

ーーーーーーーーーーーーーーーーーーーーー2026年3月11日執筆ーーーーーーーーーーーーーーーーー
- Pythonのタプルとコレクション、これから始めようとする初心者向けに分かりやすく解説|Python入門(12)
- はじめに
- Pythonにおけるデータ構造の進化と最新環境
- タプルの基礎:イミュータブルなデータ管理
- collectionsモジュールによる高度なデータコンテナ
- パフォーマンスの最適化:PEP 709と内部メカニズム
- Python 3.13におけるエラーメッセージの進化とデバッグ
- 実践ガイド:適切なデータ構造を選択するためのフローチャート
- 結論:Pythonが目指す「人間に優しい」データ操作
- 参考資料
- はじめに
- Pythonのタブルとは?
- タプル、リスト、辞書の違い
- タプルオブジェクトの作成
- コレクション
- おわりに
Pythonのタプルとコレクション、これから始めようとする初心者向けに分かりやすく解説|Python入門(12)
下記のPodcastは、Geminiで作成しました。
はじめに
Pythonプログラミングの世界において、データをどのように保持し、効率的に処理するかという「データ構造」の選択は、ソフトウェアの品質と性能を左右する極めて重要な要素です。特に最新のPython 3.13では、これらのデータ構造を扱うための環境が劇的に進化しており、初学者がより直感的に、かつ深い理解を得られるような仕組みが整っています。本報告書では、Pythonの基本である「タプル」から、高度なデータ操作を可能にする「コレクション(collectionsモジュール)」まで、最新の言語仕様に基づいて網羅的に解説します。
Pythonにおけるデータ構造の進化と最新環境
Python 3.13のリリースに伴い、開発者が対話型プログラミングを通じてデータ構造を学ぶための「Developer Experience(開発体験)」は大きく向上しました。刷新された対話型インタプリタ(REPL)は、PyPyプロジェクトの技術をベースとした新しいシェルを採用しており、カラー表示やマルチライン編集、対話型ヘルプ機能(F1キー)などが標準で利用可能です [1]。これにより、タプルやリストの挙動を一行ずつ試行錯誤しながら確認する際の効率が飛躍的に高まっています。
また、エラーメッセージの改善も特筆すべき点です。初心者がデータ構造の操作でミスをした際、Python 3.13は単にエラーを報告するだけでなく、「Did you mean...?(〜のことですか?)」という形式で修正案を提示します。例えば、辞書のキー指定ミスや関数のキーワード引数の誤入力に対して、より文脈に即したアドバイスが得られるようになっています [1]。このような「人間に優しい」エラー表示は、学習者が挫折することなく、データ構造の本質的な理解に集中することを助けます。

タプルの基礎:イミュータブルなデータ管理
タプル(tuple)は、Pythonの組み込みデータ型の一つであり、複数の要素を順番に並べて保持するシーケンス型です。リスト(list)と非常によく似ていますが、最大の違いは、一度作成した後にその内容を変更することができない「イミュータブル(不変)」という性質にあります [1]。
タプルの定義と構文的特徴
タプルは通常、丸括弧 () を使用して定義されます。要素が複数の場合は、リストと同様にカンマ , で区切って記述します。しかし、Pythonにおいてタプルを定義する本質的な要素は括弧ではなく「カンマ」であるという点は、初学者が最初に見落としがちな重要なポイントです [1]。
| 特徴 | 内容 |
|---|---|
| 定義記号 | 丸括弧 () およびカンマ , |
| 変更可能性 | 不可(イミュータブル) |
| 要素の重複 | 許可される |
| 主な用途 | 変更したくない値のセット、関数の多値返却、辞書のキー |
「要素1つのタプル」という初心者の罠
