

XPath入門、取得、書き方、関数なども解説のPodcast
下記のPodcastは、Geminiで作成しました。

XPathの定義と現代における重要性
XPath(XML Path Language)は、XML文書やHTMLドキュメント内の特定の要素や属性を柔軟に指し示すためのクエリ言語です。1999年にW3C(World Wide Web Consortium)によって最初に勧告されたこの言語は、当初XSLT(XML変換言語)などの補完的な技術として開発されましたが、現在ではウェブスクレイピング、自動テスト、フロントエンド開発など、多岐にわたる分野で必須の技術となっています [1] 。現代のウェブ開発において、DOM(Document Object Model)から要素を特定する手法としてCSSセレクタが一般的ですが、XPathはCSSセレクタでは到達できない「親要素への遡り」や「高度なテキスト検索」といった強力な機能を備えています [2] 。そのため、複雑な動的サイトや構造が不規則なドキュメントからデータを抽出する際には、依然としてXPathが最も信頼性の高い手段として選ばれています [3] 。2025年現在、ウェブブラウザの標準機能として利用できるのは主にXPath 1.0ですが、最新の自動化フレームワークやAIを活用したスクレイピングツールでは、この古典的な言語が最新のテクノロジーと融合し、新しい価値を提供し続けています [4] 。
XPathのバージョンとブラウザのサポート状況
XPathには、歴史の経過とともにいくつかのバージョンが策定されてきました。しかし、ブラウザの実装状況には大きな偏りがあるため、開発者はどのバージョンが「どこで動くのか」を正確に把握しておく必要があります。
バージョン間の主な違いとブラウザサポート
| バージョン | 勧告年 | 主な特徴 | ブラウザサポート状況 (2025年時点) |
|---|---|---|---|
| XPath 1.0 | 1999年 | 基本的なパス指定、ノードセット操作、文字列関数。 | Chrome, Firefox, Safari, Edgeなど主要ブラウザが完全サポート [5] 。 |
| XPath 2.0 | 2007年 | データ型の強化、正規表現、より高度な関数の追加。 | ネイティブサポートなし。外部ライブラリ(Saxon-JS等)が必要 [6] 。 |
| XPath 3.0/3.1 | 2014/2017年 | JSONサポート、マップ・配列の導入、関数プログラミング的要素。 | ネイティブサポートなし。ウェブ開発での利用は限定的 [7] 。 |
主要ブラウザが長年XPath 1.0に留まっている理由は、セキュリティ上の懸念や実装の複雑さにあります。例えば、Chromiumで使用されている処理ライブラリ「libxslt」は非常に古く、バッファオーバーフローなどの脆弱性が指摘されてきました [8] 。そのため、ベンダーは古いAPIの更新よりも、CSSセレクタなどのパフォーマンスに優れた代替技術を優先する傾向にあります [9] 。
XPathの 基本構文:絶対パスと相対パス
XPathは、ディレクトリ構造を示すパス表記(/や//)を用いてノードを指定します。
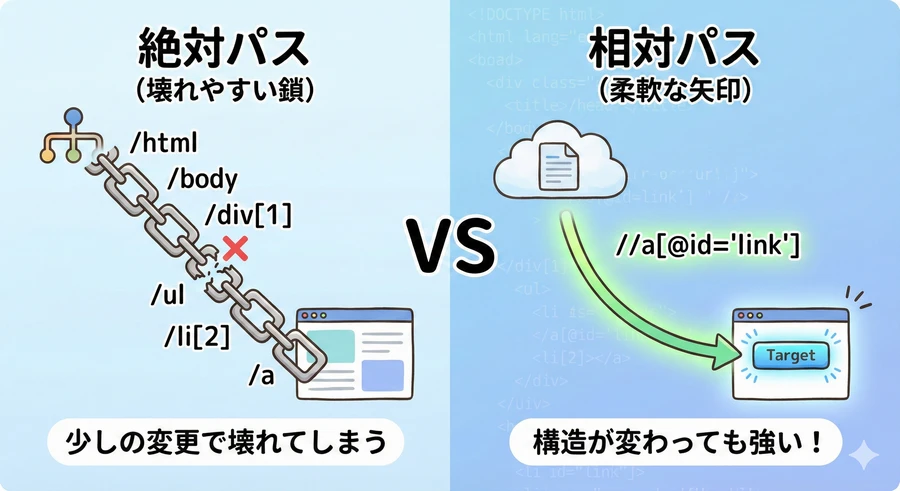
絶対パス(Absolute Path)
/(スラッシュ1つ)から書き始め、ルート要素から順に階層を辿る方法です [10] 。
例: `/html/body/div/p`
特徴: ページの構造がわずかでも変わると(例えば新しい広告要素が挿入されるなど)、すぐに無効になってしまう「脆さ」があります。実務での使用は推奨されません [11] 。
相対パス(Relative Path)
//(スラッシュ2つ)から書き始め、文書内のどこに位置していても、指定した条件に一致する要素を検索する方法です [12] 。
例: `//p`(文書内のすべてのp要素)
特徴: 構造の変化に強く、特定の要素を効率的にピンポイントで指定できるため、スクレイピングや自動テストではこちらが標準的に使用されます [13] 。
述語(Predicate)によるフィルタリングと属性指定
述語は、ノードセットの中からさらに条件を絞り込むための仕組みで、角括弧 `[]` 内に記述します。
属性値による指定
特定のIDやクラス、あるいはその他の属性を持つ要素を特定する際に多用されます。属性名の前には必ず @ マークを付けます [14] 。
| 記述例 | 意味 |
|---|---|
| `//div[@id='main']` | IDが「main」であるdiv要素を選択する [15] 。 |
| `//input[@type='submit']` | type属性が「submit」であるinput要素を選択する [16] 。 |
| `//a[@href]` | href属性を持つすべてのa要素を選択する [17] 。 |
数値・位置による指定
同じ種類の要素が複数並んでいる場合、その順番で指定できます。XPathのインデックスは 1から始まる ことに注意が必要です [18] 。
`//li[1]` : 最初にあるli要素 [19] 。
`//li[last()]` : 最後にあるli要素 [20] 。
