

ーーーーーーーーーーーーーーーーーーーーー2026年3月12日執筆ーーーーーーーーーーーーーーーーー
PythonのNumPy入門、これから始めようとする初心者向けに分かりやすく解説|Python入門(13)のPodcast
下記のPodcastは、Geminiで作成しました。
はじめに
Pythonでデータサイエンスや機械学習、科学技術計算を学ぼうとする際、避けて通れないのが「NumPy(ナンパイ)」というライブラリです。2024年にリリースされたNumPy 2.0は、実に18年ぶりとなる大規模なアップデートであり、それ以降の2025年、2026年(最新の2.4.2および2.5系)にかけて、その性能と使いやすさは飛躍的に向上しました [1]。本記事では、プログラミングを始めたばかりの初心者の方に向けて、最新のNumPyがどのようなもので、なぜ重要なのか、そしてどのように使いこなせば良いのかを優しく丁寧に解説します。
NumPyとは? なぜ学ぶ必要があるのか
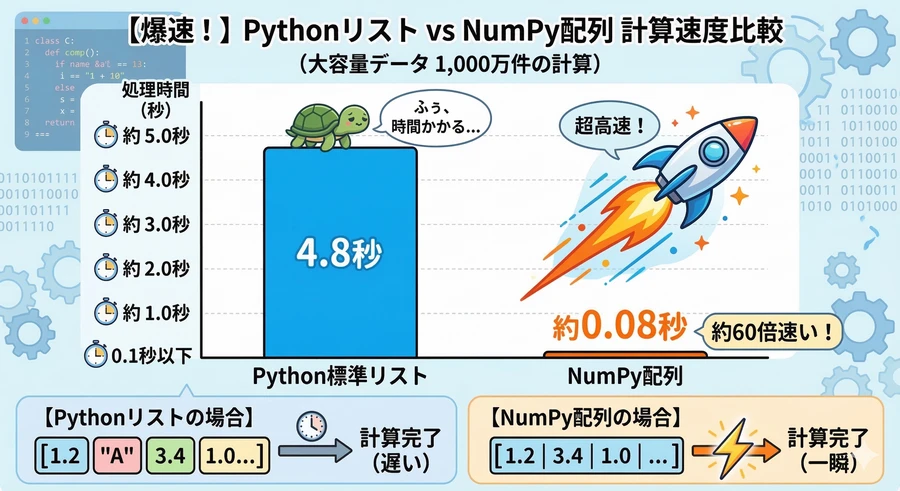
NumPyは、一言で言えば「大量の数値を高速に処理するための道具箱」です。Python標準の機能でも計算はできますが、数万、数百万という膨大なデータを扱う場合、NumPyを使わないと計算が終わるまでに非常に長い時間がかかってしまいます。
Pythonの「リスト」とNumPyの「配列」の違い
初心者の方が最初につまずきやすいのが、Python標準の「リスト」とNumPyの「ndarray(配列)」の違いです。
Pythonのリスト: 整数、文字列、実数など、異なる種類のデータを混ぜて入れることができる「万能な袋」です。しかし、中身を一つずつ確認しながら処理するため、計算速度はそれほど速くありません。
NumPyの配列(ndarray): 全ての要素が「同じデータ型(例えばすべて整数など)」である必要があります。その代わり、データがメモリ上に整然と並んでいるため、コンピュータが一度に大量の計算を処理することが可能です [1]。
最新のベンチマークでは、単純な合計計算においてNumPyはPythonのリストよりも100倍近く高速に動作することが示されています [1]。
2026年版:環境構築と導入方法
現代のPython開発環境は、かつてに比べて非常にスマートになりました。2026年現在、最も推奨される方法は、Rust製の超高速パッケージ管理ツール「uv」を使用することです [1]。
インストール手順
ターミナル(またはコマンドプロンプト)で以下のコマンドを入力するだけで、最新のNumPy(2026年3月現在は2.4.2以降)がインストールされます。
bash
uv add numpy
これにより、Python 3.13や3.14といった最新の実行環境に最適化されたNumPyが導入されます [1]。プログラム内で使用する際は、伝統的な「np」という別名をつけてインポートします [1]。
python
import numpy as np
NumPy配列の基本構造と属性
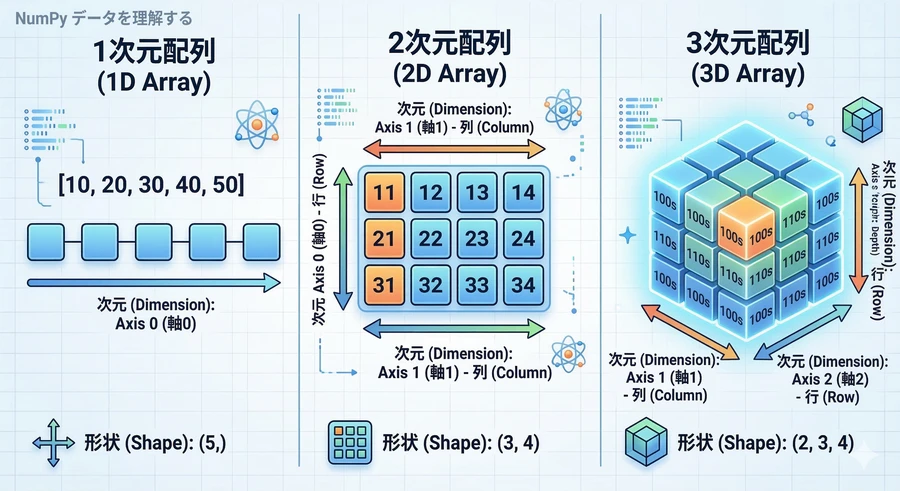
NumPyを使い始める前に、配列が持つ「属性(プロパティ)」を知っておくことが大切です。これらは、データの「形」や「種類」を教えてくれる重要な手がかりになります [1]。
ndim(次元数): 配列が何次元かを示します。1次元なら「線」、2次元なら「表」のようなイメージです。
shape(形状): 配列の大きさを示します。例えば「3行4列の表」であれば (3, 4) と表示されます [1]。
size(要素数): 配列に含まれるデータの合計個数です。
dtype(データ型): 配列の中身が「整数(int)」なのか「小数(float)」なのかを示します [1]。