タプルを扱う際、最も頻繁に発生するミスが「要素が1つだけのタプル」の作成です。単に (10) と記述した場合、Pythonはこれを単なる括弧で囲まれた整数として解釈し、データ型は int になります。これをタプルとして認識させるためには、必ず (10,) のように、末尾にカンマを付加しなければなりません [1]。この仕様は、丸括弧が数学的な計算の優先順位を制御するためにも使われることから、それと区別するために設けられた明確なルールです [1]。要素が2つ以上あればカンマが介在するため自動的にタプルと認識されますが、1つの場合のみ明示的なカンマが必要となります。この「カンマの有無」によってプログラムの挙動が大きく変わるため、デバッグ時には常に意識する必要があります [1]。
リストとタプルの使い分け:ノートとルーズリーフの比喩
タプルとリストの使い分けを理解するために、よく用いられるのが「ノート」と「ルーズリーフ」の比喩です。リストはルーズリーフのアドレス帳のようなもので、後からページを差し替えたり、破棄したり、新しく追加したりすることが容易です [1]。一方、タプルは製本されたノートのアドレス帳であり、一度書いた内容はそのまま保存されます。この不変性(イミュータブル)には、単なる制限以上のメリットが存在します。
第一に、データの整合性が保証されます。プログラム全体で共有される定数や、変更されては困る設定値をタプルに格納することで、意図しない上書きによるバグを未然に防ぐことができます [1]。
第二に、メモリ効率と実行速度です。一般的にタプルはリストよりも生成が速く、メモリ消費量も少ない傾向にあります [1]。
第三に、辞書の「キー」としての利用です。辞書のキーにはハッシュ可能な(内容が変わらない)オブジェクトしか指定できないため、リストは使えませんがタプルは使うことができます [1]。
collectionsモジュールによる高度なデータコンテナ
Pythonの標準ライブラリに含まれる collections モジュールは、組み込みの基本型(dict, list, tuple)を拡張し、特定の用途に最適化された「特殊なコンテナ型」を提供します [1]。これらを利用することで、複雑なデータ操作をより簡潔に、かつ効率的に記述することが可能になります。
namedtuple:名前でアクセス可能なタプル
namedtuple は、タプルの各要素に名前(フィールド名)を付けることができるファクトリ関数です。通常のタプルでは point のようにインデックスで要素を参照しますが、namedtuple を使えば point.x のように名前でアクセスできるようになります [1]。これはコードの可読性を劇的に向上させます。特にCSVの行データやデータベースのレコード、座標計算などを扱う際、どのインデックスが何を意味しているかを覚える必要がなくなります [1]。また、Python 3.13からは replace() プロトコルが強化され、特定のフィールドだけを変更した新しいインスタンスを作成する際の標準的な方法が提供されています [1]。
Counter:要素の出現頻度を自動集計
データの集計作業において最も多用されるのが Counter です。これは辞書のサブクラスであり、ハッシュ可能なオブジェクトの個数を数えるために設計されています [1]。リストや文字列などのイテラブルなオブジェクトを渡すだけで、要素をキー、出現回数を値とするオブジェクトを生成します。
| メソッド | 機能説明 |
|---|---|
| most_common(n) | 出現回数の多い順に上位 n 個の要素を取得する |
| subtract(iterable) | 指定した要素のカウントを減算する |
| total() | 全要素のカウントの合計値を計算する(Python 3.10以降) |
Counter は、テキスト解析における単語頻度の調査や、ログファイル内の特定のエラー発生回数の集計などに極めて有効です。また、存在しない要素にアクセスしてもエラーにならず 0 を返すという、辞書とは異なる便利な特性を持っています [1]。

defaultdict:初期化の手間を省く辞書
