

ーーーーーーーーーーーーーーーーーーーーー2026年3月10日執筆ーーーーーーーーーーーーーーーーー
- Pythonの 辞書オブジェクト、これから始めようとする初心者向けに分かりやすく解説|Python入門(11)のPodcast
- はじめに
- 辞書オブジェクトの概念と基本的な役割
- 辞書の基本的な構造
- 辞書の作成と初期化のバリエーション
- 要素の操作と安全なデータアクセス
- 要素の追加・更新と最新のマージ演算子
- 辞書の反復処理と効率的なループ
- 辞書内包表記によるスマートな作成
- Python 3.10以降の進化:パターンマッチングと最新機能
- Python 3.11〜3.13における高度な型ヒントと最適化
- 初心者が知っておくべき辞書の内部構造とエラー対策
- 辞書オブジェクトを使いこなすためのベストプラクティス
- 参考資料
- はじめに
- Pythonの辞書オブジェクトとは?
- 辞書オブジェクト内の要素の操作
- in 演算子
- おわりに
Pythonの 辞書オブジェクト、これから始めようとする初心者向けに分かりやすく解説|Python入門(11)のPodcast
下記のPodcastは、Geminiで作成しました。
はじめに
Pythonプログラミングの世界へようこそ。本稿では、Pythonにおいて最も強力で、かつ頻繁に使用されるデータ構造の一つである「辞書(dictionary)」オブジェクトについて、最新の仕様に基づき徹底的に解説していきます。プログラミング初心者の方でも、基礎から応用までを体系的に学べるよう、丁寧かつ詳細に進めてまいります。
辞書オブジェクトの概念と基本的な役割
Pythonの辞書は、現実世界の「国語辞典」や「住所録」に例えられることが多いデータ構造です。例えば、国語辞典で「Python」という単語を引くと、その意味が記述されています。このように、特定の「キーワード」を指定して、それに対応する「内容」を取り出す仕組みを、プログラミングの世界では「キー(Key)」と「値(Value)」のペアと呼びます [1]。
辞書は、技術的には「マッピング型」に分類されます。リストが「データの並び順(インデックス)」で要素を管理するのに対し、辞書は「名前(キー)」で要素を管理するため、大量のデータの中から特定の情報を一瞬で見つけ出すことに非常に長けています [2]。

辞書の基本的な構造
辞書は波括弧 {} を使って作成します。キーと値の間はコロン : で繋ぎ、それぞれのペアはカンマ , で区切ります。
| 構成要素 | 説明 | 具体的な例 |
|---|---|---|
| キー (Key) | データの名前。重複は許されず、不変な型(文字列や数値など)である必要があります。 | "名前", "age", 101 |
| 値 (Value) | データの内容。リストや他の辞書など、どのような型でも格納可能です。 | "山田太郎", 25, ["apple", "banana"] |
| ペア | キーと値をコロンで結んだ一つのセット。 | "name": "Alice" |
このように、辞書は「何が(キー)」「何であるか(値)」を明確に定義して保持するための最適なツールと言えます [3]。
辞書の作成と初期化のバリエーション
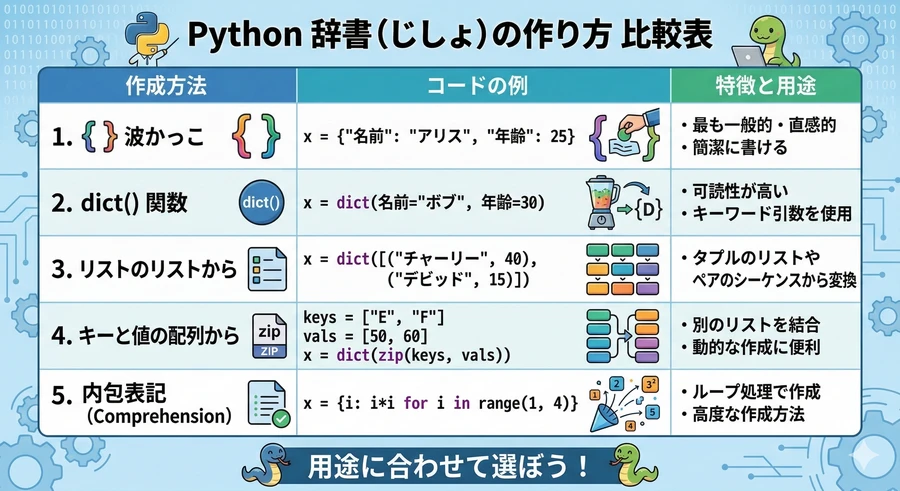
辞書を作成する方法にはいくつかあり、用途に応じて使い分けることが重要です。最新のPython環境(3.10〜3.13)においても、これらの基本は変わりませんが、より簡潔な記述が好まれる傾向にあります。
リテラルとdict関数による作成
