

- Docker Model RunnerのPodcast
- 導入:AI開発の新しい波とDocker Model Runnerの誕生
- 第1章:Docker Model Runner(DMR)とは?その画期的な仕組み
- 第2章:なぜ今、ローカルAIなのか?3大メリットと実用例
- 第3章:動作環境とシステム要件(お使いのパソコンで動く?)
- 第4章:導入手順:Docker DesktopとDocker Engineでの有効化
- 第5章:実践!基本コマンドでモデルの取得からチャットまで
- 第6章:アプリ開発への応用:Docker Composeでのモデル連携
- 第7章:応用テクニック:モデルのパッケージ化とレジストリ共有
- 第8章:外部ツールやIDE(Cursor、Claude Code、OpenWebUI)との連携
- まとめ:Docker Model Runnerが切り拓くプライベートAIの未来
- 参考資料
Docker Model RunnerのPodcast
下記のPodcastは、Geminiで作成しました。
導入:AI開発の新しい波とDocker Model Runnerの誕生
ChatGPTやClaude、Gemmaといった大規模言語モデル(LLM)の登場により、私たちのソフトウェア開発や日常業務のあり方は劇的に変化しました。プログラミングのコード生成、文章の要約、ブレインストーミングなど、AIは心強いパートナーとなっています。しかし、これらの便利なAIの多くは「クラウド型」であり、利用にあたってはいくつかの現実的なハードルが存在します。
まず、私たちが入力したソースコードや個人情報、機密データがインターネットを介して外部のサーバーに送信され、そこで学習データとして再利用されたり、漏洩したりするリスクが常に付きまといます。また、クラウドAIのAPIを利用すると、リクエストの回数や処理する文字数(トークン数)に応じて課金される「従量課金コスト」が発生し、開発中のテスト段階で思わぬ高額請求を招くことがあります。さらに、海の向こうのサーバーと通信を往復させるために発生するネットワークの「遅延(レイテンシ)」も、開発のテンポを損なう要因となります。
こうした課題を背景に、今、インターネットに接続せず、自分自身のパソコン上でAIを完結させて動作させる「ローカルLLM(ローカルファーストAI)」への注目が世界中で急速に高まっています。しかし、従来のローカル環境構築は、開発者にとって気の遠くなるような作業の連続でした。Pythonのバージョン競合、CUDAドライバのバージョン不整合、依存関係の衝突など、本質的ではない「環境構築エラー」に丸一日を奪われることも珍しくありませんでした。
このような環境構築の「悪夢」を終わらせ、私たちがすでに慣れ親しんでいるDockerの技術を使って、まるでWebコンテナを立ち上げるかのように簡単にローカルAIを管理・実行できるようにしたのが、Docker社が提供する公式ツール「Docker Model Runner (DMR)」です。
Docker Model Runnerは、2025年4月に「Java One 2025」の基調講演においてDocker社のCOOであるMark Cavage氏によって発表され、同社の「Docker Desktop 4.40」にてベータ版としてリリースされました。その後、同年秋の一般提供開始(GA)を経て、多くの開発者が手軽にローカルAI開発のパワーを享受できる環境が整いました。本記事では、このDocker Model Runnerの基礎から応用まで、専門的な視点を交えつつ、初心者の方にも分かりやすく丁寧に解説します。
【Docker Model Runnerの動作イメージ】
第1章:Docker Model Runner(DMR)とは?その画期的な仕組み
Docker Model Runner(DMR)は、コンテナ開発のデファクトスタンダードであるDocker環境において、AIモデル(特にLLMなどの大規模言語モデル)の管理、実行、デプロイを一元化する画期的なツールです。
これまで、AIモデルの配布や共有は非常に無秩序な状態にありました。モデルのファイル(多くは数ギガバイトから数十ギガバイトに及ぶ巨大なバイナリデータ)は、未整理のまま共有フォルダに置かれたり、独自の認証を必要とする専用のダウンロードツールを介して共有されたりしていました。DMRはこの混沌とした状況を、Dockerが長年培ってきた「コンテナイメージの標準」を応用することで解決しました。
DMRでは、AIモデルそのものを「OCI(Open Container Initiative)アーティファクト」と呼ばれる標準規格のパッケージとして扱います。これにより、モデルのダウンロード(Pull)、アップロード(Push)、バージョン管理、タグ付けといった操作を、開発者が使い慣れたいつものDocker CLI(コマンドラインインターフェース)と同じ感覚で行うことができます。たとえば、AIモデルをダウンロードするコマンドは、Webコンテナのイメージを引っ張ってくるコマンドと全く同じ構造になります。
また、DMRの内部設計には非常に優れた「ハイブリッドアーキテクチャ」が採用されています。
通常のコンテナ上でAIモデルを動かそうとすると、仮想マシン(VM)の壁があるために、パソコンのGPU(グラフィックボード)などのハードウェア資源へ直接アクセスすることが難しくなり、処理速度が大幅に低下するという問題がありました。DMRはこの問題を、推論エンジン自体を仮想コンテナの「内側」ではなく、お使い の パソコン(ホストマシン)の「外側」でネイティブなホストプロセスとして直接実行することで完全に解決しました。