標準の辞書(dict)では、存在しないキーを参照しようとすると KeyError が発生します。これを回避するために、あらかじめ「初期値を生成する関数」を指定できるのが defaultdict です [1]。例えば、値をリストとして定義しておけば、新しいキーに対して即座に .append() メソッドを呼び出すことができます。通常の辞書で必要な「キーが存在するかどうかのチェック(if key in d:)」というステップを省略できるため、コードが非常にシンプルになります [1]。これはデータのグルーピングや、複雑なネスト構造を持つ辞書を作成する際に威力を発揮します。
deque:高速な両端操作を実現する双方向キュー
deque(デック)は、リストの先頭や末尾に対する要素の追加・削除を高速に行うためのデータ構造です [1]。Pythonのリストは動的配列として実装されているため、末尾への追加は高速ですが、先頭への追加・削除には要素のシフトが発生し、リストの長さに比例した時間($O(n)$)がかかります。これに対し、 deque は双方向連結リストのような性質を持ち、両端の操作を常に一定の時間($O(1)$)で行うことができます [1]。履歴管理(スタック)や、タスク待ち行列(キュー)の実装において、パフォーマンスのボトルネックを解消するための標準的な選択肢となります。
OrderedDictとChainMapの活用
Python 3.7以降、標準の辞書も挿入順序を保持するようになりましたが、OrderedDict は「順序」をより厳格に管理したい場合に有用です。例えば、要素を末尾に移動させる move_to_end() メソッドや、順序を含めた辞書同士の比較(==)において、標準の辞書とは異なる挙動を示します [1]。
ChainMap は、複数の辞書を仮想的に一つのビューとして結合する機能を提供します [1]。これは、デフォルト設定、環境変数、コマンドライン引数といった優先順位のある設定値を管理する際に非常に便利です。メモリ上に新しい辞書を作成することなく、既存の辞書群を階層的に検索できるため、効率的なスコープ管理が可能になります [1]。
パフォーマンスの最適化:PEP 709と内部メカニズム
Pythonの最新バージョンでは、コレクションを扱う際の内部処理にも大きな改善が加えられています。特に重要なのが、Python 3.12で導入された「内包表記のインライン化(PEP 709)」です。以前のPythonでは、リスト内包表記や辞書内包表記を実行する際、内部的に一時的な関数オブジェクトが作成されていました。しかし最新の仕様では、これらの処理が呼び出し側のバイトコードに直接インライン化されるようになりました。これにより、内包表記の実行速度が最大で2倍程度高速化されています [1]。
| バージョン | 内包表記の処理方式 | パフォーマンスへの影響 |
|---|---|---|
| 3.11以前 | 隠れた関数オブジェクトを作成・実行 | 関数呼び出しのオーバーヘッドが発生 |
| 3.12以降 | バイトコードに直接埋め込み(インライン化) | 最大2倍の高速化、メモリ消費の抑制 |
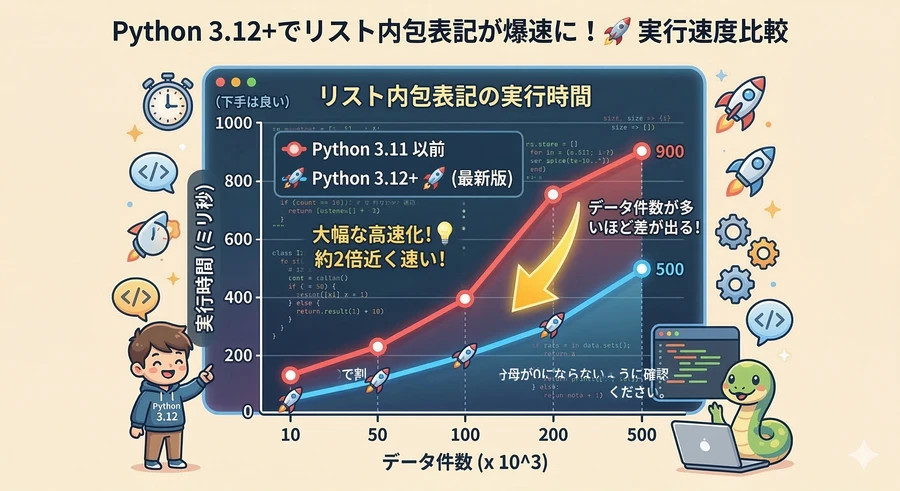
また、Python 3.13ではドキュメント文字列(docstring)のメモリ最適化も行われました。コンパイル時にdocstring内の共通する先頭の空白を自動的に削除することで、コンパイル後のバイトコード(.pycファイル)のサイズが約5%削減され、実行時のメモリ使用量も低減されています [1]。
Python 3.13におけるエラーメッセージの進化とデバッグ
初心者がプログラミングを学ぶ上で最大の壁となる「エラー」への対処において、Python 3.13は画期的な改善をもたらしました。トレースバック(エラーの履歴)はデフォルトでカラー化され、どこでどのような問題が発生したかが視覚的に一目で分かるようになっています [1]。
特筆すべきは、データ構造に関連する間違いに対する「提案機能」です。例えば、辞書の属性名を打ち間違えた際(例:d.keys() を d.key() と記述)、最新のインタプリタは「もしかして keys のことですか?」と修正案を提示します [1]。また、標準ライブラリと同じ名前のファイル(例:random.py)を自作してしまい、インポートエラーが発生した際にも、ファイル名の衝突を具体的に指摘し、リネームを推奨するメッセージが表示されます [1]。このような進化は、デバッグ時間を大幅に短縮し、初心者が無用なストレスを感じることなく学習を進めることを可能にします。
