

- 最新ローカルAI「Irodori-TTS v3」のPodcast
- 第1章:ローカルAI音声合成の幕開けと「Irodori-TTS v3」の魅力
- 第2章:Irodori-TTS v3を支える先進技術(Flow MatchingとDACVAE)
- 第3章:v2から劇的な進化を遂げた「v3」の革新ポイント
- 第4章:ビジネスにも使える!MITライセンスの恩恵と絶対に守るべきマナー
- 第5章:【Windows対応】初心者でも失敗しない簡単インストール・ガイド
- 第6章:実際に声を作ってみよう!Web UI of Irodori-TTS
- 第7章:言葉だけで声をデザインする「VoiceDesign」の魔法
- 第8章:まとめ:あなたの創作活動に新しい彩りを
- 参考資料
最新ローカルAI「Irodori-TTS v3」のPodcast
下記のPodcastは、Geminiで作成しました。
第1章:ローカルAI音声合成の幕開けと「Irodori-TTS v3」の魅力
近年、ディープラーニング技術の爆発的な進化に伴い、人工知能による音声合成(TTS: Text-to-Speech)は新しい次元へと突入しています。かつての音声合成といえば、どこか機械的で平坦な、いわゆる「ロボットボイス」が主流でした。しかし、最新のAIモデルは、人間の息遣いや感情の起伏、イントネーションの細やかな変化までを見事に再現し、生身の人間と聞き分けがつかないレベルの品質に達しています 。
こうした技術革新の最先端に位置しながら、日本の開発者であるAratako氏によって生み出されたのが、日本語に特化したオープンソースのローカル音声合成AI「Irodori-TTS」です 。ローカルAIとは、クラウド上の高額なサーバーを介さずに、ユーザー自身のパソコンに搭載された演算装置のみで動作するAIシステムを指します 。
ローカル環境で実行できることには、極めて実用的なメリットが数多く存在します。インターネットへの接続料金や、生成文字数に応じた従量課金制度を気にする必要がなく、完全に無料で無制限に音声を生成し続けることができます 。また、外部サーバーにテキストデータや参照音声をアップロードしないため、クリエイターのアイデアや機密情報が外部に漏洩するリスクが根本的に排除されます。さらに、ネットワークの遅延が発生しないため、高性能なグラフィックボード(GPU)を搭載したPCであれば、驚くほどのハイスピードで音声を創り出すことが可能です 。
2026年5月、この素晴らしいプロダクトに待望の最新バージョンである「Irodori-TTS v3」がリリースされました 。前バージョンから引き継がれた「短い音声から一瞬で声を真似るクローニング機能」に加え、テキスト中に絵文字を挿入するだけで感情や音響効果を自在に操れる独自の直感的な機能はそのままに、処理効率と音声品質が飛躍的に向上しています 。本稿では、この「Irodori-TTS v3」が持つ驚異的な実力と、それを今すぐあなたの手元で動かすための具体的な方法を、初心者の方にも分かりやすく丁寧に解説します。

第2章:Irodori-TTS v3を支える先進技術(Flow MatchingとDACVAE)
「なぜIrodori-TTS v3は、これほど自然でなめらかな声質を、パソコンのローカル環境で素早く生成できるのか」という疑問を持つ方も多いでしょう。この高いパフォーマンスの裏側には、最先端の音声生成テクノロジーが惜しみなく投入されています。専門知識がなくてもイメージしやすいよう、その中核を成す技術を紐解いていきます。
Flow Matching(フローマッチング)とRF-DiT
従来の音声生成AIの多くは、「拡散モデル(Diffusion Model)」と呼ばれる技術を用いていました。これは、完全にランダムなノイズデータから少しずつ雑音を取り除き、時間をかけて目的の音声を復元していく手法です。しかし、この拡散プロセスは計算の経路が曲がりくねっているため、クリアな音声を復元するまでに多くのステップ数(時間)を必要とするという弱点がありました。