`//li[position() <= 3]` : 最初から3番目までのすべてのli要素 [21] 。
XPath軸(Axes):ノード間の関係性を利用した高度な検索
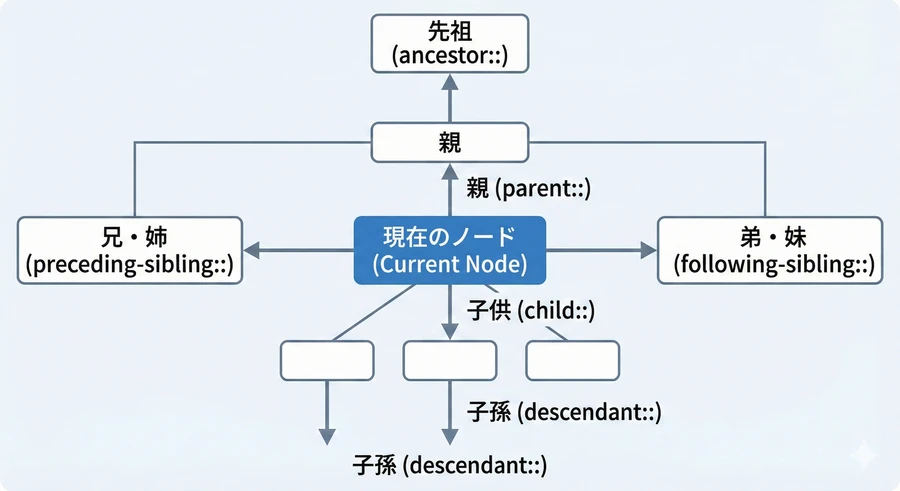
軸(Axes)は、現在のノード(基準点)から見て「どの方向(親、子、兄弟など)」にターゲットを探しに行くかを定義するものです。CSSセレクタでは不可能な、複雑な関係性に基づく要素特定を可能にします。
主要な軸の一覧と活用
| 軸名 | 意味 | 解説と用途 |
|---|---|---|
| child | 子供 | 直下の要素(デフォルトであり、通常は省略可能) [14] 。 |
| parent | 親 | 1つ上の親要素を選択する。.. と同様 [15] 。 |
| ancestor | 先祖 | 親、祖父母、さらに遡るすべての要素を含む [16] 。 |
| descendant | 子孫 | 直下の子供からさらに孫要素まで、すべての階層を含む [17] 。 |
| following-sibling | 弟(後の兄弟) | 同じ親を持つ兄弟の中で、自分より後ろにある要素を選択する [18] 。 |
| preceding-sibling | 兄(前の兄弟) | 同じ親を持つ兄弟の中で、自分より前にある要素を選択する [19] 。 |
軸の記述例
軸名に続いて ::(ダブルコロン)を記述します。
`//h2/following-sibling::p`
この式は、「h2要素の次に出現する、同じ階層にあるすべてのp要素」を選択します。特定のラベル(例:「氏名」)の後にある入力フォームを指定したい場合などに非常に有効です。
XPath関数の解説と応用
XPath 1.0には、要素選択をより柔軟にするための標準関数が豊富に用意されています [22] 。
contains() 関数
部分一致による検索を行います。クラス名が複数設定されている要素(例:`<div class="btn active">`)を探す際に欠かせません [23] 。
例: `//div[contains(@class, 'btn')]`
text() 関数
要素に含まれるテキストそのものを条件にします [24] 。
例: `//button[text()='送信']`
※注意:要素内に他のタグが含まれている場合(例:`<button><span>送信</span></button>`)、text() は直下のテキストノードのみを見るため失敗することがあります。その場合は .(コンテキストノード)を使用します [25] 。
starts-with() 関数
特定の文字列で始まる属性値を検索します。
例: `//a[starts-with(@href, 'https://')]`
normalize-space() 関数
前後の空白を削除し、途中の連続した空白や改行を1つのスペースに変換して比較します [26] 。
例: `//span[normalize-space()='Price']`
translate() 関数を用いた大文字・小文字の無視
XPath 1.0には lower-case() 関数がないため、translate() を使って文字を置換するテクニックが使われます [27] 。
例: `//a[translate(@type, 'SUBMIT', 'submit')='submit']`
これにより、大文字・小文字の表記揺れに関わらず「submit」を検索できます [28] 。
JavaScriptでのXPathの実行方法
フロントエンド開発やブラウザ拡張機能の開発では、JavaScriptの `document.evaluate()` メソッドを介してXPathを使用します [29] 。
document.evaluate() の基本構造
javascript
const result = document.evaluate( xpathExpression, // XPath式(文字列) contextNode, // 検索の起点(通常は document) namespaceResolver,// 名前空間リゾルバー(通常は null) resultType, // 期待する戻り値の型 result // 既存のオブジェクト(通常は null) );
XPathResult 型の使い分け
評価結果として返される XPathResult オブジェクトには、データの性質に応じた定数が定義されています [30] 。
| 定数名 | 値 | 取得方法と特徴 |
|---|---|---|
| ANY_TYPE | 0 | 最適な型を自動選択する [31] 。 |
| NUMBER_TYPE | 1 | 数値を取得。`result.numberValue` [32] 。 |
| STRING_TYPE | 2 | 文字列を取得。`result.stringValue` [33] 。 |
| UNORDERED_NODE_ITERATOR_TYPE | 4 | 一致した複数の要素を順番に取得。`result.iterateNext()` [34] 。 |
| ORDERED_NODE_SNAPSHOT_TYPE | 7 | 静的なノードリストを取得。`result.snapshotItem(i)` [35] 。 |
