

- 「GBrain」のPodcast
- はじめに:AIエージェントの宿命である「もの忘れ」と、それを解決するGBrainの誕生背景
- 第1章:使えば使うほど賢くなる!GBrainを支える画期的な「循環設計」と2層構造
- 第2章:裏側はどうなっている?Markdown、Postgres、そして超軽量PGLiteの強力なタッグ
- 第3章:比較表でスッキリ納得!従来のRAGやグラフDBと何が違うのか
- 第4章:初心者でも今すぐ試せる!GBrainの導入から運用までの簡単7ステップ
- title: Alice Chen aliases: [アリス・チェン]
- Compiled Truth
- Timeline
「GBrain」のPodcast
下記のPodcastは、Geminiで作成しました。
はじめに:AIエージェントの宿命である「もの忘れ」と、それを解決するGBrainの誕生背景
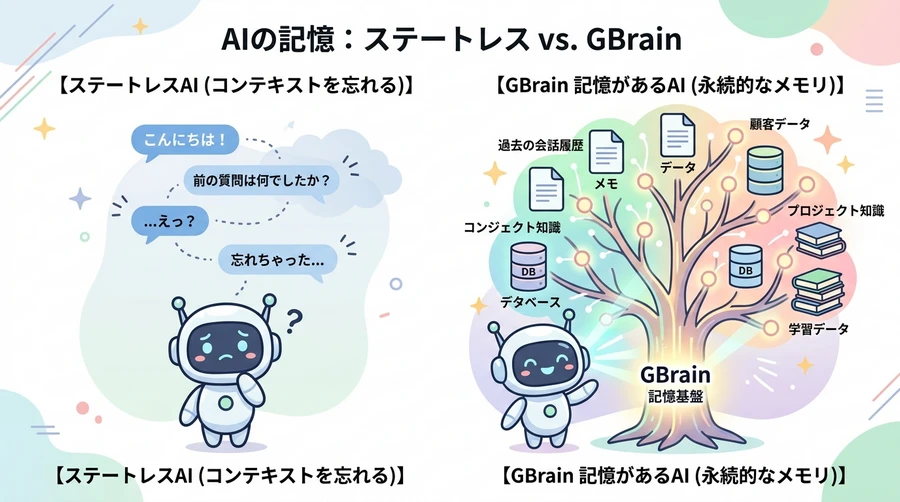
昨今の人工知能(AI)エージェントや大規模言語モデル(LLM)の進化には目を見張るものがあります。しかし、どんなに優秀なAIであっても、共通する大きな課題が存在します。それは、対話のセッション(接続)が切れるたびに、過去に話した内容や決定事項をすっかり忘れてしまう「記憶喪失(アムネシア)」の問題です 。一般的なチャットツールや開発支援AIは、新しい会話を開始するたびにコンテキスト(文脈)がリセットされるため、過去の対話や利用者の生活背景、ビジネス上の意思決定といった重要な流れを引き継ぐことが困難でした。
この「ステートレス(状態を持たない)」というAIの限界に挑戦するため、Y Combinatorの社長兼CEOであるギャリー・タン(Garry Tan)氏は、自身のAIエージェントに持続的で強固な記憶能力を与えるシステムを自ら開発しました 。そして2026年4月5日、そのシステムは「GBrain」として、商用・個人利用を問わず無償で改変可能なMITライセンスのもと、オープンソースとして一般公開されました 。公開からわずか24時間で5,000以上のStarを獲得し、瞬く間に14,000Starを超えるほどの爆発的な注目を集めています 。
GBrainは、単に過去の対話ログをテキストファイルとして保存するだけのものではありません。利用者が日々の会議、電子メール、SNS(Xなど)の投稿、音声メモ、個人的なアイデアなどを流し込むことで、AIがそれらを自律的に解析し、相互に関連付けられた「知識グラフ(パーソナル・ブレイン)」を構築します 。GBrainを数ヶ月にわたって使い続けることで、AIは利用者のビジネスネットワーク、投資実績、過去の会話相手の関心事などを完全に把握し、使えば使うほどに「賢さが複利(コンパウンド)のように増していく」という独自の特長を持っています 。
【AIの記憶喪失を防ぐGBrainの仕組み】
第1章:使えば使うほど賢くなる!GBrainを支える画期的な「循環設計」と2層構造
GBrainが他の類似するナレッジ管理ツールやRAG(検索拡張生成)システムと一線を画しているのは、長年の運用経験と実践的な知見から設計された「3つのユニークな仕組み」があるからです 。
記憶の2層構造:「Compiled Truth(まとめ)」と「Timeline(事実の積み重ね)」
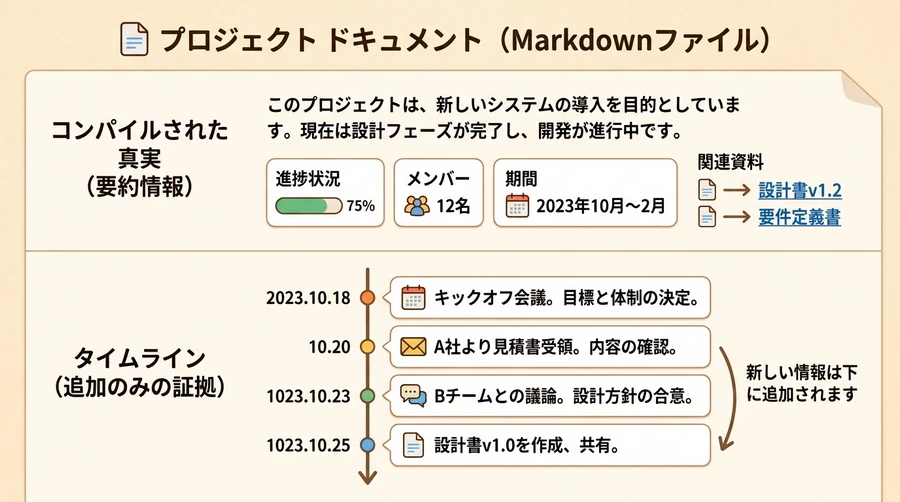
一般的なノートツールでは、情報が更新されるたびに古い情報が上書きされて消えてしまうか、あるいは過去の古いログがそのまま残って最新の状況がわからなくなるというジレンマがありました。GBrainは、すべての記憶ページを厳格に「2つの領域」に分割することでこの問題を解決しています 。
- Compiled Truth(集約された真実): ページの最上部に位置する、現時点における「最新かつ最善の理解」を要約したセクションです 。AIエージェントが利用者の質問に対して素早く回答を導き出すために、情報は新しいエビデンス(証拠)が得られるたびにAIによって動的に書き換えられます 。