この巧みなアプローチにより、仮想化によるオーバーヘッドを一切排除しながら、Apple Silicon(macOS)の「Metal API」や、NVIDIA GPUの「CUDA API」といった強力なグラフィックスハードウェアのパワーを100%直接活用した、極めて高速なAI推論を実現しているのです。
DMRは、以下に示す通り、目的や環境に応じて複数の「推論エンジン」を切り替えて利用することができます。
| 推論エンジン名 | 最も適した用途 | 対応するモデル形式 | プラットフォーム要件 |
| llama.cpp (デフォルト) | ローカル開発、省メモリ環境での効率的な動作 | GGUF形式(量子化された軽量モデル) | macOS, Windows, Linuxすべての環境でCPU・GPU問わず動作 |
| vLLM | 本番運用、高い並行処理能力や処理速度の要求 | Safetensors形式 | NVIDIA製GPUが必須(Linux x86_64、またはWindows WSL2環境) |
| Diffusers | 画像生成(Stable Diffusionなどの利用) | Safetensors形式 | NVIDIA製GPUが必須(Linux環境および特定プラットフォーム) |
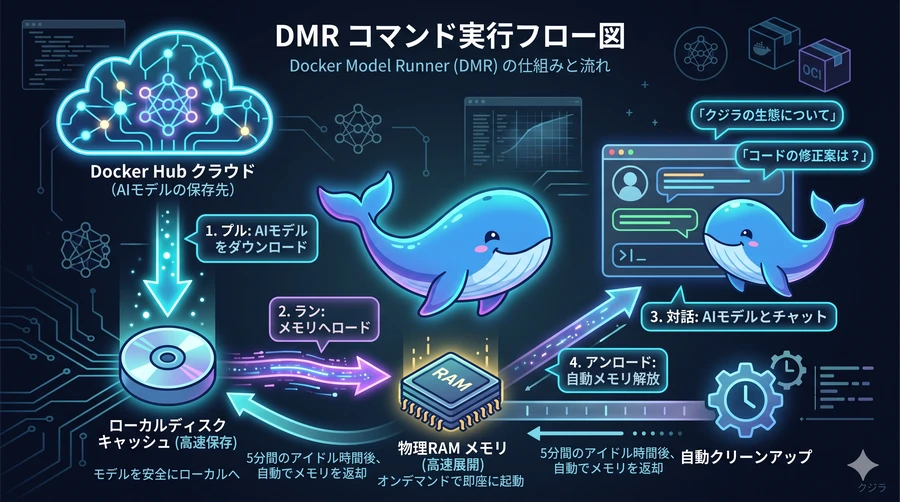
DMRのもう一つの優れた特徴は、「スマートな資源の最適化」です。モデルファイルは非常に巨大であるため、常にパソコンのメモリに展開しておくと、他のアプリケーションの動作を圧迫してしまいます。DMRは、外部からリクエストが届いた瞬間にだけモデルを自動的にメモリへとロードし、その後5分間アクセスがない状態が続くと、自動的にモデルをメモリから降ろして(アンロードして)資源を開放します。このような気の利いたインテリジェントな挙動が、開発者の日常的な使いやすさを支えています。
第2章:なぜ今、ローカルAIなのか?3大メリットと実用例
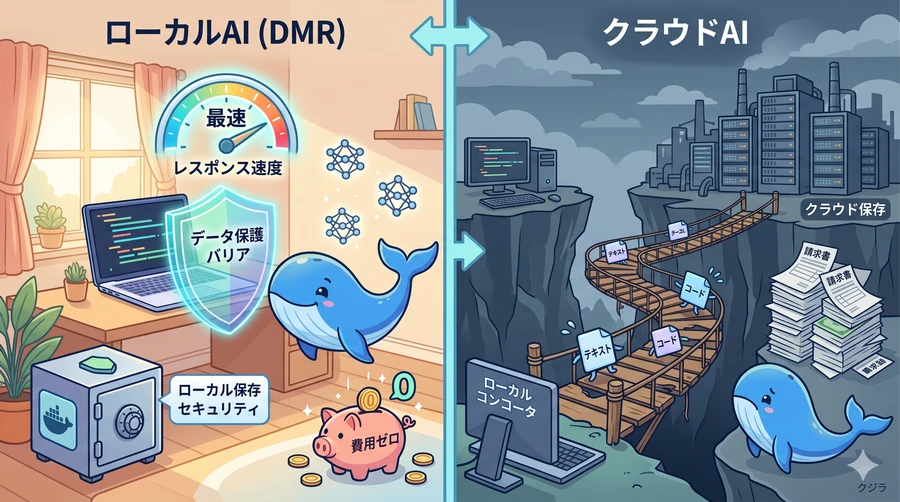
クラウド上で提供される巨大なAIと比べ、手元のパソコンでモデルを動かす「ローカルファースト」のAI開発には、私たちの開発スタイルを大きく変革する3つの明確なメリットがあります。
① プライバシーの保証(データ流出の心配ゼロ)
外部のAIサービスにプログラムのコードや機密資料を読み込ませる際、データが社外に流出してしまわないかという不安は常に付きまといます。Docker Model Runnerを使用すれば、モデルのダウンロード以降のすべての計算処理は、インターネットから遮断されたローカルハードウェア上で完結します。開発中のプロダクトのソースコードや個人的なメモ、企業の顧客データなどが第三者のサーバーに渡って学習に利用されることは、構造上あり得ません。この「Privacy by Design」の思想こそが、金融、医療、エンタープライズ分野の開発でローカルLLMが強く求められる最大の理由です。
② 圧倒的なコスト削減(いくら使っても無料)
クラウドのAPIは、AIに送るプロンプトの長さや、AIが生成した回答の長さ(トークン数)に応じて料金が課金される仕組みです。特にアプリのテストや開発の初期段階では、デバッグのために何度もAIを実行するため、予想外の高額な従量課金が発生してしまうケースがあります。ローカルAIであれば、どれほど大量のテキストを処理させても、発生する費用はパソコンの電気代だけです。料金メーターを気にすることなく、何度でも安心して実験や検証を行うことができます。
③ 開発速度の最大化(超低レイテンシ)
インターネットを経由するクラウドAPIでは、ネットワークの往復時間(通信遅延)を避けることができません。しかし、同じマシン内で動作するDMRへの接続(localhostへのアクセス)であれば、通信遅延はほぼゼロになります。AIのレスポンスが極めて高速になるため、プログラムの開発サイクル(テストして修正するループ)が飛躍的に加速し、開発効率が向上します。
これらのメリットを活かした実用例として、以下のような強力なツールがすでに広く提案されています。
- プライベートコーディングアシスタント「OpenCode」との統合:オープンソースのコーディング支援ツールであるOpenCodeをDMRと組み合わせることで、社外に一切コードを出すことなく、自分の記述したソースコードの補完やレビューを完全にオフラインで実行する、安全なプライベート開発環境が整います。
- 個人用自律型アシスタント「Clawdbot」の構築:TelegramやWhatsAppなどのメッセージングアプリと、ローカルのDMRを連携させることで、ユーザーのプライベートな予定や機密メールを処理し、タスクを自律的にこなす「自分だけのセキュアなAI秘書コンパニオン」を構築することが可能です。
第3章:動作環境とシステム要件(お使いのパソコンで動く?)
Docker Model Runnerは、お使いのOSや利用可能なハードウェアリソースを自動的に検知し、最適な方法で動作するように設計されていますが、ローカルでスムーズに動作させるためには一定の基準を満たす必要があります。事前にご自身のマシンスペックと以下の要件を照らし合わせてみてください。
プラットフォーム別のシステム要件
- macOS(Apple Silicon搭載モデル):M1、M2、M3、M4などのApple製SoCを搭載したMacに対応しています。Docker Desktopバージョン4.40以上が必要です。Apple Siliconに内蔵された高性能GPUを活用するために、Appleの「Metal API」を利用したGPUアクセラレーションが自動で設定されます。