これに対し、Irodori-TTS v3が採用している「Flow Matching(フローマッチング)」、特に「RF-DiT(Rectified Flow Diffusion Transformer)」は、ノイズから音声データまでの復元経路を「直線的(Rectified)」に最適化する最新の設計思想に基づいています 。無駄な寄り道をせず、最短距離でノイズを音声へと変換するため、わずか30ステップ程度の非常に少ない計算回数でも、ノイズのないクリアでハイクオリティな音声を出力できるのです 。この設計は、海外で先行する「Echo-TTS」の優れたアーキテクチャや学習設計を基盤として、さらに日本語に最適化する形で発展させたものです 。
DACVAE(音響符号化器)による直接出力
従来の音声合成システムは、「テキストから音の波形を表す画像(メルスペクトログラム)を予測し、それをボコーダーと呼ばれる変換器に通して音にする」という、二段階のプロセスを踏んでいました。この方式は、ボコーダーによる変換時に金属的なザラザラとしたノイズが発生しやすく、声の不自然さや機械っぽさが残る一因となっていました。
Irodori-TTSは、音声圧縮技術である「DACVAE(Descript Audio Codec Variational Autoencoder)」が生成する「連続的な潜在空間(Latents)」を直接の予測ターゲットに指定しています 。音の情報を極めて滑らかに圧縮したまま処理を行うため、変換時の音質劣化を抑え、人間の耳に極めて心地よく馴染む、生のリアルな肉声をそのまま再現することに成功しています 。
大規模言語モデル「llm-jp-3-150m」による日本語理解
どれほど声の質が美しくても、日本語の漢字の読みを間違えたり、アクセントの位置がおかしかったりすると、聞き手はすぐに「AIの声だ」と気づいてしまいます。Irodori-TTSは、テキストの意味や発音を解析する部分(テキストエンコーダー)に、日本の研究コミュニティによって構築された大規模言語モデル「llm-jp-3-150m」のトークナイザーと埋め込みベクトルの初期値を取り入れています 。
これにより、日本語独特の漢字の読み分け、専門用語や固有名詞、さらには日常会話における細やかなニュアンスを最初から正しく解釈し、極めて自然なイントネーションで発話する強固な頭脳を最初から備えているのです 。
第3章:v2から劇的な進化を遂げた「v3」の革新ポイント
2026年5月にリリースされた「Irodori-TTS v3」は、前作の「v2」から何が変わり、どこが進化しているのでしょうか。ユーザーの日々の創作効率を劇的に向上させる、3つの主要なアップデート項目について分かりやすく解説します 。
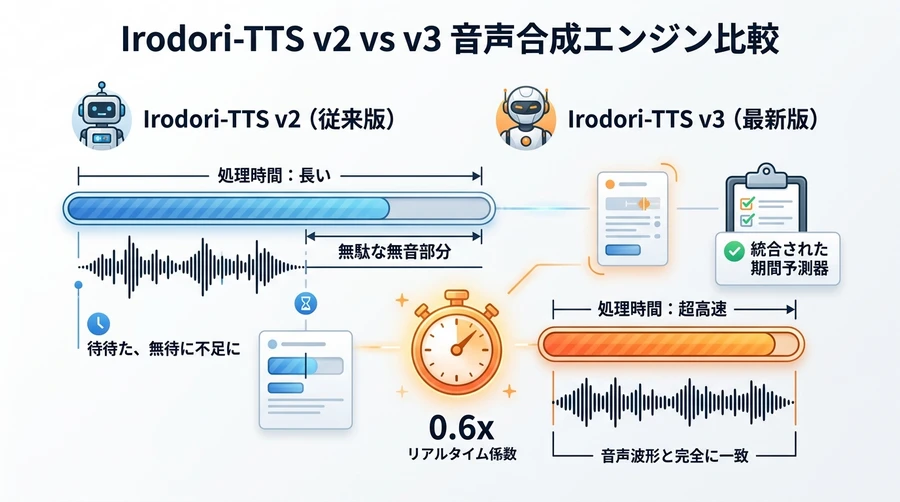
1. 可変長学習と「期間予測器(Duration Predictor)」の統合
これこそがv3を語る上で最も重要な進化です 。
従来のv1やv2モデルでは、あらかじめ定められた固定の長さ(例えば30秒)を基準として音声を学習・推論する設計になっていました 。そのため、短い一言のセリフ(例:「こんにちは」)を生成する際にも、内部的には30秒分の枠を確保して計算を行う必要があり、生成された音声の後半に長い無駄な余白(無音)が残ってしまっていました 。ユーザーは手動で「秒数」を指定したり、後から無音部分をカットする手間を強いられていたのです 。
v3では、発話データの長さに応じて効率的に学習を行う「可変長学習(Variable-length Training)」へと完全に移行しました 。さらに、モデル内部に「期間予測器(Duration Predictor)」と呼ばれるコンポーネントが標準で組み込まれました 。これにより、入力されたテキストや参照する声の特徴から、AIが「このセリフを発音するには何秒の音声長が適切か」を自動的に算出して音声の生成範囲を決定するようになりました 。
手動での秒数設定(--seconds)を省略して「0」または空欄にするだけで、AIが自動的に発話の長さを推定し、余分な無音を作らずにピタッと終わる音声を吐き出してくれます 。