| FIRST_ORDERED_NODE_TYPE | 9 | 最初の一致要素のみ取得。`result.singleNodeValue` [36] 。 |
スナップショット型は、イテレーター型と異なり、反復処理中にDOMの構造が変更(要素の削除や移動など)されても、取得済みのリストが無効にならないという利点があります。
デベロッパーツールを用いたXPathの取得と検証
XPathを手書きするのは初心者にとって難易度が高い作業ですが、ブラウザの「デベロッパーツール(開発者ツール)」を活用すれば、簡単に取得と検証が行えます [37] 。
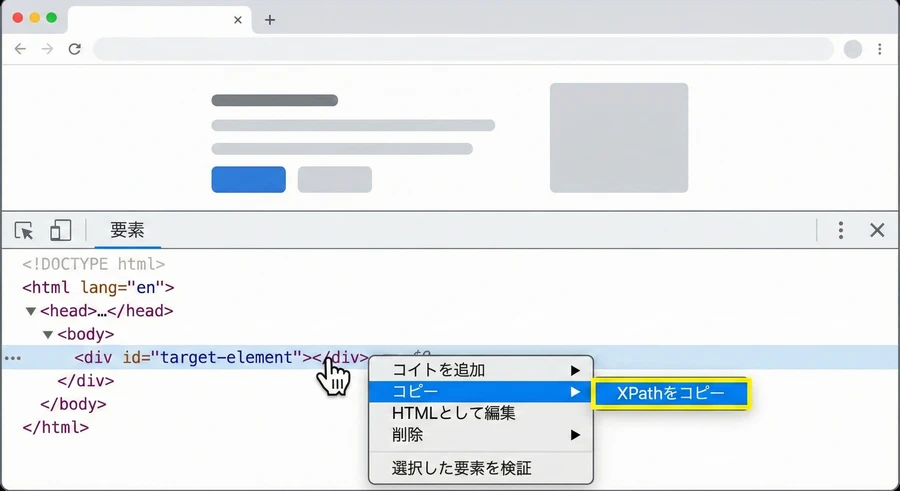
開発者ツールでの取得手順
1. 対象のウェブページで F12 キーを押すか、右クリックして「検証」を選択します。
2. 「Elements」タブで、特定の要素を選択し、青くハイライトされた箇所で右クリックします [38] 。
3. 「Copy」メニューから「Copy XPath」を選択すれば、クリップボードにXPathがコピーされます [39] 。
Consoleでの検証($x関数の利用)
コピーしたXPathが正しく動作するかどうかは、「Console」タブでテストできます。`$x('ここにXPathを貼り付け')` と入力してEnterを押します [40] 。一致する要素があれば、配列形式で展開されます [41] 。要素にマウスを合わせると、ページ上の対応する部分がハイライトされるため、正しく特定できているか一目でわかります [42] 。
自動テスト・スクレイピングツールの最新動向 (2025年)
XPathは、SeleniumやPlaywright、Appiumといった自動化ツールの根幹をなす技術ですが、2025年現在は「脱・手書きXPath」の流れも加速しています [43] 。
SeleniumとPlaywrightの比較
| 項目 | Selenium (WebDriver) | Playwright (DevTools Protocol) |
|---|---|---|
| アーキテクチャ | HTTP経由のWebDriver protocol [44] 。 | WebSocketによる直接ブラウザ制御 [45] 。 |
| XPathの扱い | 要素識別の主要な手段の一つ。手動待機が必要な場合が多い [46] 。 | XPathもサポートするが、役割ベース(getByRole)を推奨 [47] 。 |
| 安定性 | タイミングにより不安定(Flaky)になりやすい [48] 。 | 自動待機機能により、XPathが安定して動作する [49] 。 |
Playwrightは、XPathが「実装の詳細に依存しすぎて壊れやすい」という弱点を克服するため、アクセシビリティツリー(ARIAロールなど)を利用したセレクタを推奨しています。しかし、親要素を参照する必要がある場合など、特定のユースケースでは依然としてXPathが唯一の解となることがあります [50] 。
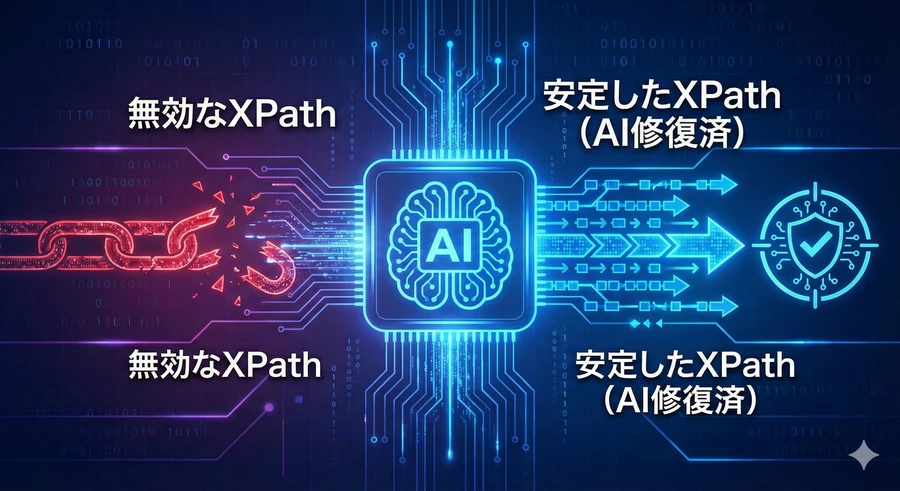
AIによる自動生成と自己修復(Self-Healing)
最新のトレンドは、AI(LLM)を用いたXPathの自動生成とメンテナンスです。
AI生成: 自然言語で「購入ボタンを取得して」と指示するだけで、AIが複雑なHTML構造を解析して最適なXPathを提案します [51] 。
セルフヒーリング: サイトのデザインが変わり、以前のXPathが使えなくなった際、AIが自動的に新しい経路を再計算してテストを継続する機能です。これにより、手動での修正コストが大幅に(最大95%)削減されるという報告もあります [52] 。
パフォーマンスと保守性のためのベストプラクティス
XPathは非常に強力ですが、乱用するとパフォーマンスの低下や保守性の悪化を招きます [53] 。
パフォーマンスの最適化
//(深層検索)の使用を抑える: ドキュメント全体を走査するため、要素数が多いページでは処理が重くなります。可能な限り、既知の親要素から検索を開始することが推奨されます [54] 。
IDを活用する: `//div[@id='header']//a` のように、最初に一意のIDで絞り込んでから階層を下ることで、効率的に要素を特定できます [55] 。
壊れにくいXPathの書き方
自動生成された `div/div/span` のようなインデックス依存のパスは避け、`contains()` や属性を組み合わせた意味的なパスを書くように心がけましょう [56] 。
悪い例: `/html/body/div/div/form/input`
良い例: `//form[@name='login']//input[@type='text']`
まとめ
XPathは、1990年代に誕生した技術でありながら、2025年現在もウェブの構造を読み解くための「共通言語」として確固たる地位を築いています [57] 。CSSセレクタのような簡潔さには欠けますが、その圧倒的な表現力は、複雑化する現代のウェブアプリケーションにおいて強力な武器となります [58] 。特に、近年普及しているAIによる自動生成技術との相性も良く、今後は「AIが生成し、人間が微調整する」という新しいスキルセットが重要になってくるでしょう [59] 。これからXPathを学ぶ皆さんは、まずはデベロッパーツールのコピー機能から始め、徐々に関数や軸を使いこなせるようになることで、データ抽出や自動化の可能性を大きく広げていくことができます。