最も一般的なのは、直接波括弧を書く「辞書リテラル」による作成です。一方で、dict() 関数を用いることで、引数形式やタプルのリストから辞書を生成することも可能です [4]。
| 作成手法 | 記述例 | 特徴 |
|---|---|---|
| 直接記述 | data = {"apple": 100, "banana": 200} | 最も直感的で読みやすい方法です [5]。 |
| dict() 関数 (引数) | data = dict(apple=100, banana=200) | キーを引用符なしで記述でき、可読性が高まります [6]。 |
| dict() 関数 (変換) | data = dict([("apple", 100), ("banana", 200)]) | 他のデータ形式を辞書に変換する際に便利です [7]。 |
| 空の辞書 | empty = {} または empty = dict() | 後から要素を追加するための土台として使います [8]。 |
辞書を作成する際、初心者が間違いやすいのは括弧の種類です。リストは []、タプルは ()、そして辞書は {} を使用することを忘れないようにしましょう [9]。
要素の操作と安全なデータアクセス
辞書に格納されたデータを利用する際、単純なアクセス方法だけでなく、エラーを防ぐための安全な手法を身につけることが、実戦的なプログラミングへの第一歩となります。
角括弧によるアクセスとエラーの回避
辞書から値を取り出す基本は、辞書名[キー] という形式です。しかし、指定したキーが辞書の中に存在しない場合、Pythonは KeyError というエラーを発生させてプログラムを停止させてしまいます [10]。
このリスクを回避するために推奨されるのが get() メソッドです。get() を使用すれば、キーが存在しない場合でもエラーにならず、None(空の状態)を返してくれます。さらに、第2引数に「デフォルト値」を設定することで、キーがない場合に特定の値を返すように指定することも可能です [11]。
| メソッド・操作 | キーがない時の挙動 | 推奨されるケース |
|---|---|---|
| d[key] | KeyError が発生 | キーが必ず存在することが分かっている時 |
| d.get(key) | None を返す | キーがあるか不確かな時 |
| d.get(key, 0) | 指定したデフォルト値(例:0)を返す | カウント処理や初期値が必要な時 |
要素の追加・更新と最新のマージ演算子
辞書に要素を追加、あるいは既存の値を更新する操作は非常にシンプルです。d[key] = value と記述するだけで、キーがなければ追加され、あれば更新されます [12]。
また、Python 3.9以降では、二つの辞書を結合するための「マージ演算子 |」と「更新演算子 |=」が導入されました [13]。これにより、従来の update() メソッドを使用するよりも直感的に、新しい辞書を生成したり既存の辞書を拡張したりできるようになっています。例えば、new_dict = dict1 | dict2 と書くことで、dict1 と dict2 を合わせた新しい辞書が手に入ります。同じキーがある場合は、右側の辞書(この場合は dict2)の値が優先されます [14]。
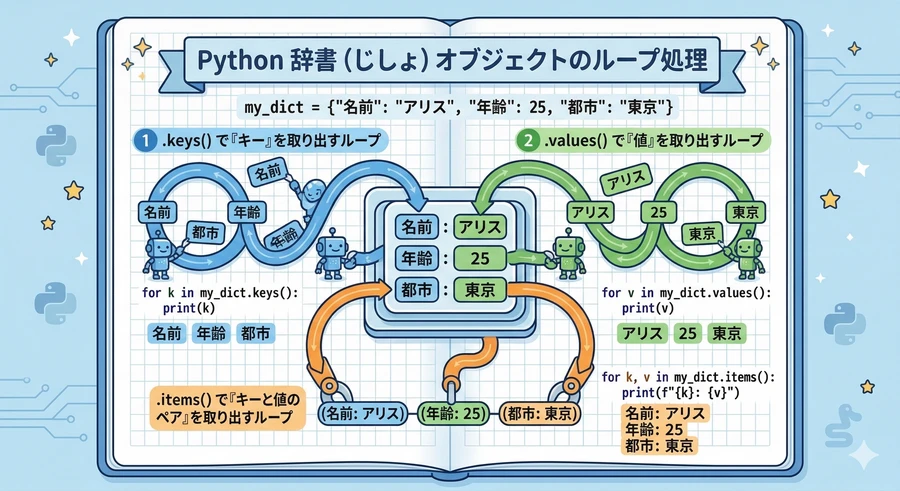
辞書の反復処理と効率的なループ
辞書に含まれる全てのデータを順番に処理したい場合、for 文と組み合わせた「ビューオブジェクト」の利用が不可欠です。
キー、値、アイテムの使い分け
辞書オブジェクトには、反復処理をサポートするための3つの重要なメソッドがあります [15]。