この革新的な機能により、無駄な余白を計算するためのパワーが一切不要となり、処理効率を示す「リアルタイム係数(RTF)」が大幅に向上しました 。
RTFは、以下の式で計算されます。
ここで、$T_{\text{infer}}$ はAIが音声を生成するのに要した計算時間(秒)、$T_{\text{audio}}$ は生成された音声の実際の長さ(秒)です。
実機(GeForce RTX 5070 TiなどのNVIDIA製グラフィックボードを搭載したPC)を用いて5秒間のセリフを出力させた場合、生成にかかる時間($T_{\text{infer}}$)はわずか約3秒で完了します 。この時のRTFは以下のように算出されます。
RTFが1.0未満($RTF < 1.0$)ということは、人間が実際にそのセリフを喋り終えるよりも短い時間で、AIが音声ファイルを生成し終えていることを示しています。なお、グラフィックボードを持たないPCでCPUのみを使って実行した場合、同じ5秒のセリフ生成に約90秒の計算時間がかかります($RTF = 18.0$) 。CPUでも動作自体は可能ですが、RTXシリーズなどのGPUを搭載したPCを導入することで、何十倍もの快適性を得られることが分かります 。
2. Qwen3-OmniベースのAIアノテーションによる表現力の深化
Irodori-TTSの代名詞である「絵文字による感情表現」の幅と正確性が、v3でさらに磨かれました 。
モデルの学習データを拡充するにあたり、高性能な最新マルチモーダルAI「Qwen3-Omni-30B-A3B-Instruct」をベースにした専用モデルが活用されました 。この高度なAIを用いて、学習用の日本語音声データ(コーパス)に対して、人間の話し方のトーンや感情、効果音に最も適した絵文字を自動的かつ精緻にラベル付け(アノテーション)して再学習が行われたのです 。
この結果、絵文字を挿入した際の発音のブレが少なくなり、「より泣いているような悲しい声」「よりいたずらっぽくからかう声」など、指示に対する表現の一貫性と再現度が格段に向上しました 。
3. 音声の安定性とロバストネスの劇的向上
前バージョンでは、入力するテキストが長すぎたり、参照させる音声(Reference Audio)の音質があまり良くなかったりすると、生成された音声の途中で声質が急変してしまったり、イントネーションが崩れて意味不明な音(アーティファクト)が発生する「ハルシネーション(幻覚)」現象が稀に発生していました 。
v3では、より大規模でクリーンな日本語音声データセットで追加の学習を施したことにより、極めてノイズの多い参照音声や、複雑な漢字混じりの長文テキストに対しても、最初から最後まで安定した声質とトーンをキープできるようになりました 。
第4章:ビジネスにも使える!MITライセンスの恩恵と絶対に守るべきマナー
ローカルAIモデルをビジネスや作品制作に使用するにあたり、最も注意を払う必要があるのが「ライセンス(利用規約)」と「倫理的ルール」です。Irodori-TTS v3は、この両面においてクリエイターを強力に後押しする素晴らしい設計がなされています。
夢の「MITライセンス」の適用
海外製を含め、現存する多くのオープンソース音声合成モデル(例えばChatTTSなど)は、利用許諾が「学術研究(Non-commercial)のみ」に限られていることが多く、ビジネスでの活用や、広告収入を得る活動への利用は制限されています 。
しかし、Irodori-TTS v3は、実行プログラムのコードだけでなく、公開されているモデルウェイト(モデルのデータ本体)についても、非常に自由度の高い「MITライセンス」でリリースされています 。これにより、以下のような活動を、完全無料かつロイヤリティ(使用料)の支払いなしで行うことができます。
- 同人ゲームやインディーゲーム、有料の商用ゲームにおけるキャラクターのボイス(CV)として組み込む
- YouTube、TikTok、ニコニコ動画などの投稿プラットフォームで、ナレーション音声として使用し、動画の収益化(広告収入)を得る
- 企業のプロモーションビデオ、オーディオブック、自社製品の音声ガイダンスとして実用化する
