

【2025年最新】BambooAIとは?使い方からPandasAIとの比較まで初心者向けに徹底解説のPodcast
下記のPodcastは、Geminiで作成しました。
ストーリーブック
はじめに:データ分析は「対話」の時代へ
データ分析と聞いて、どのようなイメージを思い浮かべるでしょうか。多くの人は、複雑なプログラミングコード、難解な統計理論、そして膨大な時間を要するデータの前処理などを想像するかもしれません 。これまで、データから価値ある洞察を引き出す作業は、専門的なスキルを持つデータサイエンティストやアナリストの専売特許でした。しかし、人工知能(AI)技術、特に大規模言語モデル(LLM)の進化が、この状況を根底から変えようとしています。
データ分析は、もはや一方的に命令を記述する作業ではありません。これからは、AIと「対話」しながら、必要な情報を引き出し、分析を進める時代です。この変革の最前線にいるのが、今回ご紹介するBambooAIです。BambooAIは、自然言語(私たちが日常的に使う言葉)で指示するだけで、データの分析、可視化、さらにはコードの自動生成まで行ってくれる画期的なPythonライブラリです 。

この記事では、2025年最新のBambooAIについて、その基本概念から内部の仕組み、具体的な使い方、さらには主要な競合ツールであるPandasAIとの比較まで、初心者の方にも分かりやすく、そして深く掘り下げて解説していきます。
第1章:BambooAIとは?データ探索を加速するAIアシスタント
BambooAIは、LLMを活用して対話形式でのデータ探索と分析を可能にする、オープンソースのPythonライブラリです 。その核となる目的は、プログラミングの専門知識が豊富でないユーザーでも、自然言語での対話を通じてデータと向き合い、必要な洞察を導き出せるようにすることにあります 。
BambooAIが目指すのは、単なるコード生成ツールではありません。データ分析のワークフロー全体を合理化し、あらゆるレベルのアナリストの能力を拡張する、インテリジェントなアシスタントとしての役割です。
そのために、以下のような強力な機能が備わっています 。
- 自然言語インターフェース: 「売上が最も高い商品は何?」「顧客セグメントごとに平均購入額をグラフで示して」といった平易な言葉でデータ分析を実行できます。
- 柔軟なデータソース対応: ローカルのCSVファイルやPandasのDataFrameはもちろん、必要に応じてインターネット検索を行い、外部のデータを取得して分析に組み込むことも可能です。
-
コードの自動生成と自己修復: 指示に基づいてPythonコード(主にPandasやMatplotlib/Plotlyを使用)を自動で生成し、実行します。さらに特筆すべきは、コードの実行中にエラーが発生した場合、
BambooAI自身がエラー内容をLLMに渡し、コードを修正して再試行する「自己修復(Self-healing)」機能を備えている点です。 - マルチエージェント・アーキテクチャ: 単一のAIが全てのタスクをこなすのではなく、それぞれ専門分野を持つ複数のAIエージェントが協調して動作します。これにより、複雑なタスクにも対応できる高い精度と柔軟性を実現しています。
- 継続的な学習: 成功した分析結果をベクトルデータベースに保存し、将来同様の質問があった際に参照することで、使えば使うほど賢くなる学習能力を持ちます。
これらの機能により、BambooAIはユーザーが「何をしたいか」に集中できる環境を提供し、データ分析のハードルを劇的に下げます。
第2章:知能の構造:BambooAIはどのように機能するのか
BambooAIの強さの秘密は、その洗練された内部アーキテクチャにあります。それはまるで、優秀な専門家チームが連携してプロジェクトを進めるかのような、体系的なプロセスに基づいています。このプロセスは、大きく6つのステップに分けることができます 。
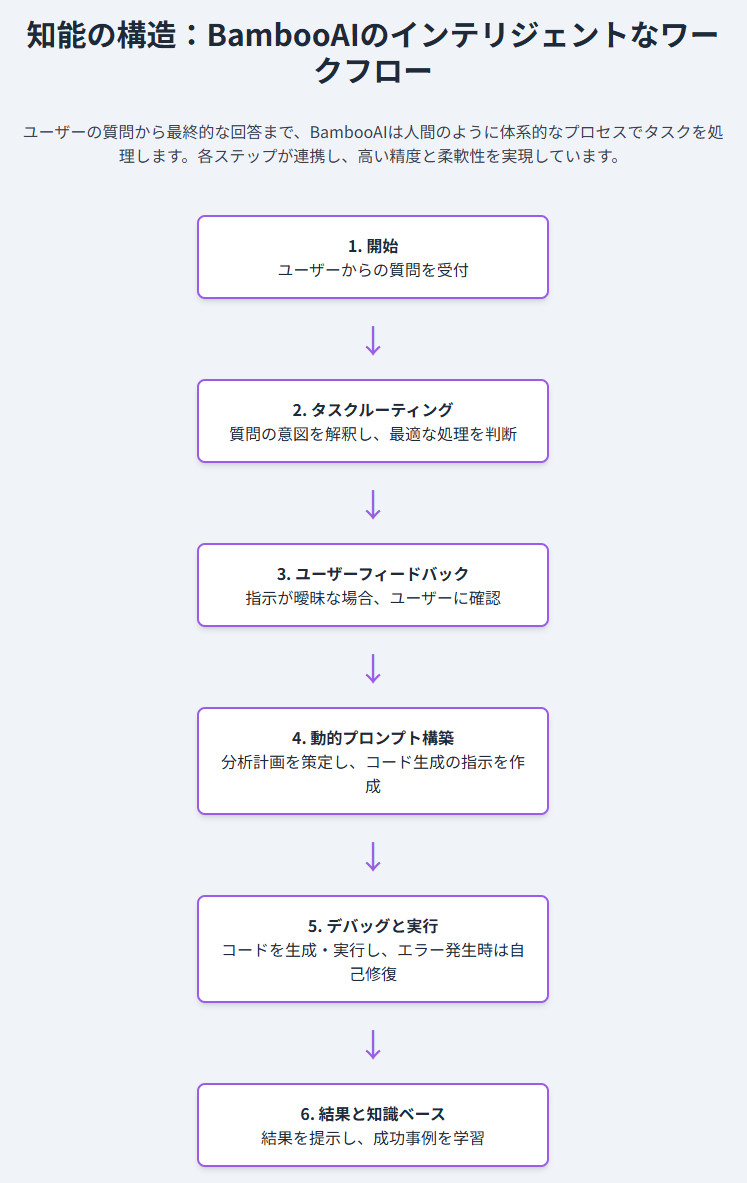
- 開始 (Initiation): ユーザーからの質問やプロンプトを受け取ることから対話ループが始まります。
- タスクルーティング (Task Routing): まず、最初のLLMがユーザーの質問の意図を解釈します。これは単純なテキストでの回答で十分か、それともコードを生成して分析を実行する必要があるかを見極める、いわば「受付係」の役割です。
-
ユーザーフィードバック (User Feedback): もしユーザーの指示が曖昧だったり、情報が不足していたりする場合、