- Windows(amd64 / arm64):Docker Desktopバージョン4.41以上が必要です。
- amd64(通常のIntel / AMD製CPU):NVIDIA製のGPUが必要となり、グラフィックスドライバーのバージョン576.57以上が必須となります。これによって、CUDAを利用した高速な並列処理が有効化されます。
- arm64:Qualcomm Adreno GPU(6xxシリーズ以降)およびOpenCL for Adrenoが必要となります。
- Linux(Docker Engineのみでの稼働):DMRは、CPU単体での動作だけでなく、NVIDIA(CUDA)、AMD(ROCm)、Vulkanなど、極めて幅広いハードウェアアクセラレータに対応しています。特にVulkanのサポート(2025年10月実装)により、特定ベンダーに依存しない多様な内蔵グラフィックスチップでの高速化が可能になりました。NVIDIA GPUを使用する場合は、ドライバーバージョン575.57.08以上が必要となります。
メモリ(RAM)とストレージに関する考慮事項
AIモデルを快適に動かす上で、最も重要なリソースはハードウェアの「メモリ容量」です。 モデルデータがパソコンの物理メモリの容量を超えてしまうと、OSはハードディスク上の仮想メモリ(スワップ領域)を使用せざるを得なくなり、推論処理が急激に遅くなります。一般的に、DMRを利用して軽量なモデルを動かす場合でも、パソコンのメモリは最低16GB以上(可能であれば32GB以上)搭載されていることが強く推奨されます。
【ローカルAI(DMR)とクラウドAIの対比】
第4章:導入手順:Docker DesktopとDocker Engineでの有効化
Docker Model Runnerのセットアップは、お使いの環境(Docker Desktopを使用するか、Linux上のDocker Engineを使用するか)によって異なります。それぞれの具体的な導入手順を丁寧に解説します。
① Docker Desktopでの簡単な有効化(Mac / Windows)
Docker Desktopをお使いの場合、複雑なコマンド入力を行うことなく、設定画面のGUI(ビジュアル操作)だけで簡単にDMRを有効にすることができます。
- Docker Desktopを起動します。
- 画面右上にある歯車のアイコン(Settings)をクリックします。
- 設定画面の左側メニューから「AI」タブを選択します。(注意: バージョン4.45以前の古いDocker Desktopでは、この設定は「Beta features」タブの中に配置されています)。
- 「Enable Docker Model Runner」の設定項目にチェックを入れて有効化します。
- Windows環境で要件を満たすNVIDIA製GPUを搭載している場合は、同時に表示される「Enable GPU-backed inference」にもチェックを入れ、ハードウェア加速を有効にします。
- 外部のアプリケーションプログラムなどからTCP経由でAIに接続したい場合は、「Enable host-side TCP support」にチェックを入れます。ポート番号は標準の「12434」を指定してください。
- 設定を確認し、右下の「Apply & restart(適用して再起動)」をクリックします。
- 再起動後、Docker Desktopのダッシュボード左メニューに「Models」タブが新しく追加されていることを確認します。
② Linux(Docker Engine)でのコマンドによる導入
GUIのないLinuxサーバー環境などでDMRを動作させる場合、Docker公式リポジトリから提供されているプラグインパッケージ「docker-model-plugin」を直接インストールして導入します。
- Ubuntu / Debian系のディストリビューションの場合:Bash
$ sudo apt-get update $ sudo apt-get install docker-model-plugin[cite: 5, 19] - RHEL / Fedora系(RPMベース)の場合:Bash
$ sudo dnf update $ sudo dnf install docker-model-plugin[cite: 2, 20] - Arch Linux(AURパッケージを利用する場合):Arch Linuxユーザーは、コミュニティが管理するAURからパッケージをインストールして利用することも可能です。
開発時のコンパイルに必要な依存関係(CGO dependencies)
DMRのビルドソースやプラグインをソースコード(Go 1.25以上)から直接ビルドしてGPUサポートを有効化する場合、各OSにおける標準的なC/C++開発環境(CGOの依存環境)が必要となります。
- macOS:Xcode Command Line Tools(
xcode-select --install)のインストールが必要となります。 - Linux:
gcc、g++、および各開発用ヘッダーファイル一式が必要となります。 - Windows:MinGW-w64、またはVisual Studio Build Toolsの導入が必要となります。
よくある導入時のエラーと解決方法
- 「