keys(): 全てのキーをリストのように取り出します。for k in d: と書いた場合も、デフォルトでこのキーが参照されます。
values(): キーは無視して、値だけを順番に取り出します。
items(): キーと値のペアをタプルとして取り出します。
特に items() メソッドは、for key, value in d.items(): のように「アンパック(展開)」して記述することで、ループの中でキーと値の両方を同時に扱えるため、最も多用される手法です [16]。
辞書内包表記によるスマートな作成
Pythonには「内包表記」という、リストや辞書を1行で効率的に作成するための高度な構文があります [17]。これは、既存のデータから特定の条件に合うものだけを抜き出したり、値を加工して新しい辞書を作ったりする際に威力を発揮します。
例えば、数値のリストから「数値をキー、その2乗を値」とする辞書を作る場合、通常のループでは数行かかるところを、内包表記なら {x: x**2 for x in range(5)} と書くだけで済みます [18]。この書き方は単に短いだけでなく、Pythonの内部で最適化されているため、処理速度が向上するというメリットもあります [19]。
Python 3.10以降の進化:パターンマッチングと最新機能
近年のPythonアップデートは、辞書の操作性をより洗練されたものにしています。初心者のうちからこれらの最新機能を意識しておくことで、将来的に読みやすく保守しやすいコードが書けるようになります。
構造化パターンマッチング(match-case)
Python 3.10で導入された match-case 文は、辞書の構造を「形」で判定できる画期的な機能です [20]。これは、従来の if-elif 文による条件分岐をより直感的に記述できるようにしたものです。特に「マッピングパターン」と呼ばれる辞書に対するマッチングでは、辞書が特定のキーを持っているか、その値が特定の条件を満たしているかを一瞬で判別できます [21]。
例えば、APIから返ってきた複雑な辞書データに対して、「"status" キーが "success" であり、かつ "data" キーが存在する場合」といった複雑なチェックを、テンプレートを当てるような感覚で記述できます [22]。
辞書の順序保証と現代的な仕様
かつてのPythonでは、辞書の要素に「順番」という概念はありませんでした。しかし、Python 3.7以降は「要素を追加した順番」が保持されることが言語の公式な仕様となりました [23]。これにより、辞書をループで回した際の挙動が予測可能になり、プログラムの安定性が向上しました。以前は順序を保持するために collections.OrderedDict という特別なクラスを使う必要がありましたが、現在の標準的な辞書(dict)であれば、特別な工夫なしに順番を気にした処理が可能です [24]。
Python 3.11〜3.13における高度な型ヒントと最適化
Pythonは、コードの意図を明確にするための「型ヒント」機能も強化し続けています。特に辞書に関連して、Python 3.11で導入された TypedDict の改良は重要です。
必須項目と任意項目の定義
TypedDict を使うと、辞書がどのようなキーと型を持つべきかを定義できます。Python 3.11からは、Required や NotRequired を使って、「このキーは必須だが、あのキーはなくても良い」という細かい指定が個別にできるようになりました [25]。
python
from typing import TypedDict, NotRequired
class UserProfile(TypedDict):