【2.0以降の重要な変更点】
以前のNumPyでは、OSによってデフォルトの整数型(32ビットか64ビットか)が異なり、これが計算ミスを招く原因になっていました。NumPy 2.0以降、Windowsでもデフォルトが「int64」に統一され、より安心して使えるようになりました [1]。
配列を作ってみよう
NumPyには、配列を作るための便利な関数がたくさん用意されています。
数値を指定して作成
python
# リストから作成 a = np.array([1, 15, 11]) # 0で埋められた配列(3行4列) b = np.zeros((3, 4)) # 連続した数値(0から9まで) c = np.arange(10)
乱数の生成(現代的な書き方)
最新のNumPyでは、従来の np.random.rand() ではなく、Generator というオブジェクトを使うのが正解です [1]。
python
rng = np.random.default_rng() random_array = rng.random((2, 2)) # 0から1の間の乱数で2x2の行列を作る
インデックスとスライス:データの取り出し方
配列から特定のデータを取り出す方法は、Pythonのリストと似ていますが、多次元になるとNumPy独自の便利さが際立ちます。
基本: a[0] で最初の要素にアクセスします。NumPyも「0」から数え始めます [1]。
多次元: a[1, 15] のように、カンマで区切って「1行目の2列目」を直接指定できます。
スライス: a[1:4] と書くと、1番目から3番目までをまとめて切り出せます [1]。
ここで初心者が注意すべきは、スライスで切り出したデータは「元の配列の分身(ビュー)」であるという点です。切り出した方の値を書き換えると、元の配列の値も変わってしまいます。元データを残したい場合は、.copy() メソッドを使いましょう [1]。
ベクトル化演算とブロードキャスト:NumPyの真髄
NumPyがなぜ速いのか。その最大の理由は「for文(ループ)」を書かなくて済むからです。これを「ベクトル化演算」と呼びます [1]。
ループなしの計算
python
a = np.array([1, 15, 11]) # 全ての要素を2倍にする print(a * 2) # 結果: [2, 30, 22]
Pythonのリストであれば for 文を使って一つずつ計算する必要がありますが、NumPyなら一行で、しかも内部の高速なC言語処理によって一瞬で終わります [1]。
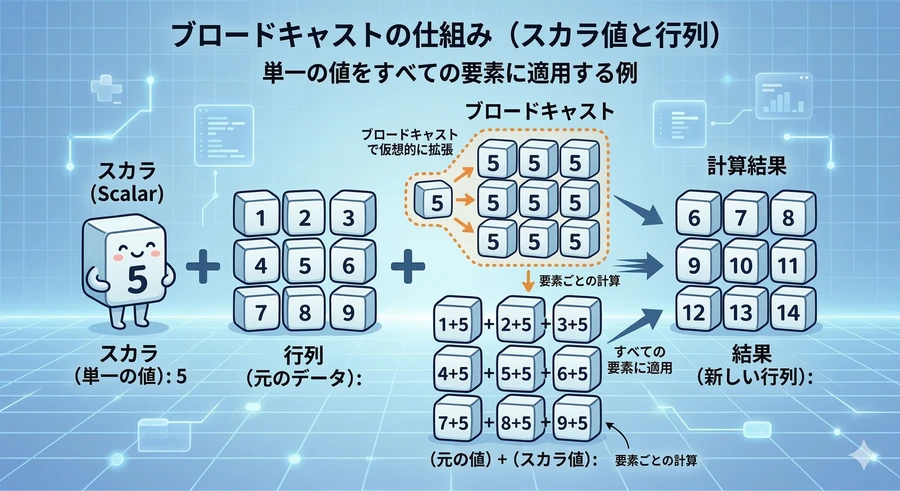
ブロードキャスト
形が違う配列同士でも、NumPyが気を利かせて「形を自動で揃えて計算してくれる」機能がブロードキャストです [1]。例えば、3x3の行列に1つの数値を足すと、すべての要素にその数値が足されます。この「引き伸ばし」のルールを理解すると、複雑なデータ処理が劇的に楽になります [1]。
文系・初心者でも安心:統計計算機能
NumPyは、データの平均や合計を出すのが得意です。
np.sum(a) : 合計
np.mean(a) : 平均
np.std(a) : 標準偏差(データのばらつき)
np.max(a) / np.min(a) : 最大値 / 最小値
これらの関数は、axis(軸) という引数を指定することで、「行ごとの合計」や「列ごとの平均」を自由自在に計算できます [1]。
2026年の注目機能:StringDTypeとハイパフォーマンス