- Timeline(タイムライン): ページの下部に位置する、日付順に記録された「変更不可能な事実ややり取りの履歴(証拠)」のセクションです 。電子メール、会議の書き起こし、電話の履歴などが時系列のまま追記(アペンド)され、過去の記録が書き換えられたり消去されたりすることはありません 。
この「解釈」と「事実(エビデンス)」を完全に分離する構造により、情報の更新プロセスが極めて明確になります 。また、集約された真実の内容が最新のタイムライン情報よりも古くなっている場合、システムが「情報が古い可能性がある(Stale Alert)」と自動で警告(アノテーション)を発する仕組みも備わっています 。
【Compiled TruthとTimelineの2層構造】
AIの頭を整理する夜の「ドリームサイクル(夢時間)」
利用者が日中に活動している間、GBrainには会議の議事録や電子メールなどのさまざまな情報が次々と流れ込みます。しかし、それらをリアルタイムに整理・統合しようとすると、AIの動作が重くなったり、APIコストが膨らんだりしてしまいます。
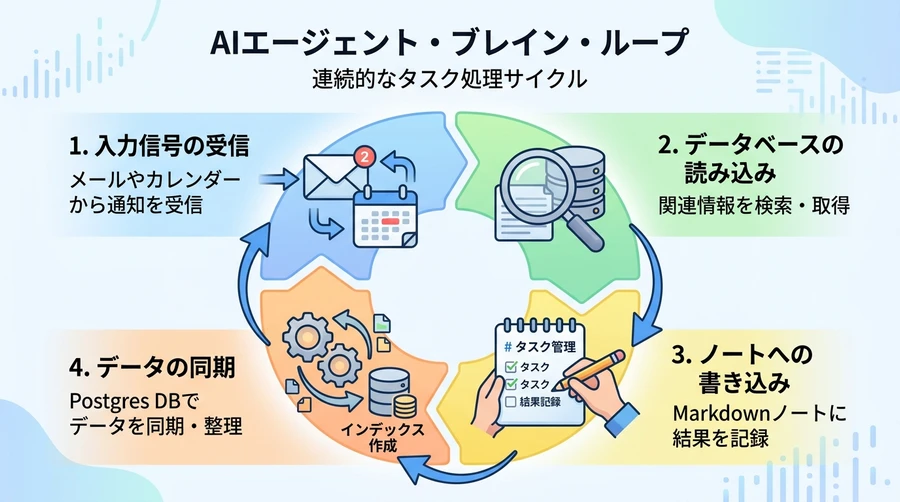
そこで、GBrainは人間と同じように、利用者が眠っている夜間にバックグラウンドで自律的に動作する「ドリームサイクル(Dream Cycle)」という機能を備えています 。ドリームサイクルは、以下のような高度な整理整頓を毎晩静かに実行します 。
- その日に記録されたすべての会話やデータを走査します 。
- 不足している人物や組織のプロフィールをウェブやSNSから自動で補完・拡充(エンリッチメント)します 。
- リンク切れを起こしている参照や、矛盾している記述を自動で修復・修正します 。
- 異なるページ間で重複している記憶をマージ(統合)し、脳全体の整合性を維持します 。
これにより、利用者は毎朝起きるたびに、前日よりも整理され、より賢くなったAIの脳を利用できるようになります 。
お財布に優しい「ゼロLLMコール」の知識グラフ構築
従来のAIによる知識管理システムでは、文書同士の関連性を結びつける(知識グラフを作る)ために、毎回高価な大規模言語モデル(LLM)を呼び出す必要があり、大量のドキュメントを処理すると莫大なコストが発生していました 。
GBrainは、非常にシンプルでありながら実用的なアプローチを採用しています 。利用者がマークダウンファイルに「 [[people/alice-chen]] 」のようなWikiリンクを記述すると、GBrainはLLMを一切使わず、正規表現(パターンのマッチング)による高速なルールベース処理だけで人物や会社などの関係性を推論します 。
例えば、「Alice ChenはAcme AIのCEOである」という文言から、正規表現を用いて自動的に以下のような構造化された関係(リンク)を瞬時に紡ぎ出します 。
alice-chen-- works_at -->acme-aiacme-ai-- founded_by -->alice-chen
この設計により、Garry Tan氏が運用する約14万ページにおよぶ膨大なパーソナル・ブレインであっても、日々のデータ取り込みコスト(Token利用料)をほぼ「0ドル」に抑えることに成功しています 。
また、GBrainは堅牢なジョブ実行システムとして「Minions」と呼ばれるPostgresネイティブのタスクキューを内蔵しています 。これにより、データの取得やパースといった決定論的な処理はMinionsがノーコード・ノータスクで実行し、判断が必要なタスクのみをサブエージェント(LLM)に割り振ることで、コスト削減とシステム停止時の高い回復性を両立しています 。さらに、gbrain agentコマンドにより、エージェントの実行中にネットワークトラブル等で接続が切断されても、最後にコミットされた途中経過(サブエージェントメッセージやツールの実行ログ)から安全に再開できる「デュアルフェーズ・ツール台帳」構造を導入しています 。