username: str # 必須
bio: NotRequired[str] # 任意このような定義を行うことで、開発ツール(VS Codeなど)が入力補全やエラーチェックをより正確に行ってくれるようになり、開発効率が大幅に向上します [26]。また、Python 3.13でも標準ライブラリの微細な改善が続いており、データのコピーや置換といった操作がより安全に行えるようになっています [27]。
初心者が知っておくべき辞書の内部構造とエラー対策
辞書をより深く理解するために、その裏側にある仕組みと、エラーが発生した際の対処法についても触れておきましょう。
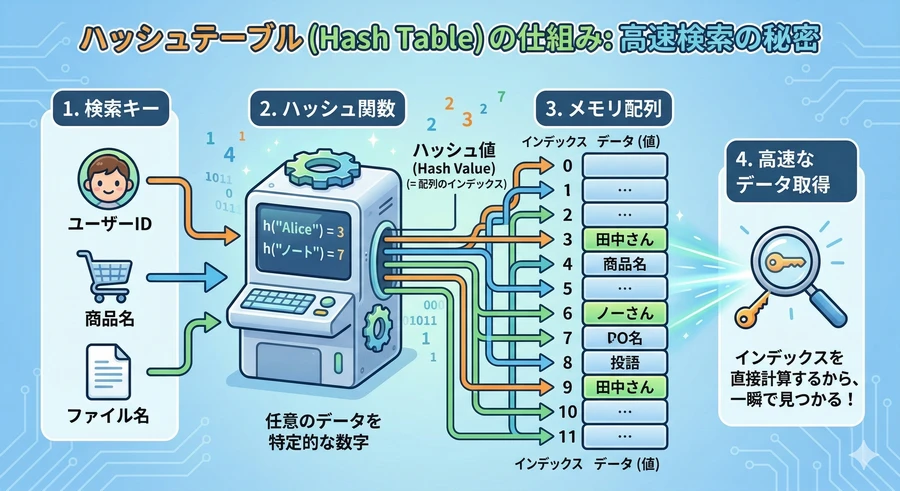
ハッシュテーブルとパフォーマンス
辞書が高速である理由は、「ハッシュテーブル」という技術に基づいているからです [28]。キーとなる値を「ハッシュ関数」という仕組みで計算し、データの格納場所を一意に決定します。このため、辞書の中に何万件のデータがあっても、目的のデータを見つけるスピードはほとんど変わりません。
ただし、この仕組み上、辞書のキーには「内容が変わらない(イミュータブルな)」オブジェクトしか使えないという制限があります。例えば、リストをキーにしようとすると、リストは後から内容を変更できてしまうため、ハッシュ値が安定せず、エラーになります [29]。
エラーメッセージの親切化
Python 3.10以降、辞書の記述にミスがあった際のエラーメッセージが非常に分かりやすくなりました [30]。
コロン : を忘れた場合
カンマ , を忘れた場合
括弧を閉じ忘れた場合
これらのミスに対して、Pythonのインタープリタは「ここを忘れていませんか?」と具体的に指摘してくれるようになりました。初心者のうちはエラーが出ることを恐れず、メッセージを読み解く習慣をつけることが大切です。
辞書オブジェクトを使いこなすためのベストプラクティス
最後に、辞書を使用する際の推奨される考え方をまとめます。
| 観点 | 推奨されるアクション | 理由 |
|---|---|---|
| データの取得 | 基本的に get() メソッドを利用する。 | キーの不在による予期せぬエラー(クラッシュ)を防ぐためです [31]。 |
| 存在確認 | if key in dictionary: を活用する。 | キーが存在するかどうかを事前に確認する最も効率的な方法です。 |
| 辞書の生成 | リストからの変換や内包表記を活用する。 | 手動で一つずつ追加するよりも、コードが短くなり実行速度も速くなります。 |
| 最新機能の利用 | Python 3.10以上の環境なら match-case を検討する。 | 複雑なデータ構造の解析が驚くほどシンプルに記述できます。 |
辞書は、Pythonのプログラミングにおいてデータの「整理棚」のような役割を果たします。この機能をマスターすることで、複雑な情報をシンプルに、そして高速に扱うことができるようになります。まずは身近なデータを辞書に当てはめることから始めてみてください。
参考資料
1. Python 3.11 What's New, https://docs.python.org/3/whatsnew/3.11.html
2. What's New In Python (Index), https://docs.python.org/3/whatsnew/index.html
3. Python 3.13 What's New, https://docs.python.org/3/whatsnew/3.13.html