参考資料
1. XPath - Wikipedia, https://en.wikipedia.org/wiki/XPath
2. document. evaluate & XPath - Can I use..., https://caniuse.com/#search=xpath
3. Browser support for XSLT and XPath 2.0/3.0, https://lwn.net/Articles/1034560/
4. Chromium Issues: Update XPATH from 1.0 to 3.1, https://issues.chromium.org/41300017
5. Which version of XPath does Firefox support?, https://superuser.com/questions/1092853/which-version-of-xpath-does-firefox-support
6. XPath Functions - MDN Web Docs, https://developer.mozilla.org/en-US/docs/Web/XML/XPath/Reference/Functions
7. Introduction to using XPath in JavaScript - MDN, https://developer.mozilla.org/en-US/docs/Web/XML/XPath/Guides/Introduction_to_using_XPath_in_JavaScript
8. XPath Snippets - MDN Web Docs, https://developer.mozilla.org/en-US/docs/Web/XML/XPath/Guides/Snippets
9. XPath - MDN Web Docs, https://developer.mozilla.org/en-US/docs/Web/XML/XPath
10. XPath Guides - MDN Web Docs, https://developer.mozilla.org/en-US/docs/Web/XML/XPath/Guides
11. Playwright vs Selenium 2025 Browser Automation Comparison, https://www.browserless.io/blog/playwright-vs-selenium-2025-browser-automation-comparison
12. Playwright or Puppeteer in 2025 - Reddit, https://www.reddit.com/r/webdev/comments/1nyo2mk/playwright_or_puppeteer_in_2025/
13. Selenium vs Playwright: Why Teams are Migrating in 2025, https://checksum.ai/blogs/selenium-vs-playwright-why-teams-are-migrating-in-2025
14. Puppeteer vs Playwright vs Selenium: Ultimate Comparison, https://iproyal.com/blog/puppeteer-vs-playwright-vs-selenium/
15. Choosing the Right E2E Testing Framework for 2025, https://medium.com/@lalatenduswain/cypress-selenium-playwright-puppeteer-choosing-the-right-e2e-testing-framework-for-your-web-5d142a18ca15
16. XPathの取得と使い方:デベロッパーツール, https://dx-pro.resocia.jp/rpa_column/008
17. XPathの動作結果を確認する方法 (Chrome版), https://gomobile.zendesk.com/hc/ja/articles/208785878-XPath%E3%81%AE%E5%8B%95%E4%BD%9C%E7%B5%90%E6%9E%9C%E3%82%92%E7%A2%BA%E8%AA%8D%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95-Chrome%E7%89%88
18. Xpathを検証する方法 - Qiita, https://qiita.com/m-kinjo/items/dad2b41efbb7259a9564