※ただし、後述する「VoiceDesignモデル」については、現時点(2026年5月)ではv3의 ウェイトが公開されていないため、引き続きv2(Irodori-TTS-500M-v2-VoiceDesign)を使用する形となります 。モデルを切り替えて利用する際には、各チェックポイントに設定されている個別のモデルカードのライセンス規約を事前によくご確認ください 。
クリエイターとしてのモラル:倫理的制限(Ethical Restrictions)
どれほど利用が自由なMITライセンスであっても、AIによる音声クローニング(声質の複製)という非常に強力な技術を扱う以上、越えてはならない一線が存在します。開発者のAratako氏は、以下の行為を固く禁止しています 。
| 倫理的制限の項目 | 具体的な違反例と絶対に行ってはならない行為 |
| 本本人同意なきなりすましの禁止 | 実在する声優、俳優、有名人、知人などの声を無断でクローンし、あたかもその本人が喋っているかのようなコンテンツを制作・公開してはいけません。必ず対象の人物から明示的な許可(同意)を得てください。 |
| 誤情報の拡散やディープフェイクの禁止 | 社会的な混乱を招くような偽のニュース音声を生成したり、他者の名誉を毀損したり騙したりするための「ディープフェイク」を作成する目的で使用することは絶対に許されません。 |
| 法的・道徳的免責の理解 | AIの使用によって生じたすべてのトラブルや損害、第三者との権利侵害に関する法的紛争について、開発者は一切の責任を負いません。すべてユーザーの自己責任において使用する必要があります。 |
安全性を技術で担保する「SilentCipher」
悪意あるディープフェイクや音声の不正利用から社会を守るため、Irodori-TTS v3で生成されるすべての音声には、電子透かし(Watermark)技術である「SilentCipher(サイレント・サイファー)」が自動的に埋め込まれます 。
これは人間の耳にはまったく聞こえない、音質に一切の影響を与えない不可視の信号です 。しかし、検出用のプログラムを用いることで「この音声はIrodori-TTSによって生成されたAI音声である」という証明データをいつでも正確に検出することができます 。この技術的な防御策のお経で、万が一のなりすましトラブルの際にも、「本物の肉声ではなくAIで作られた声である」ことを客観的に証明でき、健全なAI利用環境が守られています 。
第5章:【Windows対応】初心者でも失敗しない簡単インストール・ガイド
それでは、実際にあなたのWindowsパソコンにIrodori-TTS v3をインストールし、動作させるまでの手順をステップ・バイ・ステップで分かりやすく解説します 。
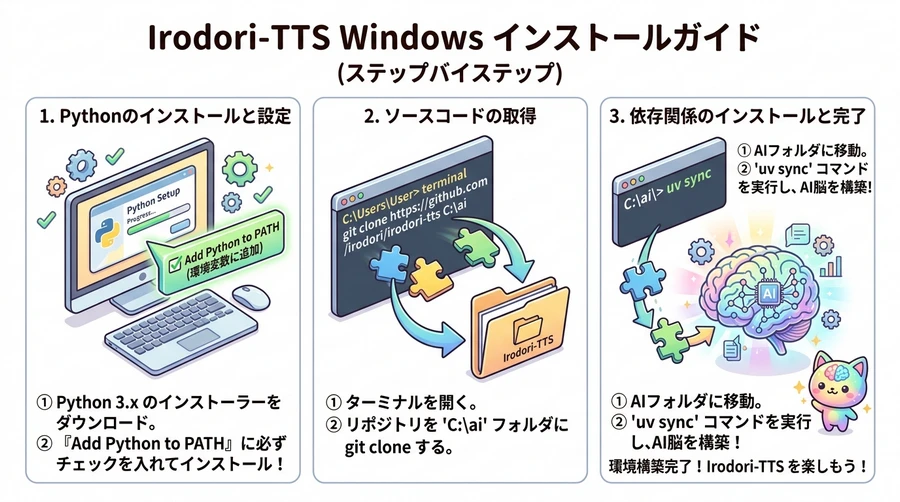
ステップ1:必要な前提ソフトの準備
AIを動かすためには、「Python(プログラミング言語)」、「Git(コードを管理するツール)」、「uv(超高速なパッケージ管理ツール)」の3つをインストールします 。Windows 10または11であれば、以下の手順で一気に準備が整います。
- PythonのインストールPythonの公式サイトから最新のインストーラーをダウンロードします 。インストールを開始する際、画面の一番下にある「Add Python to PATH(Pythonの実行パスを通す)」というチェックボックスに必ずチェックを入れ、それから「Install Now」をクリックしてください。これを忘れると、後のコマンドが動きません。
- GitとuvのインストールWindowsに標準で備わっている「ターミナル」アプリから、たった1行のコマンドでインストールします。
- スタートボタンを右クリックし、「ターミナル」または「PowerShell」を開きます 。
- 画面が起動したら、以下のコマンドをコピーして貼り付け、Enterキーを押します 。Bash
winget install --id Git.Git -e - 処理が進み、「インストールが完了しました」と表示されたら、続けて以下のコマンドを入力し、Enterキーを押します 。Bash