最新のNumPy 2.x系で導入された画期的な機能の一つが、新しい文字列型「StringDType」です [1]。これまでのNumPyは「決まった長さの文字列」を扱うのは得意でしたが、長さがバラバラな文字列を扱うのは苦手でした。新しいStringDTypeにより、可変長のテキストデータもメモリを節約しながら高速に処理できるようになりました [1]。これは、自然言語処理(AIによる文章解析)などにおいて非常に強力な武器となります。
また、最新のCPUが持つ「SIMD(一度に複数の計算を行う仕組み)」を最大限に活用するように設計されており、古いバージョンのNumPyに比べて、ソート(並び替え)などの処理が数倍から数十倍高速化されています [1]。
初心者がハマりやすいポイントと解決策
学習をスムーズに進めるために、以下の3点に気をつけてください。
次元の不一致: 計算しようとした時に ValueError: operands could not be broadcast together と出たら、配列の形(shape)が合っていません。.shape を確認しましょう [1]。
コピーと参照: スライスしたデータは元のデータとつながっています。「切り取った方だけ変えたい」ときは必ず .copy() をしてください [1]。
古い関数の使用: NumPy 2.0で、いくつかの古い関数が整理されました。例えば np.trapz は現在非推奨となり、np.trapezoid を使うよう推奨されています [1]。
まとめ
NumPyは、2026年現在、これまで以上に強力で、かつ洗練されたライブラリへと進化しました。
圧倒的な速度: Pythonリストより100倍速いこともある [1]。
シンプルな記述: 複雑な計算を一行で書ける [1]。
AI時代の基盤: PandasやPyTorchといった有名なツールはすべてNumPyの上で動いている [1]。
一見難しそうに見えるかもしれませんが、まずは np.array() で自分のデータを作ってみることから始めてください。一歩ずつ触れていくうちに、データの海を自在に操る楽しさに気づくはずです。
参考資料
1. NumPy 2.0.0 Release Notes, https://numpy.org/devdocs/release/2.0.0-notes.html
2. NumPy 2.0 Migration Guide, https://numpy.org/devdocs/numpy_2_0_migration_guide.html
3. NumPy 2.0 Release: Key Changes and Migration, https://www.datacamp.com/de/tutorial/numpy-2-release
4. NumPy 2.0.0の主要な変更点, https://qiita.com/DevPairWM/items/78b78fb5231de2980871
5. NumPy vs Python Lists: Which Is Faster and Why, https://medium.com/@snehauniyal2003/numpy-vs-python-lists-which-is-faster-and-why-ee98ecfee87f
6. NumPy quickstart, https://numpy.org/devdocs/user/quickstart.html
7. NumPy for absolute beginners, https://numpy.org/doc/stable/user/absolute_beginners.html
8. NumPy 2.4.0 Release Notes, https://numpy.org/devdocs/release/2.4.0-notes.html
9. NumPy 2.4.2 Release Notes, https://numpy.org/devdocs/release/2.4.2-notes.html