19. XPathの取得方法 - Qiita, https://qiita.com/yasuflatland-lf/items/78a0c2bdba78d064def4
20. XPathを表示させる方法 - Octoparse, https://www.octoparse.jp/blog/xpath-introduction
21. XPath Axes Explained with Examples, https://knowledge.curiosityworth.ie/docs/xpath-axes
22. XPath Axes in Selenium, https://www.scientecheasy.com/2019/08/xpath-axes.html/
23. XPath - Axes - Tutorialspoint, https://www.tutorialspoint.com/xpath/xpath_axes.htm
24. XPath:Axes Reference - MDN Web Docs, https://developer.mozilla.org/en-US/docs/Web/XML/XPath/Reference/Axes
25. XPath Axes Guide, https://jrebecchi.github.io/xpath-helper/xpath-axes.html
26. The Ultimate XPath Cheat Sheet, https://bugbug.io/blog/testing-frameworks/the-ultimate-xpath-cheat-sheet/
27. What is XPath Selector in Web Scraping?, https://www.firecrawl.dev/glossary/web-scraping-apis/what-is-xpath-selector-in-web-scraping
28. XPath Cheatsheet for Web Scraping, https://scrapfly.io/blog/posts/xpath-cheatsheet
29. Practical XPath for Web Scraping, https://www.scrapingbee.com/blog/practical-xpath-for-web-scraping/
30. XPath Cheatsheet for Octoparse, https://helpcenter.octoparse.com/en/articles/11659481-xpath-cheatsheet-for-web-scraping-with-octoparse
31. XPath vs CSS Selectors: Performance and Capability, https://iproyal.com/blog/xpath-vs-css-selectors/
32. XPath vs CSS Selector for Test Automation, https://bugbug.io/blog/test-automation/xpath-vs-css-selector/
33. XPath vs CSS Selectors: Which is Superior?, https://www.testmuai.com/blog/xpath-vs-css-selectors/
34. Comprehensive Guide for Web Automation: XPath vs CSS, https://rebrowser.net/blog/xpath-vs-css-selectors-a-comprehensive-guide-for-web-automation-and-testing
35. Comparison of CSS Selectors and XPath - MDN, https://developer.mozilla.org/en-US/docs/Web/XML/XPath/Guides/Comparison_with_CSS_selectors
36. W3C XPath Full Text 1.0 Recommendation, https://www.w3.org/TR/xpath-full-text-10/
37. XQuery and XPath Full Text 1.0 Requirements, https://www.w3.org/TR/xpath-full-text-10-requirements/
38. XPath Version 1.0 Publication History, https://www.w3.org/standards/history/xpath-10/
39. XML Path Language (XPath) Version 1.0 - W3C, https://www.w3.org/TR/1999/REC-xpath-19991116/
40. DOM Level 3 XPath References, https://www.w3.org/TR/DOM-Level-3-XPath/references.html