実践ガイド:適切なデータ構造を選択するためのフローチャート
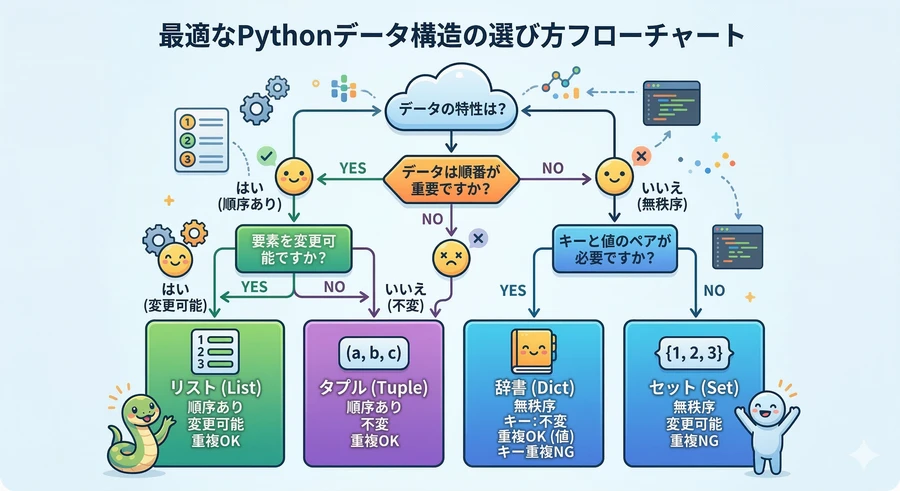
データ構造の選択に迷った際は、以下の基準に基づいて判断することをお勧めします。
順序があり、後から中身を自由に変えたい場合
汎用的な用途であれば リスト(list) を使用します。先頭への頻繁な追加・削除が必要なら deque を選択します [1]。
一度作成したら変更せず、不変性を保ちたい場合
基本は タプル(tuple) を使用します [1]。各要素に意味のある名前を付けて管理したいなら namedtuple が最適です [1]。
データの重複を許さず、値が存在するかどうかを高速に確認したい場合
セット(set) を使用します。これには集合演算(和、積、差)の機能も備わっています [1]。
「名前」と「値」のペアでデータを管理したい場合
基本は 辞書(dict) を使用します。出現回数のカウントが目的なら Counter、初期化を自動化したいなら defaultdict を活用します [1]。
複数の辞書をまとめて一つの設定として扱いたい場合
ChainMap を使用して、優先順位に基づいた検索を実装します [1]。
結論:Pythonが目指す「人間に優しい」データ操作
Python 3.13におけるタプルとコレクションの扱いは、単なる機能の追加に留まらず、開発者とプログラミング言語との対話をより円滑にする方向に進化しています [1]。新しくなったREPLでの試行錯誤、詳細かつ親切になったエラーメッセージ、そして内部的な最適化(PEP 709など)によって高速化されたコンテナ操作は、すべて「人間がより創造的な活動に集中できるようにする」というPythonの設計思想を具現化したものです。
これからPythonを始める方は、まずタプルの「不変性」というコンセプトを理解し、その後 collections モジュールの各クラスがどのような課題を解決するために存在しているのかを、実際に手を動かしながら確かめてみてください。適切なデータ構造を選択するスキルは、効率的なアルゴリズムを構築し、保守性の高いコードを書くための最大の武器となります。
参考資料
1. collections — Container datatypes, https://docs.python.org/3/library/collections.html
2. What’s New In Python 3.13, https://docs.python.org/3/whatsnew/3.13.html
3. What’s New In Python 3.12, https://docs.python.org/3/whatsnew/3.12.html
4. Python Standard Library, https://docs.python.org/3/library/index.html
5. What's New in Python, https://docs.python.org/3/whatsnew/index.html
6. Pythonのタプルとリストの違い, https://www.lifewithpython.com/2017/12/python-tuple-list-difference.html
7. タプル(中級者向け) - 小山工業高等専門学校, https://www.oyama-ct.ac.jp/tso/workshop/python/python07.html
8. Pythonのタプルは読み取り専用のリスト, https://ai-inter1.com/python-tuple/
9. All You Need to Know About the “collections” Module in Python, https://medium.com/@dhruv-panchal/all-you-need-to-know-about-the-collections-module-in-python-c219b8a96f68