10. NumPy 2.0の主要な変更点を初心者向けに解説, https://blog.pyq.jp/entry/python_news_240814
11. Performance Improvements in NumPy 2.0, https://www.droidbiz.in/numpy/numpy-vs-python-lists-performance-comparison
12. NumPy 2.5.0 Development Roadmap, https://numpy.org/devdocs/release/2.5.0-notes.html
13. Python Project Management Tools 2026: uv and beyond, https://medium.com/@inprogrammer/python-project-management-tools-2026-44231df94d7d
14. NumPy Random Generator Guide, https://www.codecademy.com/article/numpy-matrix-multiplication-a-beginners-guide
15. Vectorization and Optimization in NumPy, https://blog.paperspace.com/numpy-optimization-vectorization-and-broadcasting/
16. Working with Variable-width Strings in NumPy 2.x, https://numpy.org/devdocs/user/basics.strings.html
17. StringDType Performance and Use Cases, https://stackoverflow.com/questions/79528948/how-to-efficiently-use-numpys-stringdtype-for-string-operations-e-g-joining
18. Array Indexing and Slicing Basics, https://jakevdp.github.io/PythonDataScienceHandbook/02.02-the-basics-of-numpy-arrays.html
19. Memory Layout and Contiguous Arrays, https://medium.com/@sushma.mullamuri420/why-numpy-is-faster-and-more-efficient-than-python-lists-4f3183da83f8
20. Statistical Functions in NumPy, https://www.geeksforgeeks.org/numpy-statistical-functions/
21. Deep Dive: Why NumPy is the go-to for Data Science, https://dev.to/isha1221/why-choose-numpy-over-python-lists-a-deep-dive-for-developers-2m83
22. NumPy vs Python Lists: Performance Benchmarks 2026, https://medium.com/@abhishekbadthunia3232/numpy-vs-python-lists-3668cba921a3