BambooAIは処理を一時停止し、「この解釈で合っていますか?」といった形でユーザーに確認を求めます。この人間参加型(Human-in-the-Loop)の仕組みが、AIが誤った方向に進むのを防ぎ、最終的なアウトプットの質を保証します。 - 動的プロンプト構築 (Dynamic Prompt Build): コード生成が必要と判断されると、分析計画を策定します。過去の成功事例(ナレッジベース)を検索し、最適なアプローチを検討した上で、コード生成に特化したLLMへの詳細な指示(プロンプト)を組み立てます。
- デバッグと実行 (Debugging and Execution): 生成されたPythonコードを実行します。前述の通り、ここでエラーが発生しても諦めません。エラーメッセージを分析し、LLMベースの修正機能でデバッグを行い、成功するまで再試行します。
- 結果と知識ベース (Results and Knowledge Base): 最終的な分析結果やグラフをユーザーに提示します。同時に、その回答の品質を評価し、質の高いものは将来の参照のためにベクトルデータベースに知識として保存します。
この一連の流れを支えているのが、マルチエージェント・システムです 。
BambooAIは一枚岩のAIではなく、以下のような専門エージェントたちの集合体です。
- Expert Selector(専門家選定官): 質問内容に最適な専門家(リサーチ特化か分析特化か)を選びます。
- Planner(計画立案者): 複雑なタスクを具体的なステップに分解し、分析の全体計画を立てます。
- Code Generator(コード生成者): 計画に基づいてPythonコードを記述します。
- Error Corrector(エラー修正者): 発生したコードのエラーをデバッグし、修正案を提示します。
- Reviewer(レビュー担当者): 生成されたコードや計画の品質を評価し、必要に応じて修正を指示します。

このように、タスクを細分化し、各分野の専門エージェントに担当させることで、BambooAIは複雑で多段階の分析要求に対しても、人間のような体系的かつ堅牢な問題解決を実現しているのです。
第3章:BambooAIを使ってみよう:実践インストール&基本操作ガイド
この章では、実際にあなたの環境でBambooAIを動かすための手順を、ステップバイステップで丁寧に解説します。今回は、ローカル環境へのインストール方法に加え、もっとも手軽に試せるGoogle Colabを使った方法もご紹介します。
LLMには、OpenAIのモデルではなく、GoogleのGeminiを利用する手順で進めていきます。
準備するもの
- Python環境: PCにPythonがインストールされている必要があります。
- Google Gemini APIキー: BambooAIが思考のエンジンとして利用するLLMのためのキーです。Google AI for Developersのサイトから無料で取得できます。
1.Google Colabで試す(推奨)
環境構築が不要で、すぐに試せるGoogle Colabを使う方法が最も簡単です。
ステップ1: 新しいノートブックの作成
Google Colabにアクセスし、新しいノートブックを作成します。
ステップ2: ライブラリのインストール
最初のコードセルに、以下のコマンドを入力して実行してください。bambooaiと、Geminiを利用するために必要なGoogleのライブラリがインストールされます。
# BambooAIをインストール後、Colabの環境と競合しないようにPandasとNumpyのバージョンを再調整します
!pip install bambooai google-generativeai --upgrade
!pip install pandas==2.2.2 numpy==2.0.0 --force-reinstall
【超重要】 このセルを実行すると、たくさんの赤いエラーメッセージ(dependency conflicts)が表示されますが、これは想定内の動作なので無視してください。 最後に「セッションを再起動」というボタンが表示されたら、必ずクリックしてください。 これにより、インストールしたライブラリのバージョンが正しく反映されます。セッションが再起動されると、次のステップに進むことができます。
ステップ3: APIキーの設定
次に、取得したGeminiのAPIキーを設定します。左側のメニューにある鍵のアイコン(シフレーレット)をクリックし、「新しいシークレットを追加」を選択します。
-
名前:
GOOGLE_API_KEY - 値: あなたのGemini APIキーを貼り付け