docker: 'model' is not a docker command」というエラーが出る場合:これは、DMRのCLIプラグインがDockerに正しく認識されていない(想定される所定の場所に配置されていない)場合に発生します。macOSでこの問題が発生した場合は、以下のコマンドを実行して、正しいパスへとシンボリックリンクを作成することで解決できます。Bash$ ln -s /Applications/Docker.app/Contents/Resources/cli-plugins/docker-model ~/.docker/cli-plugins/docker-model[cite: 2] - NVIDIA DGXなどのエンタープライズシステムにおけるトラブル:DGXシステムなどにプレインストールされているDockerがOSディストリビューション独自のものである場合、「
Package 'docker-model-plugin' has no installation candidate」というエラーが出てインストールできないことがあります。この場合は、公式のDockerリポジトリの設定手順に従って公式版のDocker Engineを再インストールしてください。また、GPUのCUDAサポートを確実に稼働させるため、DMRを再インストールする際にはコマンドに「--gpu cuda」フラグを添えて再設定を行う必要があります。
第5章:実践!基本コマンドでモデルの取得からチャットまで
環境が整ったら、実際にターミナルからいくつかのコマンドを叩いて、ローカルAIの世界を体験してみましょう。DMRは非常に分かりやすい直感的なコマンド体系を持っています。
① 動いているかチェックする(status / version)
まず、Docker Model Runnerが自身のパソコンのバックグラウンドで元気に稼働しているかを確認します。
Bash
$ docker model status
画面に「Docker Model Runner is running」と表示されれば、稼働状態は完璧です。
② モデルを探してダウンロードする(search / pull)
どのようなモデルがDocker Hubに登録されているかは、コマンドラインから検索することができます。
Bash
$ docker model search
ここでは、非常に軽量で日本語も器用にこなす優秀なオープンソースAIモデル「SmolLM2」の、パラメータ数3.6億、4ビット量子化版モデルをダウンロードしてみます。
Bash
$ docker model pull ai/smollm2:360M-Q4_K_M
AIモデルのファイルは数百MBから数GBと非常に大容量なため、最初のダウンロード(Pull)には少し時間がかかりますが、ダウンロードされたデータはパソコンのローカルディスクに強固にキャッシュされるため、次回からはダウンロード待ちなしで瞬時に起動できるようになります。また、Docker Hubの登録モデルだけでなく、Hugging Faceリポジトリ(hf.co/...)上のGGUF形式のモデルを直接指定してプルすることも可能です。
③ 保存されているモデルを一覧表示する(list / df)
無事にダウンロードできたか、ローカルに保存されているモデルを確認します。
Bash
$ docker model list
さらに、ダウンロードしたAIモデル群がハードディスクの空き容量をどれくらい消費しているか確認したいときは、以下のディスク使用量確認コマンドが便利です。
Bash
$ docker model df
④ AIを動かしてチャットする(run)
いよいよ、AIとの対話に挑戦してみましょう。最も簡単な方法は、コマンドの後ろに直接、一度限りの質問(プロンプト)を入力して実行する方法です。
Bash
$ docker model run ai/smollm2:360M-Q4_K_M "クジラの生態について1文で説明してください。"
コマンドを送信すると、DMRが裏側でモデルをメモリにロードし、即座に「クジラは最大の哺乳類であり、海洋生態系の維持に極めて重要な役割を果たしています」といった的確な回答を出力します。
さらに、LINEやChatGPTのようにリアルタイムで何度もやり取りを続けたい場合は、プロンプトを付けずにモデル名だけでコマンドを実行し、「インタラクティブ対話モード」に入ります。
Bash
$ docker model run ai/smollm2:360M-Q4_K_M
実行するとターミナルが入力待ち状態(>)になります。
Interactive chat mode started. Type '/bye' to exit.
クジラの寿命はどれくらいですか?
種によって異なりますが、多くのクジラは50〜100年生き、ホッキョククジラなどは200年以上生きることもあります。
/bye
対話を終了していつものシステムコンソールに戻りたいときは、ターミナル上で「/bye」と入力してEnterを押すか、ヘルプが必要な場合は「/?」を入力します。
⑤ ログの監視とモデルの片付け(logs / unload / rm / purge)
- ログを表示する:AIが処理中にどのような動きをしているかを開発用に見たい場合は、ログコマンドを使用します。Bash
$ docker model logs - 稼働中のモデルを確認する:現在メモリにロードされて「活動中」のモデルを確認できます。Bash
$ docker model ps - モデルを明示的に片付ける(アンロードする):自動アンロード(5分)を待たずに、手動で今すぐメモリからモデルを解放したい場合は、アンロードコマンドを実行します。Bash
$ docker model unload ai/smollm2:360M-Q4_K_M - 不要なモデルを削除する:パソコンのストレージが圧迫されてきたら、削除コマンドでモデルを綺麗に消去できます。Bash