4. Python 3.12 What's New, https://docs.python.org/3/whatsnew/3.12.html
5. Python 3.10 What's New, https://docs.python.org/3/whatsnew/3.10.html
6. Pythonの辞書(dict)の基本的な使い方、https://www.rstone-jp.com/column/144864/
7. Pythonの辞書(dict)の使い方、https://web-camp.io/magazine/archives/15340/
8. Pythonのリスト内包表記と辞書内包表記、https://aiacademy.jp/media/?p=1252
10. Python 辞書内包表記の解説、https://trends.codecamp.jp/blogs/media/terminology628
11. Python リスト・辞書内包表記の基本と応用、https://zenn.dev/yogurt/articles/290e6a40b39dcb
12. 辞書内包表記の活用、https://paiza.jp/works/reference/article-python-dict
13. Python 3.7 辞書の順序保証(公式ドキュメント)、https://docs.python.org/ja/3/library/collections.html
14. Python 辞書の順序に関する議論、https://www.reddit.com/r/learnpython/comments/zi1t86/are_python_dictionaries_ordered/?tl=ja
15. 辞書の順番を保持した重複削除、https://devlights.hatenablog.com/entry/2019/03/06/185357
16. 構造化パターンマッチング(公式リファレンス)、https://docs.python.org/ja/3.10/reference/compound_stmts.html
17. Python 3.10 構造化パターンマッチング、https://www.lifewithpython.com/2021/06/python-structual-pattern-matching.html
18. 辞書のハッシュ化とメモリ効率、https://www.reddit.com/r/Python/comments/1fdkpkz/dict_hash_efficient_hashing_for_python/?tl=ja
19. 組み込み型 ― Python 3.10 ドキュメント(辞書)、https://docs.python.org/ja/3/library/stdtypes.html#mapping-types-dict
20. Python辞書のループ処理、https://note.nkmk.me/python-dict-keys-values-items/
21. Python辞書のgetメソッドの使い方、https://note.nkmk.me/python-dict-get/
ーーーーーーーーーーーーーーーーーーーーー2022年8月2日執筆ーーーーーーーーーーーーーーーーー
はじめに
前回のPython入門(10)では、Pythonのオブジェクトとリストについて学びました。
Python入門の第十一弾として、Pythonの辞書オブジェクトについて紹介します。
この記事を読むと次の疑問について知ることができます。
それでは、Pythonの辞書オブジェクトをこれから始めようとする初心者向けに分かりやすく解説していきます。
Pythonの辞書オブジェクトとは?