23. Python 3.14 and Free-Threading Support in NumPy, https://blog.stackademic.com/unlocking-parallel-power-a-beginners-guide-to-free-threading-in-python-3-14-a74a427e67f2
24. Advanced Performance in NumPy 2.x, https://numpy.org/doc/2.4/release.html
25. NumPy Array API Standards, https://numpy.org/devdocs/user/basics.interoperability.html
26. NumPy Evolution: Major Leap of 2.0, http://oreateai.com/blog/numpys-evolution-from-incremental-updates-to-the-major-leap-of-20/0598c1c6500a8af3ca38f6de9e79d3b5
27. Computation on Arrays: Broadcasting Rules, https://jakevdp.github.io/PythonDataScienceHandbook/02.05-computation-on-arrays-broadcasting.html
28. Why Choose NumPy: Speed and Practicality, https://dev.to/isha1221/why-choose-numpy-over-python-lists-a-deep-dive-for-developers-2m83
29. Modern Python Data Analysis Seminar 2026, https://ai-kenkyujo.com/programming/language/python/python-ai-nyumon/
ーーーーーーーーーーーーーーーーーーーーー2022年9月26日執筆ーーーーーーーーーーーーーーーーー
はじめに
前回のPython入門(12)では、Pythonのタプルとコレクションについて学びました。
これにより、Pythonの基礎の基礎についてほぼ全てを解説してきました。
以降については、Pythonをより活用するためのライブラリの利用について紹介していきます。
Python入門の第十三弾として、PythonのNumPy入門について紹介します。
この記事を読むと次の疑問について知ることができます。
それでは、PythonのNumPy入門をこれから始めようとする初心者向けに分かりやすく解説していきます。
NumPyとは?
NumPy(Numerical Python)は、Pythonで数値計算を効率的にしかも高速に実行するためのライブラリになります。
Pythonは今では機械学習、画像処理、AI(Artificial Intelligence、人工知能)などを学ぶプログラミング言語としてよく知られていますが、これらは大量のデータ処理(数値計算)を高速に扱う必要があるためにNumPyが利用されてます。
NumPyは、英語読みで「ナムパイ」「ナンパイ」などと呼ばれています。
NumPyを使う準備
通常、PythonでNumPyを利用するためにはPythonにNumPyの拡張モジュールをインストールする必要がありますが、Google Colaboratory(以後、Google Colabと記述)を利用する場合は、既にNumPyはインストールされています。
Google Colab内に既にインストールされているライブラリにはどのようなものがあるかを知るためには、次のように打ち込んでください。