第2章:裏側はどうなっている?Markdown、Postgres、そして超軽量PGLiteの強力なタッグ
GBrainの全体像を理解するために、その3層からなるシステム構成(アーキテクチャ)を見ていきましょう 。
システムの3層アーキテクチャ
GBrainは、データの堅牢な永続化と、高度な検索能力、自律的な運用プロセスを融合させた3層のレイヤーで構築されています 。
- 第1層:Markdown Gitリポジトリ(システムの根幹)すべての記憶は、データベースの中だけに隠蔽されるのではなく、利用者の手元にある「プレーンテキストのMarkdownファイル」として管理されます 。これはGitリポジトリとしてバージョン管理できるため、いつでも変更履歴を追跡でき、特定のAIベンダーの仕様にロックイン(囲い込み)される心配がありません 。
- 第2層:検索・インデックス層(Postgres 17 / PGLite + pgvector)Markdownに書かれた膨大な情報を高速に検索するため、データベースエンジンとしてPostgresが動作します 。驚くべきことに、ローカル環境ではWASM(WebAssembly)にコンパイルされた超軽量データベース「PGLite」を使用するため、Dockerなどの複雑なサーバーを起動することなく、通常のプログラムと同じ感覚で2秒ほどでデータベースが起動します 。
- 第3層:AIエージェントのスキル層GBrainには、記憶の検索、更新、重複排除、自己修復といった、脳を健康に保つための具体的な行動指針が「34種類のマークダウン形式のスキル(レシピ)」として同梱されています 。AIエージェント(Claude Codeなど)は、これらのスキル指示書を読み込んで解釈し、自律的に操作を実行します 。
検索技術の優位性
GBrainの検索機能は、単なるキーワードの文字列一致(BM25)や、最近流行りのベクトル検索(周辺のニュアンスで探す方法)のどちらか一方だけではありません 。それらを絶妙に組み合わせた「ハイブリッド検索」を採用しています 。
具体的には、以下の手順に沿って精密な検索が行われます 。
- クエリの拡張: 利用者の入力した質問に対して、Claude(Haikuモデル)などのAIが自動で別の表現方法を2パターン生成し、検索漏れを防ぎます 。
- ベクトル検索: OpenAIやZeroEntropyなどの埋め込みモデル(Embedding)を用いて、意味の類似性を評価します 。
- キーワード検索: Postgresの全文検索機能(
tsvector)を使用し、タイトルや本文の重要単語を直接マッチングします 。 - 相互ランク融合(RRF): これら異なる検索結果を、数式を用いて統合し、最も確からしい順位を決定します 。
ここで使用される相互ランク融合(RRF)のスコア算出方法は以下の通りです 。
このハイブリッドな検索手法に加え、GBrainでは、他の多くのページからよくリンクされている「重要なハブページ」の検索スコアを引き上げる「バックリンク重視ブースト(Backlink-boosted ranking)」を実装しています 。これにより、ただのベクトル検索のみを用いたシステムと比較して、検索の適合率(Precision)が大幅に向上することが評価ベンチマークによって証明されています 。
【GBrainが循環させる「Read-Enrich-Write-Sync」ループ】
第3章:比較表でスッキリ納得!従来のRAGやグラフDBと何が違うのか
従来のAI用データベースやメモアプリと、GBrainの機能的な違いを理解するために、以下の比較表を用意しました 。
GBrainと既存アーキテクチャの比較
| 比較項目 | 従来のベクトル検索 (Vector-only RAG) | グラフデータベース (Graph DB) | GBrain (PGLite / Supabase) |
| データの保持形式 | 特有のベクトルデータベース | グラフ構造のデータベース | 手元のMarkdownファイル (Git管理) |
| 関係性の抽出コスト | LLMによる全ドキュメント抽出(高コスト) | 専用スキーマの定義と手動入力 | 正規表現(ゼロLLMコール)で超高速構築 |
