズに対して最適化されたMTPアシスタントが存在します 。
モデルサイズの選び方
- E2B / E4B (Edgeモデル): スマートフォンなどのモバイルデバイスに最適な「超軽量」モデルです。MTPを使うことで、クラウドに接続しなくても驚くほど速く、電池の消費を抑えながら動作します 。
- 26B A4B (MoEモデル): 「専門家」を組み合わせて動かす混合専門家(MoE)方式を採用しています。全体では巨大な知能を持ちつつ、推論時には必要な部分だけを動かすため、非常にコスパが良く、256Kという膨大な文章量を一度に読み込めます 。
- 31B (Denseモデル): 最も高い知能を持つ「本格派」です。複雑な論理パズルや高度なプログラミングに向いています。MTPを用いることで、このクラスの重厚なAIでも軽快に動作させることが可能です 。
アシスタントモデルの対応表
MTPを利用する際は、メインのモデル(ターゲット)と同じサイズの「アシスタント(ドラフトモデル)」を一緒に読み込む必要があります 。
| メインモデル | 対応するアシスタント | 特徴 |
| Gemma 4 E2B | gemma-4-E2B-it-assistant | モバイルで爆速動作 |
| Gemma 4 E4B | gemma-4-E4B-it-assistant | 高い日本語性能とスピード |
| Gemma 4 26B A4B | gemma-4-26B-A4B-it-assistant | 膨大な資料の高速読み込みに |
| Gemma 4 31B | gemma-4-31B-it-assistant | 最高レベルの推論を高速化 |
第5章:MTPが私たちの未来をどう変えるか
この「スピードの革命」は、単に文字が早く出るだけではなく、新しいAIの使い方を可能にします。
1. リアルタイムで対話できるエージェント
AIがあなたの代わりに調査をしたり、コードを書いたりする「エージェント」として動くとき、これまではAIが「考えている時間」が長すぎて使いにくい場面がありました。MTPによって応答が3倍速くなれば、まるで人間と話しているかのように、ストレスのない共同作業が可能になります 。
2. インターネットなしでも賢いスマホ
これまで、賢いAIを使うには必ずネット経由で巨大なサーバーにアクセスする必要がありました。しかし、MTPによって効率化されたGemma 4を使えば、飛行機の中や山奥など、ネットがつながらない場所でも、手元のスマホだけで高度な相談ができるようになります 。
3. バッテリーに優しいAI生活
処理が速くなるということは、その分、スマホやPCの頭脳(CPU/GPU)が全力で動く時間が短くなるということです。結果としてバッテリーの節約につながり、外出先でもより長くAIのサポートを受けることができるようになります 。
AIと未来のワークスタイル

運用のためのワンポイント:動的スケジューリング
上級者の方や開発者の方向けに、Gemma 4には「ヒューリスティック・スケジューリング」という賢い機能が備わっています 。これは、AIが会話をしながら「今の話題は予測が当たりやすいから、もっと多めに下書きさせよう」とか「今の話題は難しいから、慎重に一文字ずつ進めよう」といった判断を自動で行う機能です 。これにより、どんな話題でも常に最適なスピードを保つことができます。
まとめ:AIとの新しい関係の始まり
GoogleのMTP技術は、私たちがAIに感じていた「わずらわしい待ち時間」という壁を取り払いました。知能を高く保ったまま、スピードを極限まで高めるこのアプローチは、AIを「特別なツール」から「空気のように当たり前で快適なパートナー」へと変えていくことでしょう 。
Gemma 4ファミリーはオープンな技術として公開されており、誰もがその恩恵を受けることができます 。今日からあなたも、この「言葉を先読みする魔法」を体験してみてはいかがでしょうか。AIとの対話が、これまでとは全く違う、滑らかで心地よいものに変わるはずです。
参考資料
- google/gemma-4-E2B-it-assistant, https://huggingface.co/google/gemma-4-E2B-it-assistant
- Gemma 4 Multi-Token Prediction (MTP) using Hugging Face, https://ai.google.dev/gemma/docs/mtp/mtp
- Accelerating Gemma 4: faster inference with multi-token prediction drafters, https://blog.google/innovation-and-ai/technology/developers-tools/multi-token-prediction-gemma-4/
- Multi-Token Prediction (MTP) for LLaMA.cpp - Gemma 4 speedup by 40% : r/LocalLLaMA, https://www.reddit.com/r/LocalLLaMA/comments/1t6se6r/multitoken_prediction_mtp_for_llamacpp_gemma_4/
- Speed-up Gemma 4 with Multi-Token Prediction, https://ai.google.dev/gemma/docs/mtp/overview
- Google's multi-token prediction drafters: the simple trick that makes Gemma 4 feel faster, https://medium.com/data-science-in-your-pocket/googles-multi-token-prediction-drafters-the-simple-trick-that-makes-gemma-4-feel-faster-82efc15c5205
- Google Speeds Up Gemma 4 Threefold With Multi-Token Prediction, https://forum.gnoppix.org/t/google-speeds-up-gemma-4-threefold-with-multi-token-prediction/5891
- The Local Model That Doesn't Sleep: Gemma 4 MTP as a Marathon Engine, https://dev.to/gde/the-local-model-that-doesnt-sleep-gemma-4-mtp-as-a-marathon-engine-4c9
- Gemma 4 Gets Multi-Token Prediction Drafters: 3x Faster Inference Without Quality Loss, https://www.dsebastien.net/gemma-4-gets-multi-token-prediction-drafters-3x-faster-inference-without-quality-loss/
- Gemma 4 features, performance, and benchmarks, https://ai.google.dev/gemma/docs/core/model_card_4
- Day Zero Launch: Fastest Performance for Gemma 4 on NVIDIA and AMD, https://www.modular.com/blog/day-zero-launch-fastest-performance-for-gemma-4-on-nvidia-and-amd
- Gemma 4 MTP vs DFlash Benchmark, https://jarvislabs.ai/blog/gemma-4-mtp-vs-dflash-benchmark
- Gemma 4 MTP local inference benchmarks, https://medium.com/@kuldeepjadeja7/gemma-4-mtp-local-inference-benchmarks-6711c8589d2f
- Google has announced 'multi-token prediction' that dramatically speeds up large AIs, https://gigazine.net/gsc_news/en/20260507-multi-token-prediction/
- Google Found a Way to Make Local AI Up to 3x Faster—No New Hardware Required, https://decrypt.co/367095/google-make-local-ai-3x-faster-no-new-hardware
- Google: Gemma 4 Multi-Token Prediction Drafters Released To Accelerate AI Inference, https://pulse2.com/google-gemma-4-multi-token-prediction-drafters-released-to-accelerate-ai-inference/


コメント