入力したら、「ノートブックへのアクセスを有効にする」のトグルをONにしてください。これで、安全にAPIキーをコード内で利用できます。
ステップ4: BambooAIの初期化と実行
いよいよBambooAIを動かします。以下のコードを新しいセルに入力・実行してください。
import pandas as pd
from bambooai import BambooAI
from google.colab import userdata
import json
import os
# ColabのシークレットからAPIキーを読み込み、環境変数に設定
os.environ["GOOGLE_API_KEY"] = userdata.get('GOOGLE_API_KEY')
# 分析対象のデモデータを作成
sales_data = pd.DataFrame({
'Date': pd.to_datetime(['2025-01-01', '2025-01-01', '2025-01-02', '2025-01-02', '2025-01-03']),
'Product': ['Apple', 'Banana', 'Apple', 'Orange', 'Banana'],
'Sales': [100, 70, 120, 50, 80]
})
# LLMの設定 (JSON形式で各エージェントのモデルを指定)
# APIの無料利用枠制限を回避するため、高速なflashモデルを使用します
llm_config = {
"agent_configs": [
{
"agent": "Expert Selector",
"details": {
"model": "gemini-1.5-flash-latest",
"provider": "gemini",
"temperature": 0.0,
"max_tokens": 1024
}
},
{
"agent": "Analyst Selector",
"details": {
"model": "gemini-1.5-flash-latest",
"provider": "gemini",
"temperature": 0.0,
"max_tokens": 1024
}
},
{
"agent": "Planner",
"details": {
"model": "gemini-1.5-flash-latest",
"provider": "gemini",
"temperature": 0.0,
"max_tokens": 1024
}
},
{
"agent": "Code Generator",
"details": {
"model": "gemini-1.5-flash-latest",
"provider": "gemini",
"temperature": 0.0,
"max_tokens": 4096
}
},
{
"agent": "Error Corrector",
"details": {
"model": "gemini-1.5-flash-latest",
"provider": "gemini",
"temperature": 0.0,
"max_tokens": 2048
}
},
{
"agent": "Reviewer",
"details": {
"model": "gemini-1.5-flash-latest",
"provider": "gemini",
"temperature": 0.0,
"max_tokens": 1024
}
},
{
"agent": "Solution Summarizer",
"details": {
"model": "gemini-1.5-flash-latest",
"provider": "gemini",
"temperature": 0.0,
"max_tokens": 1024
}
}
],
"model_properties": {
"gemini-1.5-flash-latest": {
"capability": "base",
"multimodal": False,
"templ_formating": "text"
}
}
}
# 設定をLLM_CONFIG.jsonファイルとして保存
with open('LLM_CONFIG.json', 'w') as f:
json.dump(llm_config, f)
# BambooAIを初期化 (設定ファイルが自動で読み込まれます)
bamboo = BambooAI(df=sales_data)
# 対話を開始
print("BambooAIとの対話を開始します。'exit'と入力すると終了します。")
print("例: 最も売上が高かった商品は何ですか?")