$ docker model rm ai/smollm2:360M-Q4_K_Mすべてのダウンロード済みローカルモデルを一撃で一掃したい場合は、docker model purgeを利用します。
Docker Desktopならではのビジュアルな「リクエスト監視」
Docker DesktopのGUI(グラフィカルな管理画面)を活用すると、実行したプロンプトやモデルのパフォーマンスを視覚的にチェックすることができます。 Docker Desktopの「Models」メニューを開き、「Requests」タブを選択します。この画面では、実行されたリクエストの送信時刻、使用されたトークンの消費量、レスポンスの生成速度(Tokens per second)、そして実際にやり取りされた完全なJSONデータ(APIリクエストとレスポンスの本体)などを、ブラウザ感覚で隅々まで検査・診断することができます。
【基本コマンド(Pull、Run、List、Unload)のデータフロー】
第6章:アプリ開発への応用:Docker Composeでのモデル連携
Docker Model Runnerの真骨頂は、開発中のWebシステムなどの複数のコンテナサービスと、AIモデルを「Docker Compose」を介して一本化し、コード一行で連動させてデプロイできるポータビリティにあります。
Composeファイルでのモデルの定義方法
Docker Compose(バージョン2.38以降)では、従来の services、networks、volumes に並ぶトップレベルの要素として、AIモデル専用の定義セクションである「models」を宣言できるようになりました。以下に、実践的なマルチサービス連携を想定した、標準的な compose.yaml の記述例を示します。
YAML
version: '3.8'
services:
# 自作の対話型チャットアプリケーション(Node.jsやPythonなどで構築)
web-app:
image: my-chat-app:1.0
ports:
- "3000:3000"
models:
- llm # 下の「models」セクションで定義したAIモデルに依存することを明示
extra_hosts:
- "model-runner.docker.internal:host-gateway" # コンテナからホストのDMRへ届くようにネットワークを設定
# Docker Compose内でAIモデルをファーストクラスのオブジェクトとして定義
models:
llm:
model: ai/smollm2:360M-Q4_K_M # ダウンロード・実行対象のモデルを指定
context_size: 4096 # このモデルに割り当てる最大トークン長(文脈記憶容量)
runtime_flags:
- "--temp"
- "0.7" # 回答のランダム性を程よく制御
- "--threads"
- "4" # 推論に使用するCPUスレッド数を手動で固定
接続情報を繋ぐ「環境変数」の自動注入システム
DMRが有効化されたDocker環境で上記の docker compose up -d コマンドを実行すると、Docker Composeはモデルの起動確認を行った後、紐付けられたアプリケーションコンテナ(web-app)の中に、以下の環境変数を自動的に動的注入(インジェクション)してくれます。
LLM_URL:コンテナ内のプログラムが、起動したローカルAIへ接続するためのOpenAI互換のAPIエンドポイントURL。LLM_MODEL:実際に呼び出すべきモデルの識別名称。
これによって、私たちが開発するコード側では、面倒な接続先のホスト名や複雑なURLをプログラム内に直接ハードコード(直書き)して管理する必要が一切なくなります。プログラムは単純に、OSに設定された環境変数 LLM_URL から接続先を読み取るだけで、完全にローカルに閉じられたセキュアなAIサーバーへと安全にメッセージを届けることができるのです。
ネットワーク接続先(ポート)の確認
アプリケーションコードからDMRにアクセスする際のベースとなるURLは、プログラムが「どこで動いているか」によって使い分けます。
- 同一のDockerコンテナ内部から接続する場合:
http://model-runner.docker.internal/engines/llama.cpp/v1/(Docker Engineを利用している場合は、ホストのゲートウェイを解決するextra_hostsの設定を推奨します)。 - ご自身のパソコン(ホストプロセス)から直接接続する場合:DMRの設定でTCPアクセスを有効化した状態で、
http://localhost:12434/engines/v1またはDMR内蔵エンジンのポート「http://localhost:8080」をエンドポイントに指定します。
また、Dockerの「Compose Bridge」と呼ばれる最新のブリッジシステムと併用することで、ローカルのDocker Compose用に書いたこの compose.yaml ファイルをベースにHelm Chartなどを自動生成し、ローカルのDocker Desktop環境から、クラウド上の大規模なKubernetes(K8s)本番環境へと、システム設計をそのままシームレスに移植・デプロイすることも可能になっています。
第7章:応用テクニック:モデルのパッケージ化とレジストリ共有
Docker Model Runnerに慣れてきたら、お使いのAIモデルの各種設定を自分好みに微調整してカスタマイズしたり、自分たちのチームで共有するためのプライベートモデルを構築・配布してみましょう。
① コンテキストサイズ(記憶領域)のチューニング