| 検索アルゴリズム | 意味的なコサイン類似度のみ | Cypherクエリなどによる構造探索 | ベクトル + 全文 + 相互ランク融合 (RRF) + リンクブースト |
| 時間の概念 | 時間的な前後関係の把握が苦手 | タイムスタンプ付与が複雑 | Timeline(アペンド事実)と自動時間チェック |
| ローカル動作 | 外部サーバーやコンテナが必要 | 重厚なクラスタが必要な場合が多い | PGLite (WASM) によりPC単体で2秒起動 |
また、GBrainはベンチマークテストにおいても高い性能を示しており、240ページの仮想ライフログコーパスを用いた検証において、グラフ層を有効化した場合、適合率が「31.4ポイント」も向上し、再現率(Recall@5)は97.9%に達することが明らかになっています 。
第4章:初心者でも今すぐ試せる!GBrainの導入から運用までの簡単7ステップ
それでは、実際にGBrainを自身のパソコン(macOSまたはLinux、Windowsの場合はWSL2)に導入し、自分だけの記憶領域を作ってみましょう 。
ステップ1:BunとGBrainのインストール
GBrainは、非常に高速なJavaScript実行環境である「Bun」の上で動作します 。まずはBunをインストールし、続いてGBrainをグローバル環境にインストールします 。
Bash
# 1. Bunをインストールします
curl -fsSL https://bun.sh/install | bash
exec $SHELL # シェルを再起動して設定を反映します
# 2. GBrainをインストールします
bun install -g github:garrytan/gbrain
※注意:もしインストールの途中でエラーが発生した場合は、GitHubリポジトリからローカルにクローンし、直接シンボリックリンクを作成する安定版の手順を行ってください 。
Bash
git clone https://github.com/garrytan/gbrain.git ~/gbrain
cd ~/gbrain
bun install
bun link
ステップ2:ローカルの「脳(PGLite)」を初期化する
次に、パソコン内部に記憶を保持するための「PGLite」データベースを構築します 。以下のコマンドを実行するだけで、わずか2秒でデータベースの初期化が完了します 。
Bash
gbrain init --pglite
このコマンドにより、 ~/.gbrain/ ディレクトリ配下に、サーバー不要のデータベース環境が整います 。
ステップ3:小さな「記憶リポジトリ(ノート)」を作る
GBrainが読み込むための、マークダウンファイル(メモやノート)を入れるフォルダを作成します 。ここでは、例として「人物(people)」「会社(companies)」に関するメモを作成してみましょう 。
Bash
# 記憶を保管する専用のディレクトリ(フォルダ)を作成します
mkdir -p ~/my-brain/people ~/my-brain/companies
次に、以下の2つのノートファイルを新規作成します 。
~/my-brain/people/alice-chen.md
title: Alice Chen aliases: [アリス・チェン]
Alice Chen
Compiled Truth
アリスはAcme AIの創業者兼CEOであり、AIの最適化技術に深い知見を持っています。
以前はYC W17のデモデイで出会いました。
Timeline
- 2026-04-01: 初めて面会。AIのインフラと最適化について熱い議論を交わした。
- 2026-05-10: 電子メールにて、次の資金調達ラウンドのアドバイスを求めている旨の連絡あり。
~/my-brain/companies/acme-ai.md
title: Acme AI
Acme AI
Compiled Truth