10. Python Collections Module - GeeksforGeeks, https://www.geeksforgeeks.org/python/python-collections-module/
11. Python beginner's guide - IBM Developer, https://developer.ibm.com/tutorials/python-beginners-guide/
12. Beginner's Guide to Python, https://wiki.python.org/moin/BeginnersGuide
13. Python 3.13の改善点 - プログラミング問題.com, https://programming-mondai.com/python-3-13/
14. 辞書を使うときの注意点とベストプラクティス, https://muusannitizyou.jp/python-dictionary/
15. 各コンテナの特徴と用途 - Qiita, https://qiita.com/Tadataka_Takahashi/items/073335639b472d7e782c
16. Pythonの組み込みデータ型とcollectionsモジュール, https://www.capa.co.jp/archives/7169
17. リスト操作とdequeの使い分け - テックジム, https://techgym.jp/column/list/
18. Python 3.13 Significant improvements in the standard library, https://docs.python.org/3/whatsnew/3.13.html
19. Python 3.12 Summary – Release highlights, https://docs.python.org/3/whatsnew/3.12.html
20. What's New In Python Index, https://docs.python.org/3/whatsnew/index.html
21. What's New in Python 3.12 - Library Changes, https://www.andy-pearce.com/blog/posts/2024/Mar/whats-new-in-python-312-library-changes/
22. Python 3.13 New Features - GeeksforGeeks, https://www.geeksforgeeks.org/python/python-3-13-new-features/
23. Python 3.13 エラーメッセージの改善, https://programming-mondai.com/python-3-13/
24. Python 3.13 REPLの大幅な改良, https://fullfront.co.jp/blog/technology-development/python/python-latest-version-installation-guide/
25. よりよいインタラクティブインタプリタ - Zenn, https://zenn.dev/akasan/articles/423451d2bb8249
26. 罠:アイテム1のタプルもカンマが必要, https://qiita.com/python_academia/items/c71fdd6c08c27a3cf2e0
27. 要素が一つだけのタプルを作成する方法, https://www.lighthouselab.co.jp/2019/12/04/python-tuple1/
28. Pythonで要素数が1個のタプルを生成する際の注意, https://note.nkmk.me/python-tuple-single-empty/