winget install --id=astral-sh.uv -e - 再び完了メッセージが表示されたら、一度ターミナルのウィンドウを完全に閉じます。これでステップ1は完了です。
ステップ2:プログラムのダウンロードと環境構築
- パソコンのCドライブの直下に「
ai」という半角英字のフォルダーを新規作成します(フォルダーの場所はC:\aiになります) 。 - 作成した
aiフォルダーを開き、フォルダー内の何もない場所を右クリックして、「ターミナルで開く」をクリックします 。 - ターミナルが起動したら、以下のコマンドを入力してEnterキーを押し、Irodori-TTSのプログラムをパソコンに複製します 。Bash
git clone https://github.com/Aratako/Irodori-TTS.git - ダウンロード(クローン)が完了したら、以下のコマンドで、新しく作られたプログラムのフォルダーへと移動します 。Bash
cd Irodori-TTS - 最後に、以下のコマンドを実行します 。Bash
uv syncこのコマンドを打つだけで、あなたのパソコン上にIrodori-TTS v3を実行するための隔離されたPython仮想環境が自動的に構築され、必要なすべての依存ライブラリが信じられないほどの高速スピードで安全にインストールされます 。画面の末尾にC:\ai\Irodori-TTSと再度表示されれば、すべての準備は完璧に完了です。
第6章:実際に声を作ってみよう!Web UI of Irodori-TTS
いよいよ、直感的で使いやすいWebブラウザ上の操作画面(Gradio Web UI)を起動して、実際に声を出してみましょう 。
1. アプリケーションの起動
- 作成したフォルダー
C:\ai\Irodori-TTSを開き、何もない場所を右クリックして「ターミナルで開く」を選択します。 - ターミナルに以下のコマンドを入力してEnterキーを押します 。Bash
uv run python gradio_app.py --server-name 0.0.0.0 --server-port 7860 - 少し待つと、ターミナルに「
Running on local URL: http://0.0.0.0:7860」という表示が出ます 。 - お使いのWebブラウザ(ChromeやEdgeなど)を開き、アドレスバーに「 http://localhost:7860 」と入力してアクセスします 。
- 画面が開いたら、まず上部にある「Load Model」という青いボタンをクリックします 。初回のみ、自動的にインターネットから「Irodori-TTS-500M-v3」のモデル(約2GB)の自動ダウンロードが始まりますので数分間待ちます 。ダウンロードが終了し、画面に「
loaded model into memory」と表示されれば、いつでも声を生成できる状態になります 。
2. 基本操作:スタンダード音声合成(Standard TTS)
画面の「Text」と書かれた入力エリアに、喋らせたい文章を入力します(例:「こんにちは!私の名前はアイです。ローカルAIの音声合成へようこそ!」)。
その後、下にある大きな「Generate」ボタンをクリックします 。
わずか数秒で計算が終わり、「Generate」ボタンの真下に音声の再生用バーが出現します 。再生ボタンをクリックすればスピーカーからクリアな声が流れ、右側の三点リーダーからPCへWAVファイルをダウンロードすることもできます 。
3. 声マネ機能:ゼロショット・ボイスクローニング(Voice Cloning)
この機能を使えば、好きな声をAIに真似させることができます 。
- 喋らせたいセリフを「Text」に入力します 。
- 「Reference Audio Upload」と書かれた枠内に、真似させたいターゲットの声が録音された音声ファイル(5秒から10秒程度のWAVやMP3ファイル)を直接ドラッグ&ドロップします 。
- 「Generate」をクリックします 。