bamboo.pd_agent_converse()
これを実行すると、入力欄が表示され、データについて自然言語で質問できるようになります。
質問の例:
-
最も売上が高かった商品は何ですか? -
日ごとの売上合計を計算して、グラフで表示してください。
2. ローカル環境にインストールして試す
ご自身のPCで本格的に利用したい場合は、以下の手順でインストールします。
-
ライブラリのインストール: ターミナル(またはコマンドプロンプト)を開き、
pipコマンドでインストールします。Bashpip install bambooai google-generativeai --upgrade -
APIキーの設定: 環境変数として
GOOGLE_API_KEYを設定します。 - Pythonスクリプトの作成: 上記のGoogle Colabのコード(ステップ4)と同様のPythonスクリプトを作成し、実行します。
どちらの方法でも、簡単な設定ですぐにBambooAIとの「データとの対話」を始めることができます。ぜひ、あなた自身が持っているデータで試してみてくださいね。
第4章:BambooAIを使いこなす:高度な機能と設定オプション
基本的な使い方をマスターしたら、次はBambooAIの真価を引き出す高度な機能を活用してみましょう。これらの機能は、BambooAIを初期化する際のパラメータで有効にできます 。
-
planning=True: 「Aを分析し、その結果を使ってBを計算し、最後にCと比較して」といった複雑な要求に対して、BambooAIはまず論理的な分析計画を立てます。この計画段階を経ることで、最終的なコードの品質とタスクの成功率が劇的に向上します 。 -
vector_db=True: これを有効にすると、BambooAIは単なる一問一答のツールから、「学習するエージェント」へと進化します。質の高い分析が成功すると、その「意図」と「解決策」が記憶されます。次回、似たような質問が来た際には、過去の成功体験を参考にすることで、より迅速かつ正確な回答を生成できます 。 -
df_ontology=True: これはBambooAIに専門知識を与えるようなものです。例えば、医療データで「TNM分類」というカラムがあった場合、オントロジーファイルで「Tは腫瘍の大きさ、Nはリンパ節転移、Mは遠隔転移を示す」と定義しておくことで、AIは単なる文字列としてではなく、その意味を理解した上で分析を行えるようになります。これにより、分析の精度が飛躍的に向上します 。
これらの高度な機能を組み合わせることで、BambooAIを特定の業務ドメインに特化した、強力なカスタム分析アシスタントとして育て上げることが可能です。
第5章:エコシステム比較:BambooAI vs. PandasAI
BambooAIと同様の目的を持つライブラリとして、最も有名なのがPandasAIです 。どちらも自然言語でデータ分析を行うための強力なツールですが、その設計思想とアーキテクチャには興味深い違いがあります。
| 特徴/観点 | BambooAI | PandasAI |
| コア・アーキテクチャ | 専門家チームのように協調動作するマルチエージェント・システム 。 | 自然言語インターフェースを主軸とし、データ準備のためのセマンティックレイヤーを持つ 。 |
| 主要な目的 | 複雑なタスクの解決と、学習による継続的な改善能力の提供。 | コーディングの複雑さを排除し、直感的な対話によるデータ分析の民主化 。 |
| 複雑なクエリへの対応 | Plannerエージェントが明示的に多段階の計画を立案し、堅牢に対応 。 | 主にLLMの直接的な能力に依存するが、セマンティックレイヤーでデータ関係を定義可能 。 |
| 長期記憶と学習 | ベクトルDB(エピソード記憶)による成功事例の学習機能が組み込まれている 。 | train()メソッドによるQ&A形式のカスタム学習が可能だが、アーキテクチャの主軸ではない。 |
| 文脈理解 | オントロジー(意味記憶)を導入することで、ドメイン固有の深い文脈理解を追求 。 | データスキーマにメタデータを追加することで文脈を付与するアプローチ 。 |
| 設定とカスタマイズ | LLM_CONFIG.jsonにより、エージェントごとにLLMを細かく設定可能で、高いカスタマイズ性を持つ 。 | よりシンプルな設定で始めやすいが、内部アーキテクチャのカスタマイズ性は限定的。 |
| 理想的なユーザー | 複雑な分析や、特定のドメインに特化した学習型エージェントを構築したい中〜上級者。 | データ分析の初学者や、手軽に単一データフレームに対する対話的分析を始めたいユーザー 。 |