29. Pythonのタプルで要素が1つの時にカンマを付ける理由, https://saycon.co.jp/archives/neta/python%E3%81%AE%E3%82%BF%E3%83%97%E3%83%AB%E3%81%A7%E8%A6%81%E7%B4%A0%E3%81%8C1%E3%81%A4%E3%81%AE%E6%99%82%E3%81%AB%E3%82%AB%E3%83%B3%E3%83%9E%E3%80%8C%E3%80%8D%E3%82%92%E4%BB%98%E3%81%91%E3%82%8B
30. 要素がひとつの場合はカンマをつけないと単一の値とみなされる, https://www.python.ambitious-engineer.com/archives/168
31. 文字ごとのカウントを行うサンプル - Relief, https://www.relief.jp/docs/python-collections-counter.html
32. collections.Counterで出現回数をカウント, https://note.nkmk.me/python-collections-counter/
33. Python 3.13 Performance and JIT - Lucent Innovation, https://www.lucentinnovation.com/resources/technology-posts/python-new-release-performance-improvement-python-repl
34. Python 3.13 Performance - Dev.to, https://dev.to/t_robertsavo_1e4fa683606/python-313-performance-debunking-hype-optimizing-code-4a82
35. Python 3.12/3.13 Internals and DevOps, https://medium.com/@devopsbyte25/python-3-12-3-13-internals-what-actually-changed-and-why-devops-engineers-should-care-c969478fee4b
36. namedtuple vs データクラス, https://note.com/xaiondata/n/n0aaaeffe65f2
37. リスト内包表記の文法を理解しよう, https://aiacademy.jp/media/?p=1252
38. 内包表記の基本と利点, https://tech.pjin.jp/blog/2021/02/18/python_9_4/
39. 集合内包表記と辞書内包表記 - KinoCode, https://kino-code.com/introductory-and-applied15/
40. 内包表記のメリットと基本形 - しぶたんブロマーズ, https://www.shibutan-bloomers.com/python-basic-list/200/
41. リスト内包表記の注意点 - Zenn, https://zenn.dev/yogurt/articles/290e6a40b39dcb
42. Python 3.13 エラーメッセージ改善の具体例 - PyQ Blog, https://blog.pyq.jp/entry/python_news_240722
43. エラーメッセージの品質向上とモジュール衝突の検知, https://fullfront.co.jp/blog/technology-development/python/python-3-13-new-features-installation/
ーーーーーーーーーーーーーーーーーーーーー2022年8月18日執筆ーーーーーーーーーーーーーーーーー
はじめに
前回のPython入門(11)では、Pythonの辞書オブジェクトについて学びました。
Python入門の第十二弾として、Pythonのタプルとコレクションについて紹介します。
この記事を読むと次の疑問について知ることができます。
それでは、Pythonのタプルとコレクションをこれから始めようとする初心者向けに分かりやすく解説していきます。
Pythonのタブルとは?