- これだけで、AIがアップロードされた音声の「声質、声の高さ(ピッチ)、発音の癖」を解析し、その声質になりきって「Text」に入力した新しいセリフを喋り出します 。
4. 応用操作:絵文字による感情の自由コントロール
Irodori-TTSの真骨頂である、絵文字を用いた感情・表現制御のテクニックを試してみましょう 。
使い方は驚くほどシンプルで、「Text」に入力する文字の中に、特定の絵文字を混ぜるだけです 。例えば以下のように入力します。
入力例:「うぅ… 😭そんなに酷いこと、言わないで… 😭」
入力例:「ごめんね、ちょっと風邪引いちゃってて🤧… 咳が止まらないんだ🥺」
AIが絵文字(😭、🤧、🥺など)の意味を解釈し、実際に声を泣かせたり、鼻をすすらせたり、自信なさげに声を震わせたりして、感情豊かな演技へと劇的に声を変化させます 。
以下は、学習データにより効果が検証されている代表的な絵文字コントロールの一覧です。これらの絵文字を組み合わせて、お好みのセリフを演出してみてください。
| 絵文字 | 演出される感情・音響効果 | 具体的な声質の変化と演技のイメージ |
| 👂 | 囁き(ウィスパー) | 耳元で囁かれているような、吐息混じりの超密着した声になります。 |
| ⏸️ | 沈黙(ポーズ) | 文の途中に自然な間を空け、タメを作ることで聞きやすさを向上させます。 |
| 🤭 | 含み笑い・クスクス | セリフの合間に、楽しそうにクスクスと笑う吐息が自然に混入します。 |
| 🥵 | 喘ぎ・うめき声 | 息が非常に荒くなり、苦しそうな表情や緊迫した声を再現します。 |
| 📢 | エコー・リバーブ | 広いホールやトンネル、スタジオで響いているような残響が加わります。 |
| 😏 | からかう・甘える | トーンが少し上がり、小悪魔的で魅力的な誘いかけるような声になります。 |
| 🥺 | 震え・自信なさげ | 困り果てた表情、今にも泣き出しそうに懇願するニュアンスを含みます。 |
| 🌬️ | 息切れ・強い呼吸 | 運動直後のような、はぁはぁという呼吸音が混ざります。 |
| 👅 | 舐める・咀嚼・水音 | ASMRコンテンツ等に重宝する、ウェットな口内音や水音が加わります。 |
| 📞 | 電話越し・スピーカー | トランシーバーや電話回線を通したような、中音域が強調された音になります。 |
| 🐢 | ゆっくり話す | 話速全体を遅くし、落ち着いた大人の朗読や案内音声に最適化します。 |
| ⏩ | 早口・捲し立てる | 怒涛のスピードで言葉を詰め込み、焦りや興奮状態を表現します。 |
| 😒 | 舌打ち・不機嫌 | 発話の直前に「チッ」というリアルな舌打ちが交じり、不満を表現します。 |
| 😆 | 喜び・明るい笑顔 | 声のトーンが明るく弾み、満面の笑みで喋っているような雰囲気になります。 |
第7章:言葉だけで声をデザインする「VoiceDesign」の魔法
「手元に真似させたい声のサンプルファイルがないけれど、自分のゲームに合う理想のキャラクターボイスを作りたい」という場合に最適なのが「VoiceDesign」機能です 。
この機能を使えば、「声の高さ、性別、年齢、話し方の特徴、部屋の響き」などをテキスト(言葉)で説明するだけで、AIがその説明通りの架空の人物の声をゼロから仕立ててくれます 。
VoiceDesignの起動方法
- 通常のWeb UIが起動している場合は、ターミナルで「Ctrl + C」を押して一度プログラムを終了させます 。
- ターミナルに以下のコマンドを入力して実行します 。Bash
uv run python gradio_app_voicedesign.py --server-name 0.0.0.0 --server-port 7861 - 起動が完了したら、ブラウザで「 http://localhost:7861 」にアクセスします 。
VoiceDesignの使い方
- 「Text」エリアに、喋らせたいセリフを入力します 。
- 「Caption」と書かれたエリアに、作りたい声を説明する文章を入力します 。
- 女性キャラクターの例:「落ち着いた、近い距離感の女性話者。やわらかく自然に読み上げてください」