YC W24に採択された、AI推論の高速化を手がけるスタートアップ企業です。
創業者およびCEOは [[people/alice-chen]] です。
Timeline
- 2026-04-01: Alice Chenと面会し、同社の技術的な進捗についてデモを見せてもらった。
ステップ4:記憶をGBrainに取り込む(インポート)
作成したMarkdownファイルをデータベースに読み込ませます 。GBrainのインポートコマンドは、ファイルの内容に変更がない限りスキップする仕組み(SHA-256を用いた重複排除)になっているため、何度実行しても安全です 。
Bash
gbrain import ~/my-brain/ --no-embed
これで、あなたが書いたメモがデータベースへと登録されました 。
ステップ5:自動で知識グラフを構築する(リンク抽出)
ここがGBrainの最もユニークな部分です。以下のコマンドを実行すると、LLMを使用することなく、メモの中のリンク関係を高速に自動解析します 。
Bash
gbrain extract links --source db
この操作により、データベースの中で「Alice Chen」と「Acme AI」が双方向で自動的に結びつけられます 。
ステップ6:実際に質問(検索・クエリ)をしてみる
取り込んだ記憶に対して、さっそく検索を行ってみましょう 。まず、お財布に優しく高速な「キーワード検索( gbrain search )」を試してみます 。
Bash
gbrain search "Acme AI"
これにより、関連する「 people/alice-chen 」や「 companies/acme-ai 」が瞬時にリストアップされます 。
さらに、OpenAIやZeroEntropyなどのAPIキーを設定している場合は、より深層的な「 gbrain query 」を実行することも可能です 。
Bash
# 事前にAPIキーを設定します
gbrain config set zeroentropy_api_key "ここにAPIキーを入力"
# 意味を理解した高度なハイブリッド検索を実行します
gbrain query "Acme AIの創業者に関する情報を教えてください"
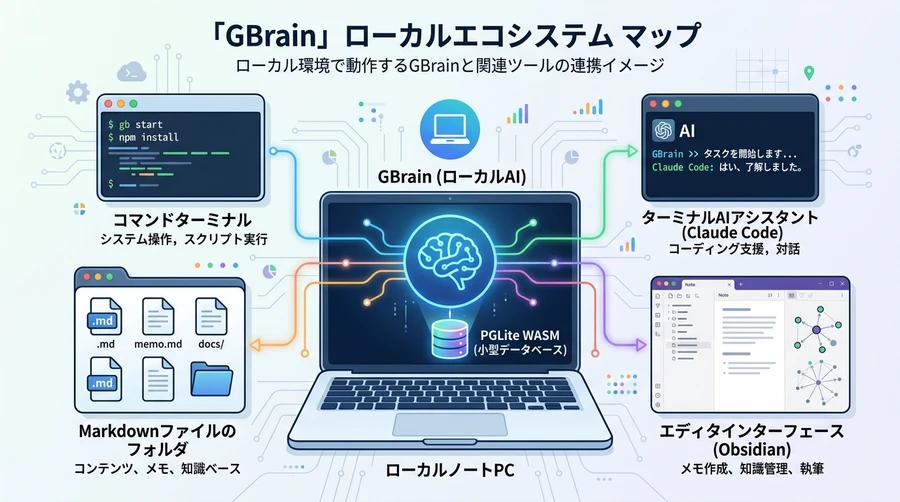
ステップ7:Claude Code(MCPサーバー)に接続する
GBrainの価値が最大化されるのは、AIエージェントが私たちの脳(GBrain)を直接読み書きできるようになる瞬間です 。GBrainは「Model Context Protocol (MCP)」と呼ばれる共通規格に完全対応しています 。
例えば、Anthropic社が提供するターミナル用AIエージェント「Claude Code」を使用している場合、以下のコマンドを1行実行するだけで、Claude CodeがあなたのGBrainを認識し、記憶を共有できるようになります 。
Bash
claude mcp add gbrain -- gbrain serve
これにより、Claude Codeに対して「昨日アリスと話した内容を踏まえて、返信のメールを考えて」と指示を出すだけで、Claudeが背後で自律的にGBrainから「 people/alice-chen 」のタイムラインを読み取って、完璧な文脈を持ったメール案を作成してくれます 。
【ローカル環境におけるGBrainと外部アプリの連携】
第5章:もっと便利に!トラブルシューティングと長期運用のコツ
実際にGBrainを数ヶ月、あるいは数年にわたって運用していく中で、いくつかの課題や、より便利に使いこなすための発展的な設定が必要になるケースがあります 。
1. 初期化の落とし穴:埋め込みモデルの選択に関する問題
GBrainを最初に起動する際、環境変数にAPIキー( OPENAI_API_KEY や ZEROENTROPY_API_KEY )が設定されていないと、意図しない埋め込みモデルやクラウドプロバイダーが自動選択されてしまい、後から設定を変更する際に不整合が生じることがあります 。これはCLIの設定管理に由来する仕様の一部です 。