Python入門(3)のPythonで扱えるデータ型でもすでに述べていますが、複数のデータが並んだデータ構造で前に学んだリストのデータ構造と同じです。
違いはデータの追加や削除などデータ変更が行えない【このことをイミュータブル(immutable )、逆に変更可能なデータ構造のことをミュータブル(mutable)と言う。】点があります。
タプルは複数のデータを持つ固定したデータ、つまり一度定義したら変更をしないデータを扱う場合に利用します。
このメリットは、リストと比較するとタプルの方が処理速度が速い、つまりパフォーマンスが向上するわけですが、その分データ内の追加、削除などの変更ができないなどの融通が利かない点があります。
タプル、リスト、辞書の違い
タブル、リスト、辞書の主要な違いを表でまとめてみました。
| 主な特徴 | タブル | リスト | 辞書 |
| 定義 | (データ, ....) | [データ, ....] | {データ, ....} |
| 異なるデータ型の格納 | 〇 | 〇 | 〇 |
| データの数 | 可変 | 可変 | 可変 |
| データの変更(書き換え) | ☓ | 〇 | 〇 |
| データ参照 | インデックス | インデックス | キー |
タプルオブジェクトの作成
タプルオブジェクトは、データ要素をまる括弧「(」「)」で囲って作成します。
(データ要素1,データ要素2,データ要素3,……)
データ要素間は「,」半角コンマで区切り何個でも繋げて作成できます。
具体的な例を示すと、
ある日の主要な都道府県(東京、大阪、神奈川、埼玉、北海道)todoufukensとそられのコロナ感染者数、todoufukens_coronaNumを並べて作成すると、次のようになります。
todoufukens = ('東京都', '大阪府', '神奈川県', '埼玉県', '愛知県', '北海道')
todoufukens_coronaNum = (19059, 9745, 7603, 5755, 1734)
タプルとリスト間では相互に変換することが可能です。
タブル⇒リストに変換 : list(タブル名)
リスト⇒タブルに変換 : tuple(リスト名)

「todoufukens」、「todoufukens_coronaNum」内のデータを参照する場合は、インデックスで参照できます。
以下は、Google Colabでインデックスが3の「todoufukens」の’埼玉県’、「todoufukens_coronaNum」の感染者数の「5755」を参照して、それぞれを出力したものです。

コレクション
今まで説明してきたリスト、タプル、辞書などは複数のデータの集まりであり、これら複数のデータを一括して扱えるデータ型を「コレクション」あるいは「コンテナー」などと呼びます。
コレクションの操作
コレクションには、同様に扱える処理が存在し、そのいくつかを紹介します。
コレクションの要素数
コレクションの要素数は、len() 関数で調べることができます。
len(コレクション名)
例として、リスト型データ「todoufukens_list」、辞書型データ「todoufukenscoronaNum」、タプル型データ「todoufukens_coronaNum」の要素数を調べてみましょう。

in 演算子
in 演算子は、コレクション内にそれぞれの要素が含まれているかどうかを調べる演算子で、含まれていれば「True」、含まれていなければ「False」を返します。
in 演算子の構文は次の通り。
調べる要素 in コレクション名 : リスト、タプル型データの場合
キー名 in 辞書名例題として、len()関数で用いたリスト、タプル、辞書型データを使って、リストの場合は「東京」が含まれているかどうか(結果:True)、辞書の場合はキー「愛知」が含まれているか(結果:False)、タプルの場合は感染者数「5755」が含まれているかどうか(結果:True)を調べてみましょう。

for 文
for文を利用することにより、リスト、タプル、辞書内のデータを要素ごとに取り出したり、参照したりできます。
下記の例は、len()関数で用いたリスト、タプル、辞書型データを使って、リストとタブルデータの場合と辞書データの場合にそれぞれの要素を取り出し出力しています。

上述の例で示したように、リストとタプルは各要素を参照する際に整数型のインデックスを利用しており、このタイプのコレクションをシーケンスと呼びます。
シーケンスであれば、比較演算子( <、 <=、>、>=など)で比較ができ、比較式が真であれば「True」、偽であれば「False」を返します。(この部分の例は省略)
一方、辞書はキーを利用しますのでシーケンスではありません。そのために、比較演算子などで比較をしようとするとエラーとなります。(この部分の例は省略)
コレクションのアンパック
アンパックとは、リストやタプルなどのコレクションの複数のデータを一度に変数に代入する方法です。
例えば、次の例は「todoufukens」、「todoufukens_coronaNum」の各要素をそれぞれの変数に代入して、それら変数を出力した例です。

おわりに
如何だったでしょうか?
Pythonのタブルとは?、タプル、リスト、辞書の違い、タプルオブジェクトの作成、コレクション、コレクションの操作、コレクションの要素数、in 演算子、for 文、コレクションのアンパックなどについて解説してきました。
この記事を読みながらPythonを学んでもらえればと思います。
次をお楽しみに?
以上です。
コメント