Python入門(3)のPythonで扱えるデータ型でもすでに述べていますが、キーと値をペアとして登録できるデータ構造を言います。
例えば、現在のコロナ禍での感染者数を日本の各都市をキーとして、それぞれの感染者数の値を持つ辞書を登録した場合、日本の都市を指定してやれば指定した都市のコロナ感染者数をすぐに取り出すことができます。
辞書型の特徴はキーを指定すると高速に値を参照できることにあります。
この各都市名とコロナ感染者数のペアは一意であり、同じ都市名のキーで新たに違った感染者数を登録すると上書きされます。
キーと値
前述の日本の各都市名とコロナ感染者数の辞書を考えた場合に、各都市名をキーと呼び、その都市に紐づいた感染者数を値と呼びます。
そして、このキーと値は「:」半角コロンで紐づけます。
上述の例で書くと、「’東京都’:19059」は、東京都をキー、その感染者数19059が値です。
辞書オブジェクトの作成
辞書オブジェクトは、先ほどのキーと値のペア―を波括弧「{」「}」で囲って作成します。
{キー1:値1,キー2:値,……}
キーと値のペアとの間は「,」半角コンマで区切り何個でも繋げて作成できます。
具体的な例を示すと、
ある日の主要な都道府県(東京、大阪、神奈川、埼玉、北海道)のコロナ感染者数を並べて作成すると、次のようになります。(愛知:6351)
todoufukens_coronaNum = {'東京':19059, '大阪':9745, '神奈川':7603, '埼玉':5755, '北海道':1734}
「todoufukens_coronaNum」は主要な都道府県の文字列をキー、その都市の感染者数の値を持った辞書であり、キーを指定してやれば、指定したキーの都市の感染者数を容易に取り出すことができます。
また、キーと値を何も無い空の辞書オブジェクトを作成することもできます。
empty_d1 = {} # 又は
empty_d2 = dict() # dictメソッドを使用した空の辞書オブジェクトの作成以下は、Google Colabで空の辞書を作成し、それぞれを出力したものです。

辞書オブジェクトの要素の参照
辞書オブジェクト内の要素をどのようにして参照するかと言うと、辞書オブジェクトの名前に[キー名]を付けることにより参照できます。
辞書オブジェクト名[キー名]例えば、先に作成した辞書オブジェクトで各都市とコロナ感染者数の場合で、北海道の感染者数を参照したい場合は、次のようになります。
todoufukens_coronaNum['北海道']
ここで、辞書オブジェクト内に無いキーを指定した場合はエラーになりますので注意しましょう。
以下は、Google Colabで書いたものです。

辞書オブジェクト内の要素の操作
辞書オブジェクト内の要素の操作には、要素の追加、削除、置換などが行えます。
要素の追加及び置換
辞書に要素を追加したり置換する場合には、次のようにします
辞書オズジェクト名[キー名] = 値
例として、先の都道府県とコロナ感染者数の辞書オブジェクトに沖縄とその感染者数を追加してみましょう。
また、東京都の感染者数を変更して「18919」に変更して見ます。

要素の削除
辞書オブジェクト内の要素を削除したい場合は、del 文を用います。
del 文の構文は次の通り。
del 辞書オブジェクト名[キー名]
例題として、先ほど置換した沖縄と沖縄のコロナ感染者数を削除して見ましょう。

辞書オブジェクトの要素数
辞書オブジェクトの要素数は、リストオブジェクトの要素数を求める場合と同じ「len」を使います。
先程の都道府県のコロナ感染者数の辞書オブジェクトの数を求めてみましょう。

in 演算子
「in 演算子」は、辞書内のキーが「ある」か「ない」かを調べることができます。
キー名 in 辞書オブジェクト名
「ある」場合は「True」を、「ない」場合は「False」を返します。
例題として、先ほど都道府県のコロナ感染者数の辞書オブジェクトで、東京の場合(辞書オブジェクト内にあるので「True」)と沖縄の場合(辞書オブジェクトにないので「False」)を返します。

in 演算子を使った簡単な例題
ここでは、「in 演算子」を使って簡単な例題を作成してみましょう。
input文で都市を入力し、その都市が辞書オブジェクトに「あれ」ば、その都市のコロナ感染者数を表示し、「なけれ」ば、その都市のコロナ感染者数を入力し、入力したあとでその都市とコロナ感染者を表示するプログラムを作成してみます。
この例では、沖縄を入力し、辞書オブジェクトには「ない」のでコロナ感染者数を入力し表示させています。

おわりに
如何だったでしょうか?
Pythonの辞書オブジェクトとは?、キーと値、辞書オブジェクトの作成、辞書オブジェクトの要素の参照、辞書オブジェクト内の要素の操作、要素の追加及び置換、要素の削除、辞書オブジェクトの要素数、in 演算子、in 演算子を使った簡単な例題などについて解説してきました。
この記事を読みながらPythonを学んでもらえればと思います。
次をお楽しみに?
以上です。

コメント