Google Colab内に既にインストールされているライブラリが縦に表示され、その中に「numpy==1.21.6」があることが分かり、NumPyのバージョン1.21.6がインストールされていることが分かります。
NumPyを利用するには、「使うための宣言、import文」をすればよいことになります。
import numpy as np
上述の文の意味は、NumPyライブラリを読み込み、使えるようにすると共に『「numpy」⇒「np」として名前変更して利用しますよ』という宣言になります。
NumPyの基本的な使い方
Pythonで配列などのデータを扱う際に前提のリストを利用できますが、大量のデータを扱う際には処理時間がかかりすぎるために、NumPyの「ndarray」というデータ型を使うことができます。
この「ndarray」は、配列などの計算を高速に実行でき、しかも、数学的な便利な関数を多く用意されているためにそれら関数を利用することができます。
配列の属性
NumPyのデータ型であるndarrayの配列には属性があり、次の3つの属性は特に重要です。
配列の作成
NumPyで配列を作成するためには、「ndarray」の配列(1次元であればベクトル、2次元であれば行列、3次元以上であればテンソル)を作成するための関数「array」を利用します。
Pythonのリストを使った配列の作成
「ndarray」の配列は、関数「array」を利用してPythonのリストをまる括弧「(」「)」で囲って作成します。
hairetu1 = np.array(Pytonのリスト)実例として、1次元、2次元(2×3)、3次元(2×3×3)を作成し、それぞれの形(shape)、次元数(ndim)、サイズ(size)を出力してみましょう。
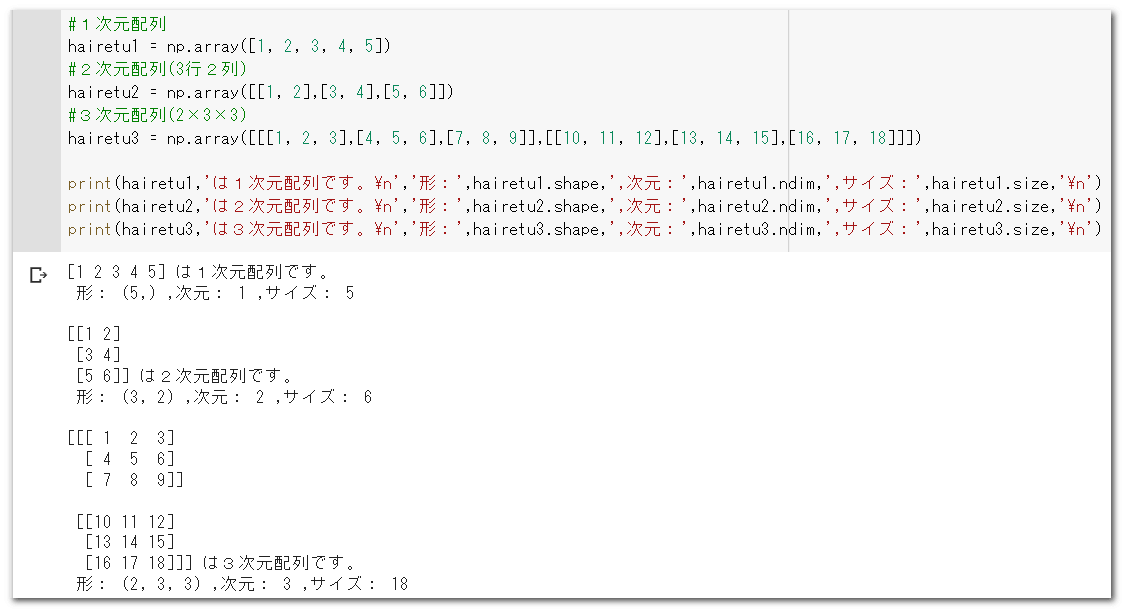
その他の配列の作成
NmpPyには、Pythonのリストを利用せずに「ndarray」の配列を作成する方法があります。






配列内の要素の参照
「ndarray」の配列内の要素の参照は、Pythonのリスト、タプルなどと同様にインデックス(ゼロベースインデックス )を利用して参照できます。
ここでは、5行6列の2次元配列(x1)を考えてみましょう。
| インデックス | 0 -6 | 1 -5 | 2 -4 | 3 -3 | 4 -2 | 5 -1 |
| 0 -5 | 1 | 2 | 3 | 4 | 5 | 6 |
| 1 -4 | 10 | 20 | 30 | 40 | 50 | 60 |
| 2 -3 | 100 | 200 | 300 | 400 | 500 | 600 |
| 3 -2 | *60 | -50 | -40 | -30 | -20 | -10 |
| 4 -1 | -600 | -500 | -400 | -300 | -200 | -100 |
配列の一つの要素の参照
上述の5行6列の2次元配列の中から、一つの要素(インデックス表示:1行5列目の要素又はー4行-1列、要素60)を参照してみます。

配列の行の参照
上述の配列「x1」の2行目又はー4列目(インデックス表示)を参照してみましょう。

配列の列の参照
上述の配列「x1」の2列目又はー3行目(インデックス表示)を参照してみましょう。

配列の特定の領域の参照
行が0行~2行(-5行~-3行)、列が2列~4列(-4列~-2列)の領域を参照してみましょう。

この場合、最後の行や列に指定した行や列は含まれないことに注意しましょう。
つまり、 行が0行~2行(-5行~-3行)、列が2列~4列(-4列~-2列)の領域を参照したいのであれば、0行~3行(-5行~-2行)、列が2列~5列(-4列~-1列)と指定する必要があります。