AIモデルには、一度に処理できる情報の限界を示す「コンテキストサイズ(最大文脈トークン数)」が設定されています。デフォルトの設定値(通常は2,048〜8,192トークン)のままだと、長大なプログラムコードをAIに入力した際に、エラーになってしまったり古い会話の履歴を忘れてしまったりすることがあります。 以下の設定コマンドを使用すれば、特定のモデルに割り当てるメモリ領域(コンテキストサイズ)を拡大することができます。
Bash
$ docker model configure --context-size 8192 ai/smollm2:360M-Q4_K_M
重要:メモリ消費量への影響に注意!
コンテキストサイズを不用意に広げすぎると、推論サーバーが必要とするメモリ容量(RAM/VRAM)が劇的に増加します。大まかな目安として、コンテキストの長さを1,000トークン増やすごとに、約100MB〜500MBもの追加の物理メモリが消費されるため、お使いのパソコンの空きメモリ状況を確認しながら適切に加減を行う必要があります。もしコンテキストサイズをデフォルト値に安全にリセットしたい場合は、値を
-1に指定してコマンドを実行します。Bash
$ docker model configure --context-size -1 ai/smollm2:360M-Q4_K_M[cite: 2, 5]
② docker model package コマンドを使ったモデルのコンテナ化
Hugging Faceなどから個人的に入手した生のGGUFファイル、あるいはSafetensors形式のモデルファイルを、Docker環境で配布しやすいように「OCIアーティファクト(Dockerイメージのようなもの)」として独自にパッケージングすることができます。
パッケージ化には docker model package コマンドを使用します。
Bash
$ docker model package --gguf "/path/to/my-custom-model.gguf" --context-size 16384 myorg/custom-model:1.0
このコマンドを実行すると、指定されたGGUFファイルが、設定したコンテキストサイズ情報と共にひとまとめにされたDocker準拠の「OCIアーティファクト」へと生まれ変わります。このパッケージ化によって、モデル固有のコンテキストサイズなどのチューニング情報をファイルそのものに恒久的に「焼き付ける」ことができるため、配布先での複雑な再設定の手間を完全に省略できるようになります。
③ docker model push によるプライベートレジストリ共有
パッケージ化を終えたあなた独自のカスタムAIモデルは、普段のコンテナ開発と同じようにDocker Hubや、GitHub Packages (GHCR.io) などの社内プライベートレジストリへ自由にアップロード(Push)して、チームメンバーや世界中の開発者へ向けて安全に配布・公開することができます。
Bash
# 1. 独自の組織アカウント名などを添えてタグ付けを行います
$ docker model tag myorg/custom-model:1.0 myorg/my-private-model:latest
# 2. レジストリへ向けてプッシュを実行します
$ docker model push myorg/my-private-model:latest
これにより、チーム内の他のメンバーは、ご自身のパソコン上で docker model pull myorg/my-private-model:latest コマンドを実行するだけで、同じ設定が適用された高精度なチューニング済みモデルを、一切の手間なしに即座に共有・利用開始することが可能になります。
第8章:外部ツールやIDE(Cursor、Claude Code、OpenWebUI)との連携
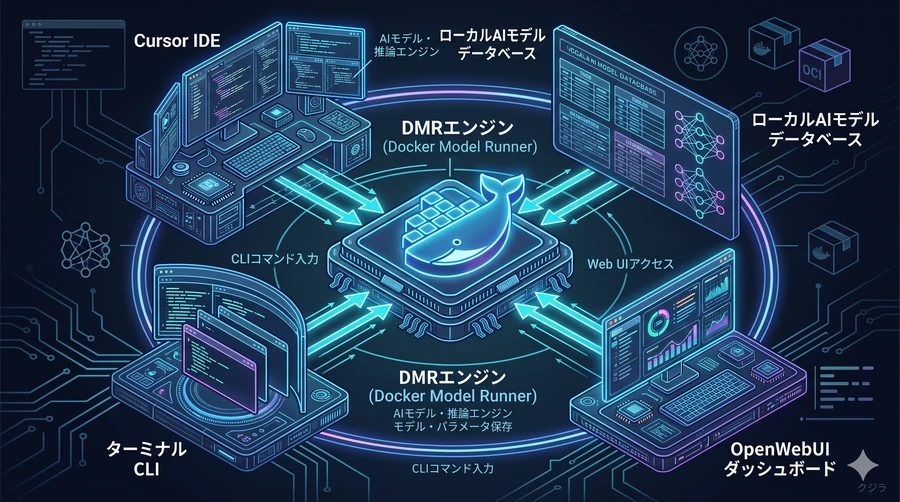
Docker Model Runnerは、世の中の主要なAI SDK(OpenAI SDKやOllama SDKなど)と最初から完全な互換性を持っているため、人気の高い各種AI搭載の統合開発環境(IDE)や、高機能なWebフロントエンドツール群の「頭脳」として、すぐその場ではめ込んで活用することができます。
- ChatGPT風の本格Web UI:OpenWebUIとのDocker Compose統合:まるで本家のChatGPTを使っているかのような洗練されたWeb対話画面をローカルに構築したい場合は、オープンソースの「OpenWebUI」コンテナと、DMRをDocker Composeファイルで連結して立ち上げるのが最適です。これにより、お使いのブラウザから直接ローカルAIへ綺麗な画面を介してアクセスし、やり取りを行うリッチなプライベート対話システムがわずか数分で手に入ります。
- AIコーディングアシスタント(Cursor、Claude Code、Continue):近年爆発的な普及を見せる「Cursor」や「Aider」といったAIエディタ、またAnthropic社が提供するターミナル用開発アシスタント「Claude Code」、VS Codeなどの拡張機能「Continue」や「Cline」の接続設定画面を開き、APIの宛先を
http://localhost:12434/engines/v1へと切り替えるだけで、これらがローカルのDMRを利用するようになります。インターネットを介さないため、社外秘のソースコードを安心して記述・リファクタリングさせることができます。また、docker model skillsコマンドを使用すれば、AIアシスタントがDMRをより深く活用するための機能プラグインをコマンド一発で追加インストールすることも可能です。