この比較から見えてくるのは、両者の立ち位置の違いです。PandasAIは、データ分析の入り口を広げ、誰でも簡単に自然言語でデータと対話できるようにすることに重きを置いています。一方、BambooAIは、その一歩先を見据え、自律的に計画を立て、エラーを修正し、過去の経験から学習する、より高度で自律的な「AIエージェント」の構築を目指していると言えるでしょう。

どちらか一方が優れているというわけではなく、プロジェクトの目的やユーザーのスキルレベルに応じて最適なツールを選択することが重要です。手軽に始めたいならPandasAI、高度なカスタマイズと複雑なタスクへの対応を求めるならBambooAIが有力な選択肢となります。
第6章:バランスの取れた視点:BambooAIの長所と短所
BambooAIは非常に強力なツールですが、万能ではありません。導入を検討する際には、その長所と短所の両方を理解しておくことが重要です。

長所 (Pros)
- アクセシビリティの向上: コーディングスキルが高くないビジネスアナリストや研究者でも、高度なデータ分析を実行できるようになります。
- 生産性の飛躍的向上: コードの記述、デバッグ、グラフ作成といった時間のかかる作業を自動化し、分析者は「何を分析するか」という本質的な問いに集中できます。
- 高い柔軟性と拡張性: マルチエージェント・システムと詳細な設定オプションにより、特定のニーズに合わせて動作を細かくカスタマイズできます。
- 自律的な問題解決能力: インターネット検索や自己修復機能により、人間の介入を最小限に抑えながら、自律的にタスクを遂行する能力を持っています。
短所 (Cons)
-
LLMへの依存:
BambooAIの性能は、その背後で動作するLLMの能力に根本的に依存します。LLMが不得意なタスクや、誤った情報を生成(ハルシネーション)するリスクは常に存在します。 - 結果の検証が必要: 自動化された分析は非常に便利ですが、その結果が常に正しいとは限りません。最終的な意思決定に利用する前には、必ず人間による結果の検証と批判的な吟味が不可欠です。
- プライバシーの懸念: 外部のAPI(OpenAIなど)を利用する場合、分析対象のデータ(ヘッダー情報など)が外部に送信される可能性があります。機密性の高いデータを扱う際には、データの取り扱いやプライバシーポリシーを慎重に確認する必要があります。
-
セットアップの複雑さ:
PandasAIのような他のツールと比較して、APIキーの設定やLLM_CONFIG.jsonの準備など、初期設定がやや煩雑に感じられる場合があります。
これらの短所はBambooAI固有の欠陥というよりは、現在のLLMベースのAIエージェントシステムが共通して抱える課題です。これらのツールを「魔法の杖」ではなく、あくまで「強力なアシスタント」と捉え、その能力と限界を理解した上で活用することが、成功の鍵となります。
結論:データとの対話が拓く未来
BambooAIは、単に自然言語をコードに変換するツールではありません。それは、計画を立て、エラーから学び、知識を蓄積する、洗練されたAIアシスタントです。私たちのデータとの関わり方を、命令的な「プログラミング」から、協調的な「対話」へと変える可能性を秘めています。
特に、BambooAIが輝くのは、以下のようなシナリオでしょう。
- 迅速なデータ探索とプロトタイピング: アイデアを即座に形にし、試行錯誤のサイクルを高速化したい場合。
- ビジネス部門のエンパワーメント: エンジニアの手を借りずに、ビジネスアナリスト自身がデータから洞察を得たい場合。
- 複雑で曖昧な分析タスク: 明確な手順が決まっていない、探索的な分析を行いたい場合。
- ドメイン特化型システムの構築: 特定の業務知識を学習させ、長期的に成長する分析エージェントを育てたい場合。
データサイエンスの世界における対話型AIの旅はまだ始まったばかりです。BambooAIは、その未来への大きな一歩を示しています。データに基づいた意思決定が、一部の専門家だけでなく、組織のあらゆる人々にとって当たり前になる。そんな未来が、もうすぐそこまで来ています。
参考資料
- BambooAI GitHub Repository, https://github.com/pgalko/BambooAI
- BambooAI: Your AI-Powered Data Analysis Assistant, https://aiagentslist.com/agent/bambooai
- BambooAI on PyPI, https://pypi.org/project/bambooai/
- BambooAI Agent Review, https://metaschool.so/ai-agents/bambooai
- PandasAI Documentation, https://docs.pandas-ai.com/


コメント