配列の計算
NumPyのndarrayにより作成した配列の計算について紹介します。
計算には、Pythonで用いた「+」、「ー」、「*」、「/」、「**」、「%」などの記号を用いて足し算、引き算、掛け算、割り算、べき乗計算、割り算の余計算が行えます。
配列と定数の計算
ここでは、3行3列の配列と定数「5」を計算してみます。
計算結果は。配列のそれぞれの要素に定数を計算することになります。

配列と配列の計算
配列同士の計算の場合は、それぞれの配列の同じ要素同士の計算が行われます。
ここでは、3行3列の2つの配列(x, y)同士の四則計算をしてみましょう。

行列積(内積)
内積に関する数学的な意味については、ここでは解説しませんので、他の記事を参照してください。
ここでは、計算方法を紹介します。
例えば、2行2列の行列A、Bがあった時に、PythonのNumPyでは「np.dot()メソッド」を利用して計算ができます。
行列 A = [[a1, a2], [a3,a4]]、B=[[b1, b2],[b3, b4]]があった際に、この行列AとBの内積C は、図で説明すると次のようになります。
| 行列A | 内積 | 行列B | 行列C | ||||||||||
| [ | a1 | a2 | ] | ✖ | [ | b1 | b2 | ] | = | [ | a1*b1 + a2*b3 | a1*b2 + a2*b4 | ] |
| a3 | a4 | b3 | b4 | a3*b1 + a4*b3 | a3*b2 + a4*b4 | ||||||||
それでは、実際の行列A[[1,2],[3,4]]、行列B[[5,6],[7,8]]の内積Cを求めてみましょう。

行列Cの要素1=a1*b1 + a2*b3=1*5 + 2*7 = 5 + 14 = 19
行列Cの要素2=a1*b2 + a2*b4=1*6 + 2*8 = 6 + 16 = 22
行列Cの要素3=a3*b1 + a4*b3=3*5 + 4*7 = 15 + 28 = 43
行列Cの要素4=a3*b2 + a4*b4=3*6 + 4*8 = 18 + 32 = 50
内積する際の注意点
同じ行列の形状の内積をすることは問題ないのですが、異なった形状の行列の内積を計算する際には内積する行列Aの列数と内積する行列Bの行数が一致する必要があります。
例えば、2行2列の行列Aと内積できる行列Bは2行の1次元から多次元配列である必要があります。
基本的な統計量の計算
NumPyのndarray型のデータの合計、平均、最大値、最小値、標準偏差、分散などは関数が用意されており、簡単に求めることができます。
これら関数を表の形にまとめました。
| 項目 | 関数 | 項目 | 関数 |
| 合計 | np.sum(配列名) | 平均 | np.mean(配列名) |
| 最大値 | np.max(配列名) | 最小値 | np.min(配列名) |
| 標準偏差 | np.std(配列名) | 分散 | np.var(配列名) |
ここでは、8行10列のランダム関数による配(std)を作成し、その統計的な計算をしてみましょう。

おわりに
如何だったでしょうか?
NumPyとは?、NumPyを使う準備、NumPyの基本的な使い方、配列の属性、配列の作成、Pythonのリストを使った配列の作成、その他の配列の作成、配列内の要素の参照、配列の一つの要素の参照、配列の行の参照、配列の列の参照、配列の特定の領域の参照、配列の計算、配列と定数の計算、配列と配列の計算、行列積(内積)、基本的な統計量の計算などについて解説してきました。
この記事を読みながらPythonの数値計算ライブラリーのNumPyを学んでもらえればと思います。
次をお楽しみに?
以上です。

コメント