【ローカルIDEやWeb UIがDMRに接続する全体像】
まとめ:Docker Model Runnerが切り拓くプライベートAIの未来
本記事では、Docker DesktopおよびDocker Engineの革新的な機能「Docker Model Runner(DMR)」について、その仕組み、動作環境、基本コマンド、Compose開発への統合方法、精度向上から高度なモデル管理までを網羅してご紹介しました。
DMRの登場は、単に「ローカルAIがちょっと簡単に動かせるようになった」というレベルの進化にとどまりません。AIモデルをコンテナと同じ「第一級のオブジェクト(OCIアーティファクト)」として標準化し、パッケージ管理のライフサイクルへと綺麗に組み込んだ点において、今後のソフトウェアエンジニアリング全体に極めて大きなパラダイムシフトをもたらすものです。
また、今後は「Docker AI Governance」などの一元管理システムの登場により、AIエージェントがアクセス可能なネットワークの範囲や、使用できるAPI認証情報、外部ツール連携の権限などを、企業のシステム管理者が中央から安全にガバナンス管理・制御する機能の強化も予定されています。
開発コスト、情報セキュリティ、ネットワーク遅延など、クラウドAIの運用におけるあらゆる「見えないストレス」からデベロッパーの作業環境を解放してくれるDocker Model Runnerは、これからのAI開発の確固たる第一歩となります。まずは一番軽量なモデルをひとつ、あなたのご自身のマシンにダウンロードし、安全・自由な「クジラ印のプライベートAIライフ」の一歩を踏み出してみませんか。
参考資料
- GitHub - docker/model-runner、https://github.com/docker/model-runner
- Docker Model Runner: Run AI Models Locally with Full Control | Docker、https://www.docker.com/products/model-runner/
- Docker Model Runner Docs、https://docs.docker.com/ai/model-runner/
- Introducing Docker Model Runner - Docker Blog、https://www.docker.com/blog/introducing-docker-model-runner/
- ローカルLLMを簡単に動かせる!Docker Model Runner試してみた - DTS Tech Blog、https://dts-digital.jp/cloud/tech-blog/20251023.html
- LLM を簡単にローカルで実行できる Docker Model Runner - DevOps Hub、https://licensecounter.jp/devops-hub/blog/docker-modelrunner/
- What is Docker Model Runner, its key features, and requirements? - Docker Docs、https://docs.docker.com/ai/model-runner/
- Define AI Models in Docker Compose - Docker Docs、https://docs.docker.com/ai/compose/models-and-compose/
- How Docker Model Runner Works - Docker Docs、https://docs.docker.com/ai/model-runner/
- Use Docker Model Runner with Compose Bridge - Docker Docs、https://docs.docker.com/compose/bridge/use-model-runner/
- Running AI Models with Docker Compose - Dev.to、https://dev.to/pradumnasaraf/running-ai-models-with-docker-compose-27ng
- Docker Model Runner Demystified - Medium、https://medium.com/@bhaskaro/docker-model-runner-demystified-a-practical-guide-to-running-local-llms-like-containers-895af3ddcb0c
- How to use this compose file to run Open WebUI - Gist、https://gist.github.com/BretFisher/aafd46eeb7acef2f5ef7d1ea70abe2ad
- Docker Model CLI README、https://github.com/docker/model-runner/blob/main/cmd/cli/README.md
- DMR を始める - Tadashi0713 Dev Docs、https://docs.tadashi0713.dev/ai/model-runner/get-started
- CLI reference: docker model - Docker Docs、https://docs.docker.com/reference/cli/docker/model/