- 男性キャラクターの例:「少しハスキーで、渋く落ち着いたトーンの40代後半の男性の声」
- ファンタジー風の例:「幼い女の子の声で、広いお寺の本堂でエコーを響かせながら優しく話す」
- 「Generate」ボタンをクリックします 。これだけで、AIが「Caption」に入力されたテキストの意味を解釈し、その特徴を備えた魅力的な音声を出力してくれます 。
※前述の通り、v3のコードベースは後方互換性を持っているため、このVoiceDesignモードを実行する際は、自動的に前作のモデル(Irodori-TTS-500M-v2-VoiceDesign)のチェックポイントが裏で読み込まれ、機能を提供しています 。

第8章:まとめ:あなたの創作活動に新しい彩りを
日本語特化型のローカル音声合成モデル「Irodori-TTS v3」は、最先端の「Flow Matching」技術と「DACVAE」を融合させ、さらに自動化された「期間予測器(Duration Predictor)」を備えることで、個人クリエイターやビジネスユーザーにとって究極の音声制作ツールとなりました 。
これまではプロの声優への依頼や、高額なクラウドAPIの使用が必要だった「キャラクターへの命の吹き込み」が、今や一般家庭用のパソコン1台で、かつ「絵文字を混ぜるだけ」という信じられないほど直感的なインターフェースで実現できます 。
MITライセンスという強力なライセンスの恩恵を受けながら、倫理的なマナーを守りつつ、あなたの作品(ゲーム、動画、オーディオブックなど)に、美しく、感情豊かで、唯一無二の「彩り(いろどり)」を添えてみてはいかがでしょうか 。
参考資料
- 好きな声で好きなセリフを喋らせられるローカルAI「Irodori-TTS」の使い方、日本語特化でローカル動作するので無制限に生成し放題、https://gigazine.net/news/20260504-irodori-tts-text-to-speech-ai/
- Aratako氏のGitHubリポジトリ「Aratako/Irodori-TTS」、https://github.com/Aratako/Irodori-TTS
- Hugging Face上のモデルカード「Aratako/Irodori-TTS-500M-v3」、https://huggingface.co/Aratako/Irodori-TTS-500M-v3
- Hugging Face上のディスカッション「Aratako/Irodori-TTS-500M-v2 Discussions」、https://huggingface.co/Aratako/Irodori-TTS-500M-v2/discussions/1
- Hugging Face上のデモスペース「Aratako/Irodori-TTS-500M-v2-Demo」、https://huggingface.co/spaces/Aratako/Irodori-TTS-500M-v2-Demo
- GitHubリポジトリ「iron-mukakin/Emoji-TTS」、https://github.com/iron-mukakin/Emoji-TTS
- GitHubリポジトリ「jupo-ai/ComfyUI_IrodoriTTS_Wrapper」、https://github.com/jupo-ai/ComfyUI_IrodoriTTS_Wrapper
- Hugging Face上の「EMOJI_ANNOTATIONS.md」、https://huggingface.co/Aratako/Irodori-TTS-500M/blob/main/EMOJI_ANNOTATIONS.md
- Redditのスレッド「TTS research for possible commercial and personal...」、https://www.reddit.com/r/LocalLLaMA/comments/1fi3uq8/tts_research_for_possible_commercial_and_personal/?tl=ja


コメント