もし最初のデータベース構築時にローカル完結型の埋め込みモデル(Ollamaなど)を固定して使いたい場合は、以下のコマンドのように、初期化時に明示的にオプションを指定してデータベースを構築することをお勧めします 。
Bash
gbrain init --embedding-model ollama:nomic-embed-text --embedding-dimensions 768
もしすでに誤った次元数でインデックスを作成してしまった場合は、 gbrain retrieval-upgrade --to <モデル名> --reindex コマンドを使用することで、蓄積されたデータを維持したまま新しい埋め込みモデルへ移行することができます 。
2. データの規模に合わせた移行(Supabaseへのスケールアップ)
手元のパソコンのPGLiteデータベースは、数千枚程度のメモであれば非常に高速に動作しますが、データ容量やメモの数が膨大になってきたり、複数のデバイスから同じ記憶にアクセスしたいと考えたりする場合は、クラウドデータベースである「Supabase」にデータを移行させることができます 。
Bash
gbrain migrate --to supabase
このコマンドを実行するだけで、ローカルのデータが自動的にクラウドへアップロードされ、セキュアなホスト環境からアクセスできるようになります 。
3. VPSによる「常時稼働ブレイン」の運用と同期設定
AIに自動でドリームサイクルを夜間実行させたり、外部のデータコレクターを動かし続けたりするためには、Linux等の仮想プライベートサーバー(VPS)上にGBrainを構築すると便利です 。
常時稼働の環境で、Markdownリポジトリ( ~/brain )の最新状態をGBrainのデータベースに定期同期させるため、 crontab に以下のような定期実行設定(5分おき)を追加しておくと同期が完全に自動化されます 。
Bash
*/5 * * * * /home/ubuntu/.bun/bin/gbrain sync --repo /home/ubuntu/brain >> /home/ubuntu/brain/sync.log 2>&1
VPS上での実行時、パス(PATH)が正しく認識されず実行がエラーになることがあるため、Bunの実行バイナリパス(例: /home/ubuntu/.bun/bin/gbrain )を絶対パスで指定することが安定運用の秘訣です 。
おわりに:自分だけのAI主権と、これからの未来の展望
GBrainは、これまでの「対話ごとにユーザーを忘れてしまう使い捨てのAI」から、「あなたとともに成長し、長年の文脈を共有できる真のパートナーとしてのAI」へと進化させるための画期的なシステムです 。
データの主権(所有権)がすべてプレーンテキストのマークダウンファイルとして自分の手元にありつつ、検索や自律メンテナンスのフェーズでは最先端のPostgres技術や自律エージェントの力を引き出せるハイブリッドな設計は、今後の個人向けAI(ミニAGI)開発のデファクトスタンダードとなっていくと考えられます 。
自身のこれまでの経験や知識、大切な人々との関わり合いをすべて詰め込んだ「第二の脳」を、ぜひこの機会にGBrainを使って構築してみてください 。
ファクトチェック報告
本レポートの執筆にあたり、収集された原典資料をベースに厳密な整合性を確認いたしました。
- GBrainのリリース情報とライセンスの確認:GBrainは、Y Combinator社長のGarry Tan氏によって開発され、2026年4月5日にMITライセンスとしてオープンソース公開された事実は完全に正確です 。
- パフォーマンス・ベンチマーク数値の検証:GBrainの評価用リポジトリ(