- docker model run CLI Reference - Docker Docs、https://docs.docker.com/reference/cli/docker/model/run/
- Docker Model Runner Tutorial - Geshan、https://geshan.com.np/blog/2026/01/docker-model-runner/
- Docker Model Runner Cheatsheet - Glukhov、https://www.glukhov.org/llm-hosting/docker-model-runner/docker-model-runner-cheatsheet/
- Docker Model Runner GitHub Repository、https://github.com/docker/model-runner
- docker-model-plugin - Arch Linux AUR、https://aur.archlinux.org/packages/docker-model-plugin
- Docker Model Runner Tutorial - DataCamp、https://www.datacamp.com/tutorial/docker-model-runner
- Docker model not available? - NVIDIA Forums、https://forums.developer.nvidia.com/t/docker-model-not-available/357788
- ローカルLLMを簡単に動かせる!Docker Model Runner試してみた 詳細検証レポート - DTS Tech Blog、https://dts-digital.jp/cloud/tech-blog/20251023.html
- LLM を簡単にローカルで実行できる Docker Model Runner 詳細機能解説 - DevOps Hub、https://licensecounter.jp/devops-hub/blog/docker-modelrunner/
- Run Claude Code Locally with Docker Model Runner - Docker Blog、https://www.docker.com/blog/run-claude-code-locally-docker-model-runner/
- OpenCode and Docker Model Runner: Private AI Coding - Docker Blog、https://www.docker.com/blog/opencode-docker-model-runner-private-ai-coding/
- docker model package CLI Reference - Docker Docs、https://docs.docker.com/reference/cli/docker/model/package/
- DMR Setup and Request Inspection - Tadashi0713 Dev Docs、https://docs.tadashi0713.dev/ai/model-runner/get-started
- Clawdbot with Docker Model Runner: Private Personal AI Assistant - Docker Blog、https://www.docker.com/blog/clawdbot-docker-model-runner-private-personal-ai/
- Docker Model Runner: Context Size Config Guide - Glukhov、https://www.glukhov.org/llm-hosting/docker-model-runner/context-size-in-docker-model-runner/
- docker model Subcommands List - Docker Docs、https://docs.docker.com/reference/cli/docker/model/
- docker model push CLI Reference - Docker Docs、https://docs.docker.com/reference/cli/docker/model/push/
- DMR Cheatsheet: Environment and GPU Configuration - Glukhov、https://www.glukhov.org/llm-hosting/docker-model-runner/docker-model-runner-cheatsheet/
- Running LLMs Locally with Docker - Paradigma Digital、https://en.paradigmadigital.com/dev/running-llms-locally-docker/
- Stop Paying For AI APIs You Don't Need: Docker Model Runner Changes Everything、https://blog.devops.dev/stop-paying-for-ai-apis-you-dont-need-docker-model-runner-changes-everything-f7e24ca943fc

コメント