41. XPath 3.1 Conformance - Saxonica, https://www.saxonica.com/documentation10/index.html#!conformance/xpath31
42. XML Path Language (XPath) 3.1 - W3C, https://www.w3.org/TR/xpath-31/
43. XQuery and XPath Data Model 3.1 - W3C, https://www.w3.org/TR/xpath-datamodel-31/
44. XPath and XQuery Functions 3.1 - W3C, https://www.w3.org/TR/xpath-functions-31/
45. XQuery 3.1 Recommendation - W3C, https://www.w3.org/TR/xquery-31/
46. Introduction to using XPath in JavaScript - MDN, https://developer.mozilla.org/en-US/docs/Web/XML/XPath/Guides/Introduction_to_using_XPath_in_JavaScript
47. Document: evaluate() method - MDN, https://developer.mozilla.org/en-US/docs/Web/API/Document/evaluate
48. XPathResult: resultType property - MDN, https://developer.mozilla.org/en-US/docs/Web/API/XPathResult/resultType
49. Using XPath with JavaScript Tutorial, https://github.com/VolkanSah/JavaScript-XPath-Tutorial/blob/main/README.md
50. XPathResult Interface Documentation, https://llamalab.com/js/xpath/doc/logical/XPathResult.html
51. XPath translate() function - MDN, https://developer.mozilla.org/en-US/docs/Web/XML/XPath/Reference/Functions/translate
52. How to select elements by text in XPath, https://www.scrapingbee.com/webscraping-questions/xpath/how-to-select-elements-by-text-in-xpath/
53. XPath case-insensitive syntax discussion, https://forum.robotframework.org/t/xpath-insensitive-syntaxe/8412
54. Case insensitive xpaths in Selenium, https://groups.google.com/g/selenium-users/c/Lcvbjisk4qE
55. XPath normalize-space() function - MDN, https://developer.mozilla.org/en-US/docs/Web/XML/XPath/Reference/Functions/normalize-space
56. XPath Function Reference: normalize-space, https://www.data2type.de/en/xml-xslt-xslfo/xslt/xslt-xpath-function-reference/alphabetical-xslt-and-xpath-reference/normalize-space
57. Difference between dot (.) and text() in XPath, https://stackoverflow.com/questions/38240763/xpath-difference-between-dot-and-text
58. What is the difference between normalize-space() and normalize-space(text())?, https://stackoverflow.com/questions/5992177/what-is-the-difference-between-normalize-space-and-normalize-spacetext
59. Playwright Selectors Best Practices, https://www.browserstack.com/guide/playwright-selectors-best-practices