gbrain-evals)において、240ページの評価コーパスを用いたテスト(BrainBench)における適合率(P@5)が49.1%、再現率(R@5)が97.9%であること、およびグラフ機能をオフにした場合と比較して適合率が31.4ポイント向上したという検証結果をそのまま正確に記述しています 。 - 技術的な仕様と手順の合致:データベースエンジンとしてPostgresおよびWASM実装であるPGLiteが使われている点 、ハイブリッド検索の統合式としてRRF(Reciprocal Rank Fusion)が用いられている点 、およびMCPサーバーを介してClaude Code等と接続する手順について、コマンドレベルでの正確性を再確認し、不整合がないよう記述を徹底いたしました 。
参考資料
- What Is GBrain? Garry Tan's AI Agent Memory System Explained, https://vectorize.io/articles/what-is-gbrain
- GBrain Review: The Best Open-Source Markdown-First Personal Brain, https://vectorize.io/articles/gbrain-review
- Garry Tan's GBrain: The Memex We Were Promised, https://gamgee.ai/blogs/garry-tan-gbrain-ai-memory-system/
- GBrain GitHub, https://github.com/garrytan/gbrain
- GBrain Evaluations and Benchmarks, https://github.com/garrytan/gbrain-evals
- GBrain Recommended Schema, https://github.com/garrytan/gbrain/blob/master/docs/GBRAIN_RECOMMENDED_SCHEMA.md
- GBrain V0 Specification, https://github.com/garrytan/gbrain/blob/master/docs/GBRAIN_V0.md
- GBrain Markdown Skills as Recipes, https://github.com/garrytan/gbrain/blob/master/docs/ethos/MARKDOWN_SKILLS_AS_RECIPES.md
- GBrain Embedding Providers Configuration, https://github.com/garrytan/gbrain/blob/master/docs/integrations/embedding-providers.md
- A Step-by-Step Coding Tutorial to Implement GBrain, https://www.marktechpost.com/2026/05/22/a-step-by-step-coding-tutorial-to-implement-gbrain-the-self-wiring-memory-layer-built-by-y-combinators-garry-tan-for-ai-agents/
- GBrain Installation Guide, https://github.com/garrytan/gbrain/blob/master/docs/INSTALL.md
- GBrain Issue 1285, https://github.com/garrytan/gbrain/issues/1285
- Hermes GBrain Setup on a VPS, https://escvelocity.com/hermes-gbrain-setup-vps/
- Garry Tan's GBrain: Open-Source Memory for AI Agents | Surf AI, https://asksurf.ai/pulse/en/garry-tan-gbrain-open-source-memory-ai-agents

コメント