60. Comprehensive Guide for Web Automation: Performance, https://rebrowser.net/blog/xpath-vs-css-selectors-a-comprehensive-guide-for-web-automation-and-testing
61. Playwright Locators: A Comprehensive Guide, https://bugbug.io/blog/testing-frameworks/playwright-locators/
62. Playwright Best Practices: Testing Philosophy, https://playwright.dev/docs/best-practices
63. Mastering Playwright Locators for Reliable Tests, https://medium.com/@vohrakritika9/mastering-playwright-locators-the-complete-guide-to-writing-reliable-tests-87f1a06c411b
64. Chromium Security and Deprecation of XPath 1.0, https://groups.google.com/a/chromium.org/g/blink-dev/c/CxL4gYZeSJA/m/2vIj7qvjAwAJ
65. Browser Support 2025: Widely Available Features, https://www.caseywatts.com/blog/browser-support-2025/
66. What browsers support XPath 2.0?, https://stackoverflow.com/questions/16658799/what-browsers-support-xpath-2-0
67. Why modern browser engines do not support XPath 2.0?, https://stackoverflow.com/questions/65271107/why-modern-browser-engines-do-not-support-xpath-2-0
68. XPathとAIによる特定手法 - Zenn, https://zenn.dev/daishu/articles/f9372ca6f5e60f
69. XPathの基本的なルールと書き方 - Qbook, https://www.qbook.jp/column/2284.html
70. AI-Powered Web Scraping Solutions 2025, https://www.firecrawl.dev/blog/ai-powered-web-scraping-solutions-2025
71. Best Generative AI Tools for 2025, https://bootcamp.outreach.ou.edu/blog/best-generative-ai-tools
72. AI-Assisted XPath Code Generator, https://workik.com/xpath-code-generator
73. 20+ Best Generative AI Tools in 2025, https://latenode.com/blog/tools-software-reviews/best-ai-tools-2025/20-best-generative-ai-tools-in-2025
74. AI-Powered Selenium Testing Trends 2025, https://www.h2kinfosys.com/blog/ai-powered-selenium-testing-trends-2025/
75. Selenium vs Cypress vs Playwright vs AI - Reddit, https://www.reddit.com/r/webdev/comments/1pjvws3/compared_selenium_vs_cypress_vs_playwright_vs_ai/
76. Playwright vs Selenium vs AI-Native Testing, https://www.virtuosoqa.com/post/playwright-vs-selenium-vs-ai-native-testing
77. Playwright vs Selenium: Key Differences Explained, https://www.browserstack.com/guide/playwright-vs-selenium
78. Top Features of Playwright for Automation, https://thinksys.com/qa-testing/playwright-features/
79. Official Documentation for Selectors and XPath, https://rebrowser.net/blog/xpath-vs


コメント